 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Confidentiality, Privacy and Integrity in Collaborative Learning
Dec 11, 2024



A collaboration between dataset owners and model owners is needed to facilitate effective machine learning (ML) training. During this collaboration, however, dataset owners and model owners want to protect the confidentiality of their respective assets (i.e., datasets, models and training code), with the dataset owners also caring about the privacy of individual users whose data is in their datasets. Existing solutions either provide limited confidentiality for models and training code, or suffer from privacy issues due to collusion. We present Citadel++, a scalable collaborative ML training system designed to simultaneously protect the confidentiality of datasets, models and training code, as well as the privacy of individual users. Citadel++ enhances differential privacy techniques to safeguard the privacy of individual user data while maintaining model utility. By employing Virtual Machine-level Trusted Execution Environments (TEEs) and improved integrity protection techniques through various OS-level mechanisms, Citadel++ effectively preserves the confidentiality of datasets, models and training code, and enforces our privacy mechanisms even when the models and training code have been maliciously designed. Our experiments show that Citadel++ provides privacy, model utility and performance while adhering to confidentiality and privacy requirements of dataset owners and model owners, outperforming the state-of-the-art privacy-preserving training systems by up to 543x on CPU and 113x on GPU TEEs.
Model Hijacking Attack in Federated Learning
Aug 04, 2024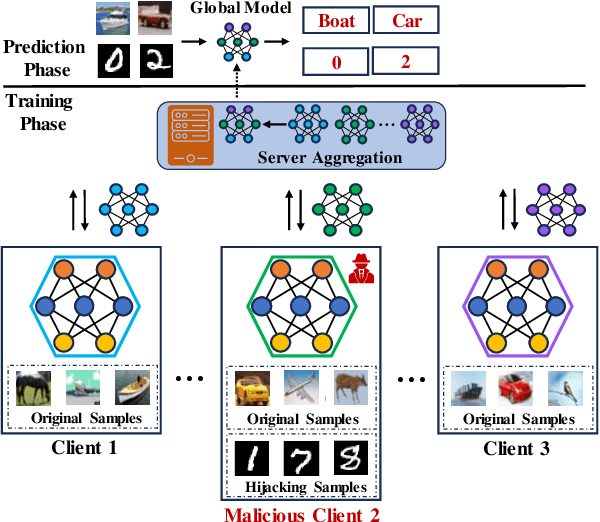

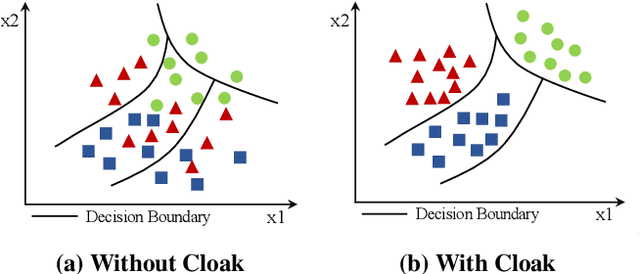

Machine learning (ML), driven by prominent paradigms such as centralized and federated learning, has made significant progress in various critical applications ranging from autonomous driving to face recognition. However, its remarkable success has been accompanied by various attacks. Recently, the model hijacking attack has shown that ML models can be hijacked to execute tasks different from their original tasks, which increases both accountability and parasitic computational risks. Nevertheless, thus far, this attack has only focused on centralized learning. In this work, we broaden the scope of this attack to the federated learning domain, where multiple clients collaboratively train a global model without sharing their data. Specifically, we present HijackFL, the first-of-its-kind hijacking attack against the global model in federated learning. The adversary aims to force the global model to perform a different task (called hijacking task) from its original task without the server or benign client noticing. To accomplish this, unlike existing methods that use data poisoning to modify the target model's parameters, HijackFL searches for pixel-level perturbations based on their local model (without modifications) to align hijacking samples with the original ones in the feature space. When performing the hijacking task, the adversary applies these cloaks to the hijacking samples, compelling the global model to identify them as original samples and predict them accordingly. We conduct extensive experiments on four benchmark datasets and three popular models. Empirical results demonstrate that its attack performance outperforms baselines. We further investigate the factors that affect its performance and discuss possible defenses to mitigate its impact.
SMLT: A Serverless Framework for Scalable and Adaptive Machine Learning Design and Training
May 04, 2022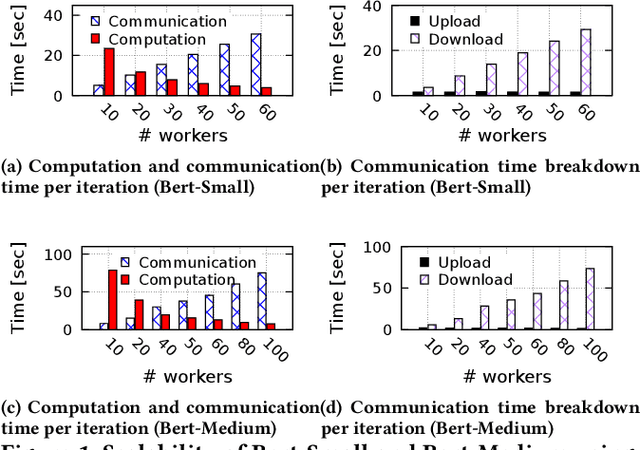

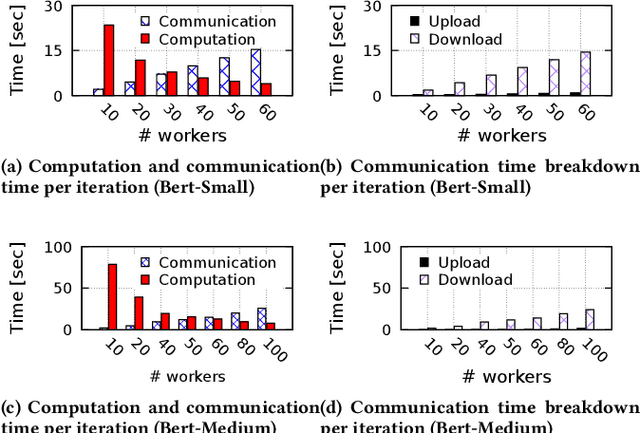
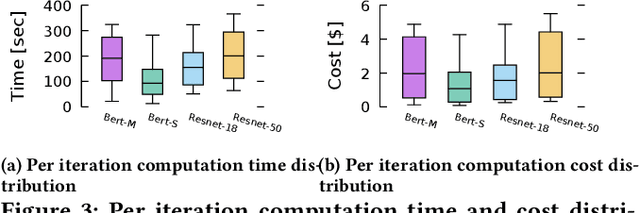
In today's production machine learning (ML) systems, models are continuously trained, improved, and deployed. ML design and training are becoming a continuous workflow of various tasks that have dynamic resource demands. Serverless computing is an emerging cloud paradigm that provides transparent resource management and scaling for users and has the potential to revolutionize the routine of ML design and training. However, hosting modern ML workflows on existing serverless platforms has non-trivial challenges due to their intrinsic design limitations such as stateless nature, limited communication support across function instances, and limited function execution duration. These limitations result in a lack of an overarching view and adaptation mechanism for training dynamics and an amplification of existing problems in ML workflows. To address the above challenges, we propose SMLT, an automated, scalable, and adaptive serverless framework to enable efficient and user-centric ML design and training. SMLT employs an automated and adaptive scheduling mechanism to dynamically optimize the deployment and resource scaling for ML tasks during training. SMLT further enables user-centric ML workflow execution by supporting user-specified training deadlines and budget limits. In addition, by providing an end-to-end design, SMLT solves the intrinsic problems in serverless platforms such as the communication overhead, limited function execution duration, need for repeated initialization, and also provides explicit fault tolerance for ML training. SMLT is open-sourced and compatible with all major ML frameworks. Our experimental evaluation with large, sophisticated modern ML models demonstrate that SMLT outperforms the state-of-the-art VM based systems and existing serverless ML training frameworks in both training speed (up to 8X) and monetary cost (up to 3X)
Citadel: Protecting Data Privacy and Model Confidentiality for Collaborative Learning with SGX
May 04, 2021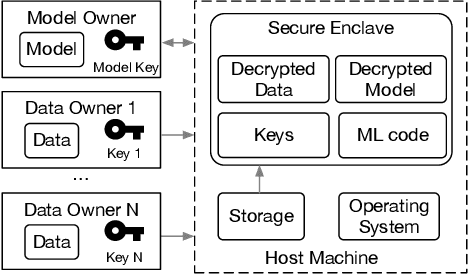
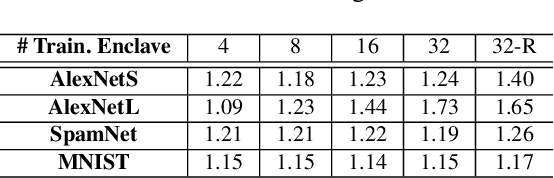
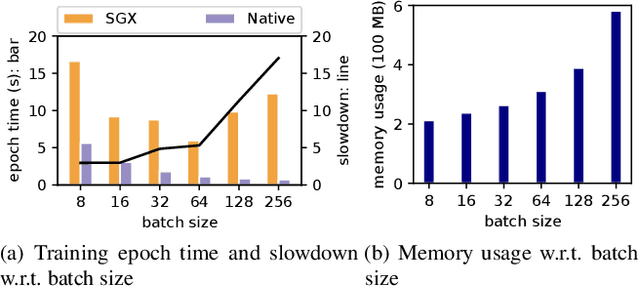
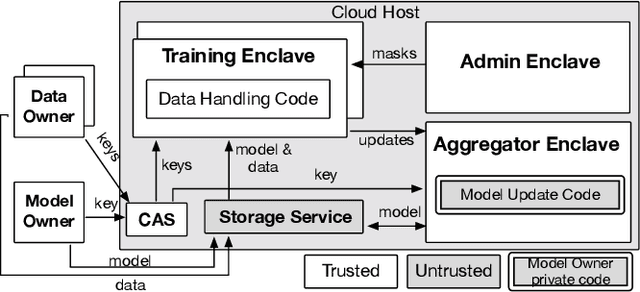
With the advancement of machine learning (ML) and its growing awareness, many organizations who own data but not ML expertise (data owner) would like to pool their data and collaborate with those who have expertise but need data from diverse sources to train truly generalizable models (model owner). In such collaborative ML, the data owner wants to protect the privacy of its training data, while the model owner desires the confidentiality of the model and the training method which may contain intellectual properties. However, existing private ML solutions, such as federated learning and split learning, cannot meet the privacy requirements of both data and model owners at the same time. This paper presents Citadel, a scalable collaborative ML system that protects the privacy of both data owner and model owner in untrusted infrastructures with the help of Intel SGX. Citadel performs distributed training across multiple training enclaves running on behalf of data owners and an aggregator enclave on behalf of the model owner. Citadel further establishes a strong information barrier between these enclaves by means of zero-sum masking and hierarchical aggregation to prevent data/model leakage during collaborative training. Compared with the existing SGX-protected training systems, Citadel enables better scalability and stronger privacy guarantees for collaborative ML. Cloud deployment with various ML models shows that Citadel scales to a large number of enclaves with less than 1.73X slowdown caused by SGX.