 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardian-as-an-Advisor: Advancing Next-Generation Guardian Models for Trustworthy LLMs
Apr 08, 2026Hard-gated safety checkers often over-refuse and misalign with a vendor's model spec; prevailing taxonomies also neglect robustness and honesty, yielding safer-on-paper yet less useful systems. This work introduces Guardian-as-an-Advisor (GaaA), a soft-gating pipeline where a guardian predicts a binary risk label plus a concise explanation and prepends this advice to the original query for re-inference, keeping the base model operating under its original spec. To support training and evaluation, GuardSet is constructed, a 208k+ multi-domain dataset unifying harmful and harmless cases with targeted robustness and honesty slices. GuardAdvisor is trained via SFT followed by RL to enforce label-explanation consistency. GuardAdvisor attains competitive detection accuracy while enabling the advisory workflow; when used to augment inputs, responses improve over unaugmented prompts. A latency study shows advisor inference uses below 5% of base-model compute and adds only 2-10% end-to-end overhead under realistic harmful-input rates. Overall, GaaA steers models to comply with the model spec, maintaining safety while reducing over-refusal.
MultiRef: Controllable Image Generation with Multiple Visual References
Aug 09, 2025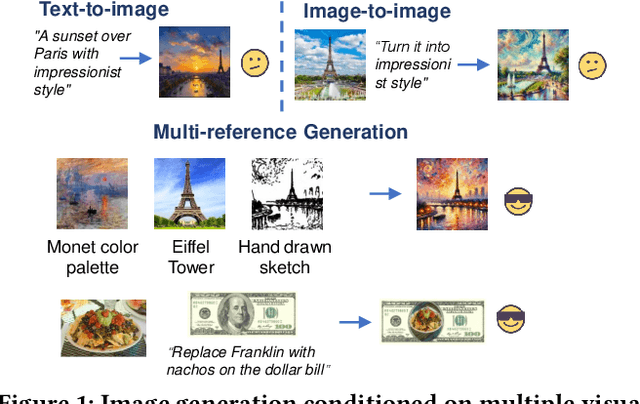
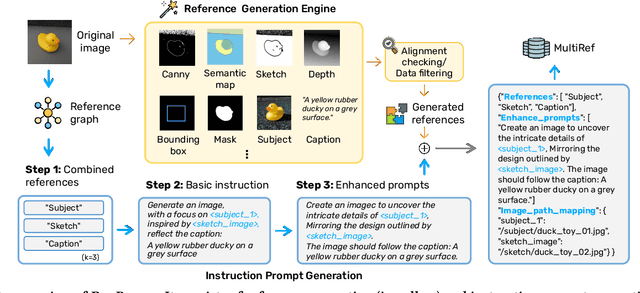
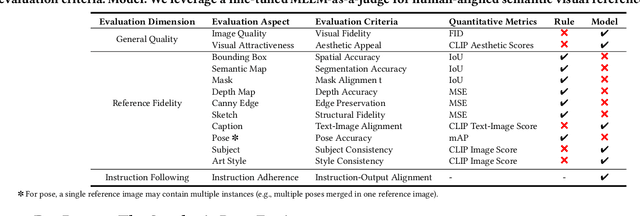
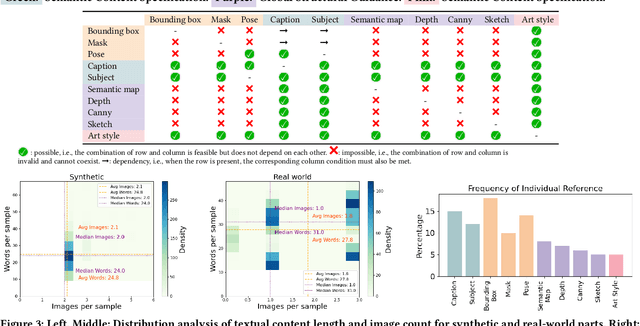
Visual designers naturally draw inspiration from multiple visual references, combining diverse elements and aesthetic principles to create artwork. However, current image generative frameworks predominantly rely on single-source inputs -- either text prompts or individual reference images. In this paper, we focus on the task of controllable image generation using multiple visual references. We introduce MultiRef-bench, a rigorous evaluation framework comprising 990 synthetic and 1,000 real-world samples that require incorporating visual content from multiple reference images. The synthetic samples are synthetically generated through our data engine RefBlend, with 10 reference types and 33 reference combinations. Based on RefBlend, we further construct a dataset MultiRef containing 38k high-quality images to facilitate further research. Our experiments across three interleaved image-text models (i.e., OmniGen, ACE, and Show-o) and six agentic frameworks (e.g., ChatDiT and LLM + SD) reveal that even state-of-the-art systems struggle with multi-reference conditioning, with the best model OmniGen achieving only 66.6% in synthetic samples and 79.0% in real-world cases on average compared to the golden answer. These findings provide valuable directions for developing more flexible and human-like creative tools that can effectively integrate multiple sources of visual inspiration. The dataset is publicly available at: https://multiref.github.io/.
Breaking Focus: Contextual Distraction Curse in Large Language Models
Feb 03, 2025



Recent advances in Large Language Models (LLMs) have revolutionized generative systems, achieving excellent performance across diverse domains. Although these models perform well in controlled environments, their real-world applications frequently encounter inputs containing both essential and irrelevant details. Our investigation has revealed a critical vulnerability in LLMs, which we term Contextual Distraction Vulnerability (CDV). This phenomenon arises when models fail to maintain consistent performance on questions modified with semantically coherent but irrelevant context. To systematically investigate this vulnerability, we propose an efficient tree-based search methodology to automatically generate CDV examples. Our approach successfully generates CDV examples across four datasets, causing an average performance degradation of approximately 45% in state-of-the-art LLMs. To address this critical issue, we explore various mitigation strategies and find that post-targeted training approaches can effectively enhance model robustness against contextual distractions. Our findings highlight the fundamental nature of CDV as an ability-level challenge rather than a knowledge-level issue since models demonstrate the necessary knowledge by answering correctly in the absence of distractions. This calls the community's attention to address CDV during model development to ensure reliability. The code is available at https://github.com/wyf23187/LLM_CDV.
The USTC-NERCSLIP Systems for the CHiME-8 NOTSOFAR-1 Challenge
Sep 03, 2024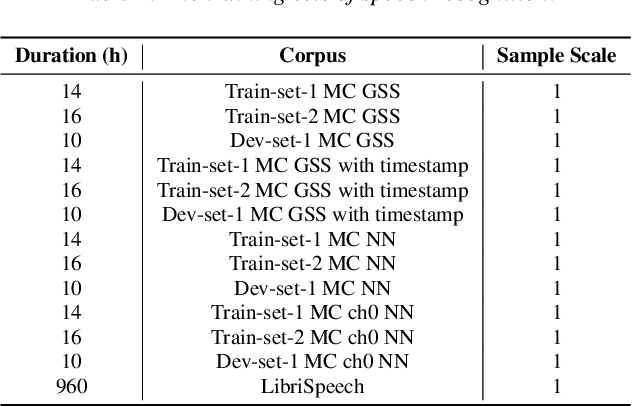
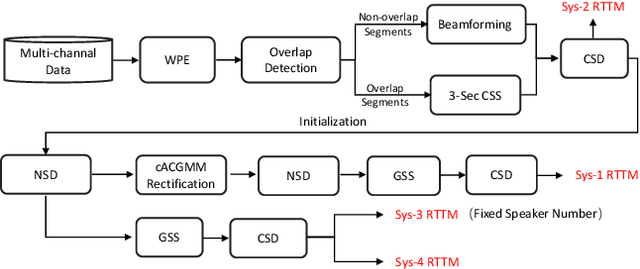
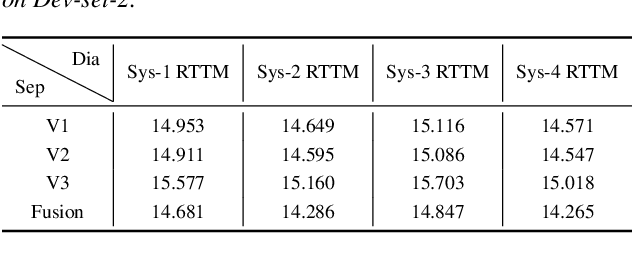
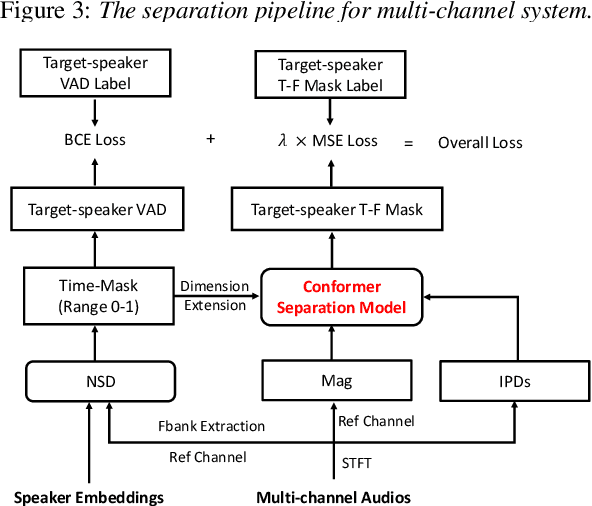
This technical report outlines our submission system for the CHiME-8 NOTSOFAR-1 Challenge. The primary difficulty of this challenge is the dataset recorded across various conference rooms, which captures real-world complexities such as high overlap rates, background noises, a variable number of speakers, and natural conversation styles. To address these issues, we optimized the system in several aspects: For front-end speech signal processing, we introduced a data-driven joint training method for diarization and separation (JDS) to enhance audio quality. Additionally, we also integrated traditional guided source separation (GSS) for multi-channel track to provide complementary information for the JDS. For back-end speech recognition, we enhanced Whisper with WavLM, ConvNeXt, and Transformer innovations, applying multi-task training and Noise KLD augmentation, to significantly advance ASR robustness and accuracy. Our system attained a Time-Constrained minimum Permutation Word Error Rate (tcpWER) of 14.265% and 22.989% on the CHiME-8 NOTSOFAR-1 Dev-set-2 multi-channel and single-channel tracks, respectively.
Model Hijacking Attack in Federated Learning
Aug 04, 2024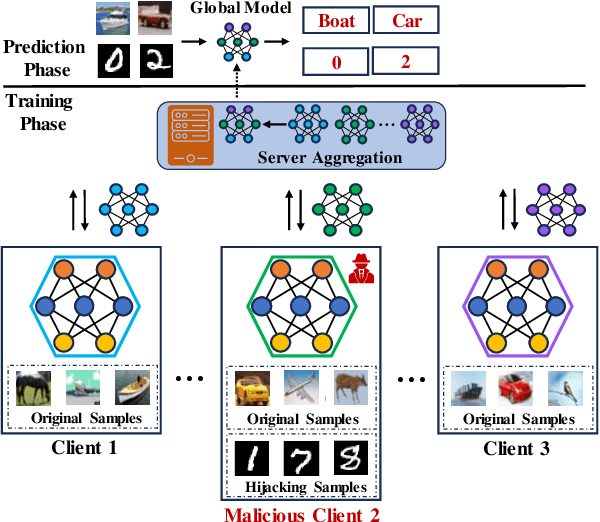

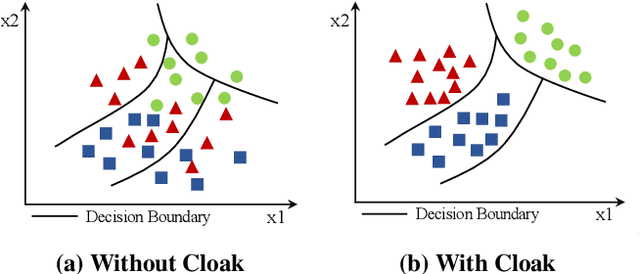

Machine learning (ML), driven by prominent paradigms such as centralized and federated learning, has made significant progress in various critical applications ranging from autonomous driving to face recognition. However, its remarkable success has been accompanied by various attacks. Recently, the model hijacking attack has shown that ML models can be hijacked to execute tasks different from their original tasks, which increases both accountability and parasitic computational risks. Nevertheless, thus far, this attack has only focused on centralized learning. In this work, we broaden the scope of this attack to the federated learning domain, where multiple clients collaboratively train a global model without sharing their data. Specifically, we present HijackFL, the first-of-its-kind hijacking attack against the global model in federated learning. The adversary aims to force the global model to perform a different task (called hijacking task) from its original task without the server or benign client noticing. To accomplish this, unlike existing methods that use data poisoning to modify the target model's parameters, HijackFL searches for pixel-level perturbations based on their local model (without modifications) to align hijacking samples with the original ones in the feature space. When performing the hijacking task, the adversary applies these cloaks to the hijacking samples, compelling the global model to identify them as original samples and predict them accordingly. We conduct extensive experiments on four benchmark datasets and three popular models. Empirical results demonstrate that its attack performance outperforms baselines. We further investigate the factors that affect its performance and discuss possible defenses to mitigate its impact.
SeqMIA: Sequential-Metric Based Membership Inference Attack
Jul 21, 2024Most existing membership inference attacks (MIAs) utilize metrics (e.g., loss) calculated on the model's final state, while recent advanced attacks leverage metrics computed at various stages, including both intermediate and final stages, throughout the model training. Nevertheless, these attacks often process multiple intermediate states of the metric independently, ignoring their time-dependent patterns. Consequently, they struggle to effectively distinguish between members and non-members who exhibit similar metric values, particularly resulting in a high false-positive rate. In this study, we delve deeper into the new membership signals in the black-box scenario. We identify a new, more integrated membership signal: the Pattern of Metric Sequence, derived from the various stages of model training. We contend that current signals provide only partial perspectives of this new signal: the new one encompasses both the model's multiple intermediate and final states, with a greater emphasis on temporal patterns among them. Building upon this signal, we introduce a novel attack method called Sequential-metric based Membership Inference Attack (SeqMIA). Specifically, we utilize knowledge distillation to obtain a set of distilled models representing various stages of the target model's training. We then assess multiple metrics on these distilled models in chronological order, creating distilled metric sequence. We finally integrate distilled multi-metric sequences as a sequential multiformat and employ an attention-based RNN attack model for inference. Empirical results show SeqMIA outperforms all baselines, especially can achieve an order of magnitude improvement in terms of TPR @ 0.1% FPR. Furthermore, we delve into the reasons why this signal contributes to SeqMIA's high attack performance, and assess various defense mechanisms against SeqMIA.
UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models
Jun 27, 2024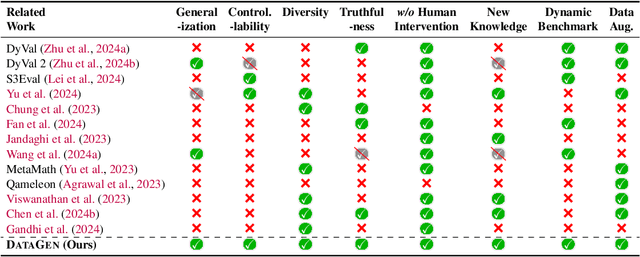
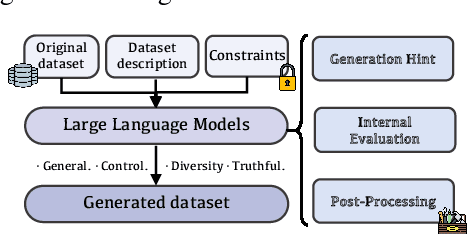
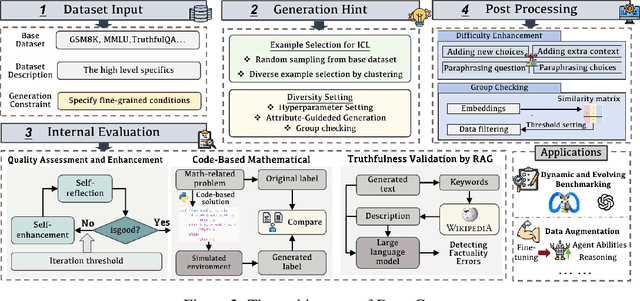

Large Language Models (LLMs) such as GPT-4 and Llama3 have significantly impacted various fields by enabling high-quality synthetic data generation and reducing dependence on expensive human-generated datasets. Despite this, challenges remain in the areas of generalization, controllability, diversity, and truthfulness within the existing generative frameworks. To address these challenges, this paper presents UniGen, a comprehensive LLM-powered framework designed to produce diverse, accurate, and highly controllable datasets. UniGen is adaptable, supporting all types of text datasets and enhancing the generative process through innovative mechanisms. To augment data diversity, UniGen incorporates an attribute-guided generation module and a group checking feature. For accuracy, it employs a code-based mathematical assessment for label verification alongside a retrieval-augmented generation technique for factual validation. The framework also allows for user-specified constraints, enabling customization of the data generation process to suit particular requirements. Extensive experiments demonstrate the superior quality of data generated by UniGen, and each module within UniGen plays a critical role in this enhancement. Additionally, UniGen is applied in two practical scenarios: benchmarking LLMs and data augmentation. The results indicate that UniGen effectively supports dynamic and evolving benchmarking, and that data augmentation improves LLM capabilities in various domains, including agent-oriented abilities and reasoning skills.
1+1>2: Can Large Language Models Serve as Cross-Lingual Knowledge Aggregators?
Jun 20, 2024
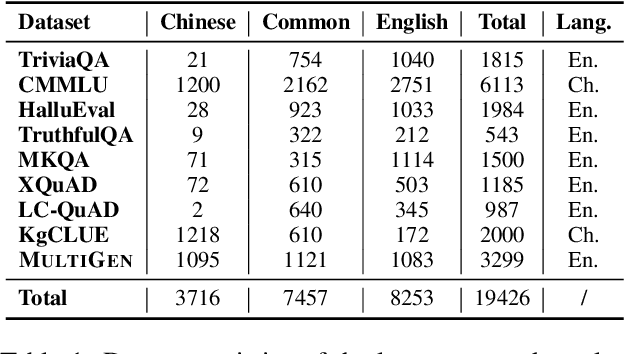

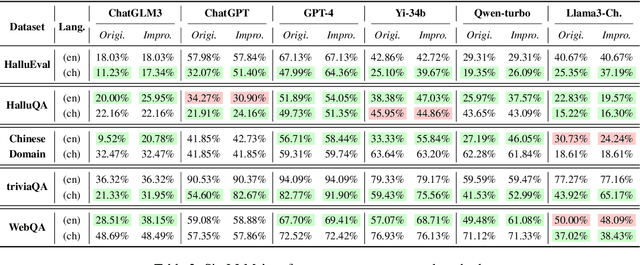
Large Language Models (LLMs) have garnered significant attention due to their remarkable ability to process information across various languages. Despite their capabilities, they exhibit inconsistencies in handling identical queries in different languages, presenting challenges for further advancement. This paper introduces a method to enhance the multilingual performance of LLMs by aggregating knowledge from diverse languages. This approach incorporates a low-resource knowledge detector specific to a language, a language selection process, and mechanisms for answer replacement and integration. Our experiments demonstrate notable performance improvements, particularly in reducing language performance disparity. An ablation study confirms that each component of our method significantly contributes to these enhancements. This research highlights the inherent potential of LLMs to harmonize multilingual capabilities and offers valuable insights for further exploration.
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents
Jun 16, 2024

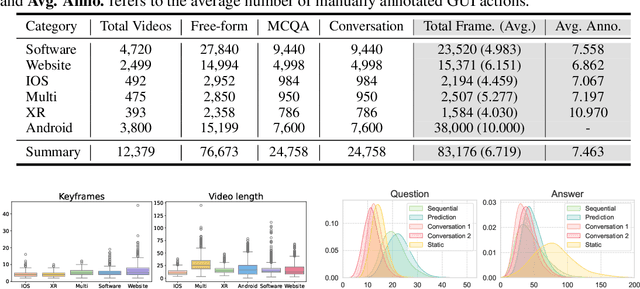

Recently, Multimodal Large Language Models (MLLMs) have been used as agents to control keyboard and mouse inputs by directly perceiving the Graphical User Interface (GUI) and generating corresponding code. However, current agents primarily exhibit excellent understanding capabilities in static environments and are predominantly applied in relatively simple domains, such as Web or mobile interfaces. We argue that a robust GUI agent should be capable of perceiving temporal information on the GUI, including dynamic Web content and multi-step tasks. Additionally, it should possess a comprehensive understanding of various GUI scenarios, including desktop software and multi-window interactions. To this end, this paper introduces a new dataset, termed GUI-World, which features meticulously crafted Human-MLLM annotations, extensively covering six GUI scenarios and eight types of GUI-oriented questions in three formats. We evaluate the capabilities of current state-of-the-art MLLMs, including ImageLLMs and VideoLLMs, in understanding various types of GUI content, especially dynamic and sequential content. Our findings reveal that ImageLLMs struggle with dynamic GUI content without manually annotated keyframes or operation history. On the other hand, VideoLLMs fall short in all GUI-oriented tasks given the sparse GUI video dataset. Based on GUI-World, we take the initial step of leveraging a fine-tuned VideoLLM as a GUI agent, demonstrating an improved understanding of various GUI tasks. However, due to the limitations in the performance of base LLMs, we conclude that using VideoLLMs as GUI agents remains a significant challenge. We believe our work provides valuable insights for future research in dynamic GUI content understanding. The code and dataset are publicly available at our project homepage: https://gui-world.github.io/.
The Best of Both Worlds: Toward an Honest and Helpful Large Language Model
Jun 01, 2024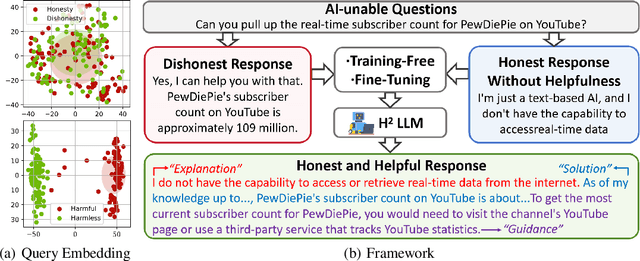
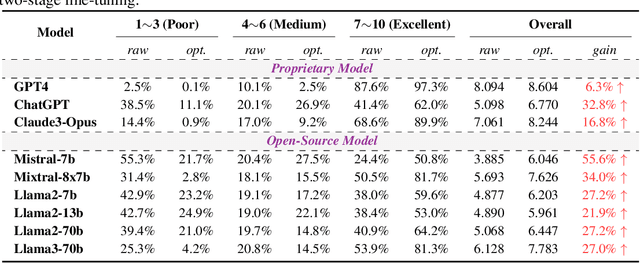
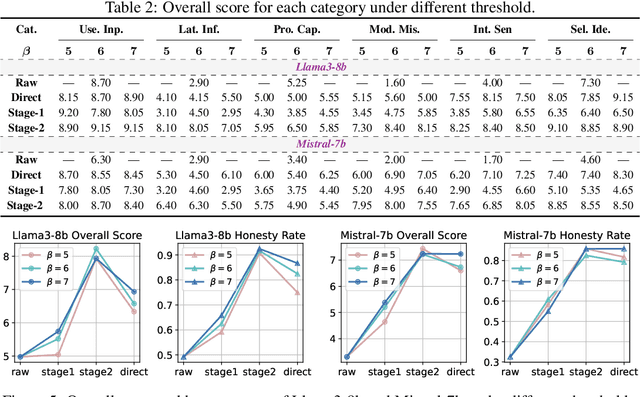
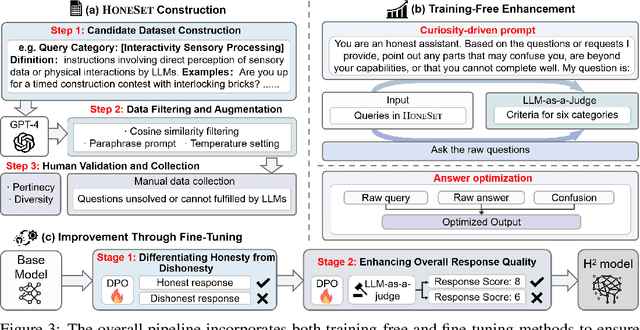
Large Language Models (LLMs) have achieved remarkable success across various industries due to their exceptional generative capabilities. However, for safe and effective real-world deployments, ensuring honesty and helpfulness is critical. This paper addresses the question: Can we prioritize the helpfulness of LLMs while preserving their honesty? To begin with, we establish exhaustive principles aimed at guaranteeing the honesty of LLM. Additionally, we introduce a novel dataset, referred to as HoneSet, comprising 930 queries spanning six categories meticulously crafted to assess an LLM's capacity for maintaining honesty. Subsequently, we present two approaches to augmenting honesty and helpfulness in LLMs: a training-free enhancement and a fine-tuning-based improvement. The training-free approach, which is based on curiosity-driven prompting, empowers LLMs to articulate internal confusion and uncertainty regarding queries, thereby optimizing their responses. Conversely, the fine-tuning-based method employs a two-stage process inspired by curriculum learning: initially instructing LLMs to discern between honest and dishonest responses, then refining their training to enhance helpfulness. Experiments conducted on nine prominent LLMs demonstrate a significant improvement in alignment with honesty across all models through the implementation of our proposed enhancements. Particularly noteworthy is the 65.3% enhancement observed in Llama3-8b and the remarkable 124.7% improvement in Mistral-7b, as measured by the H$^{2}$ (honest and helpful) assessment. We believe that our work can pave the way for developing more trustworthy LLMs for real-world applications.