 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Hijacking Attack in Federated Learning
Aug 04, 2024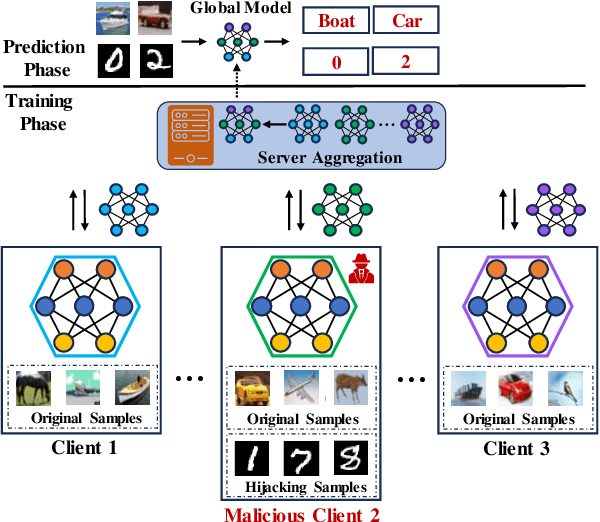

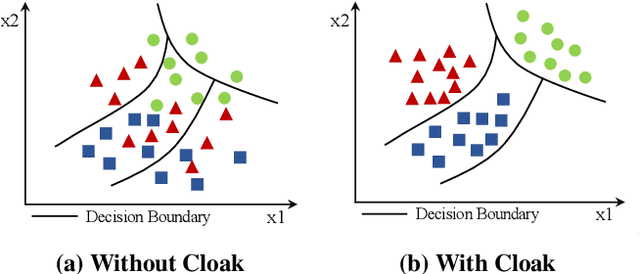

Machine learning (ML), driven by prominent paradigms such as centralized and federated learning, has made significant progress in various critical applications ranging from autonomous driving to face recognition. However, its remarkable success has been accompanied by various attacks. Recently, the model hijacking attack has shown that ML models can be hijacked to execute tasks different from their original tasks, which increases both accountability and parasitic computational risks. Nevertheless, thus far, this attack has only focused on centralized learning. In this work, we broaden the scope of this attack to the federated learning domain, where multiple clients collaboratively train a global model without sharing their data. Specifically, we present HijackFL, the first-of-its-kind hijacking attack against the global model in federated learning. The adversary aims to force the global model to perform a different task (called hijacking task) from its original task without the server or benign client noticing. To accomplish this, unlike existing methods that use data poisoning to modify the target model's parameters, HijackFL searches for pixel-level perturbations based on their local model (without modifications) to align hijacking samples with the original ones in the feature space. When performing the hijacking task, the adversary applies these cloaks to the hijacking samples, compelling the global model to identify them as original samples and predict them accordingly. We conduct extensive experiments on four benchmark datasets and three popular models. Empirical results demonstrate that its attack performance outperforms baselines. We further investigate the factors that affect its performance and discuss possible defenses to mitigate its impact.