 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid detection of rare events from in situ X-ray diffraction data using machine learning
Dec 07, 2023High-energy X-ray diffraction methods can non-destructively map the 3D microstructure and associated attributes of metallic polycrystalline engineering materials in their bulk form. These methods are often combined with external stimuli such as thermo-mechanical loading to take snapshots over time of the evolving microstructure and attributes. However, the extreme data volumes and the high costs of traditional data acquisition and reduction approaches pose a barrier to quickly extracting actionable insights and improving the temporal resolution of these snapshots. Here we present a fully automated technique capable of rapidly detecting the onset of plasticity in high-energy X-ray microscopy data. Our technique is computationally faster by at least 50 times than the traditional approaches and works for data sets that are up to 9 times sparser than a full data set. This new technique leverages self-supervised image representation learning and clustering to transform massive data into compact, semantic-rich representations of visually salient characteristics (e.g., peak shapes). These characteristics can be a rapid indicator of anomalous events such as changes in diffraction peak shapes. We anticipate that this technique will provide just-in-time actionable information to drive smarter experiments that effectively deploy multi-modal X-ray diffraction methods that span many decades of length scales.
SMLT: A Serverless Framework for Scalable and Adaptive Machine Learning Design and Training
May 04, 2022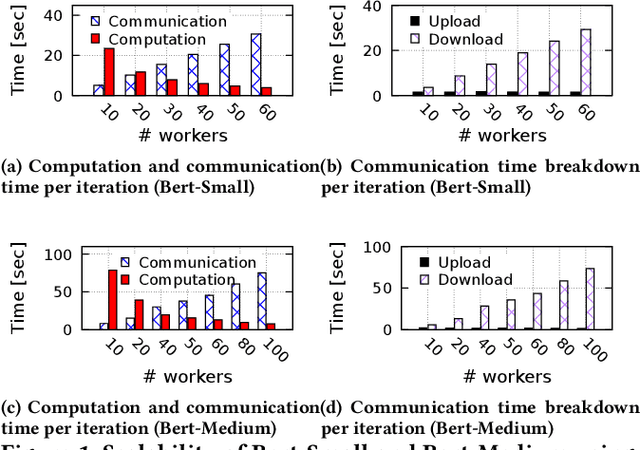

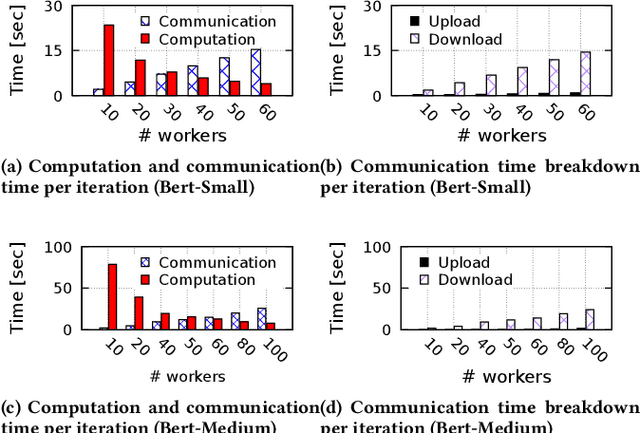
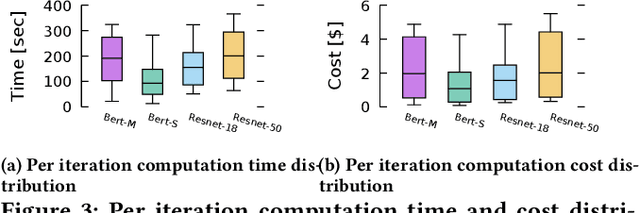
In today's production machine learning (ML) systems, models are continuously trained, improved, and deployed. ML design and training are becoming a continuous workflow of various tasks that have dynamic resource demands. Serverless computing is an emerging cloud paradigm that provides transparent resource management and scaling for users and has the potential to revolutionize the routine of ML design and training. However, hosting modern ML workflows on existing serverless platforms has non-trivial challenges due to their intrinsic design limitations such as stateless nature, limited communication support across function instances, and limited function execution duration. These limitations result in a lack of an overarching view and adaptation mechanism for training dynamics and an amplification of existing problems in ML workflows. To address the above challenges, we propose SMLT, an automated, scalable, and adaptive serverless framework to enable efficient and user-centric ML design and training. SMLT employs an automated and adaptive scheduling mechanism to dynamically optimize the deployment and resource scaling for ML tasks during training. SMLT further enables user-centric ML workflow execution by supporting user-specified training deadlines and budget limits. In addition, by providing an end-to-end design, SMLT solves the intrinsic problems in serverless platforms such as the communication overhead, limited function execution duration, need for repeated initialization, and also provides explicit fault tolerance for ML training. SMLT is open-sourced and compatible with all major ML frameworks. Our experimental evaluation with large, sophisticated modern ML models demonstrate that SMLT outperforms the state-of-the-art VM based systems and existing serverless ML training frameworks in both training speed (up to 8X) and monetary cost (up to 3X)
fairDMS: Rapid Model Training by Data and Model Reuse
Apr 20, 2022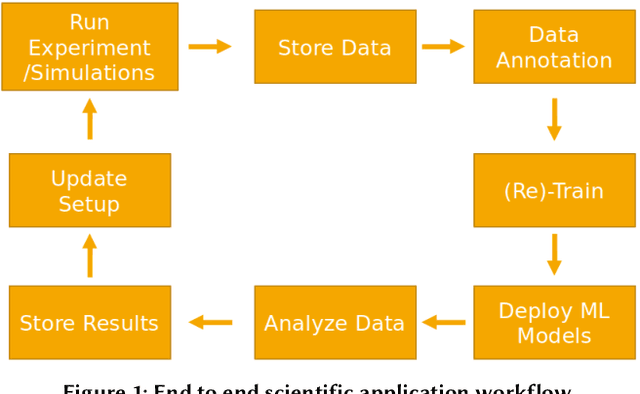
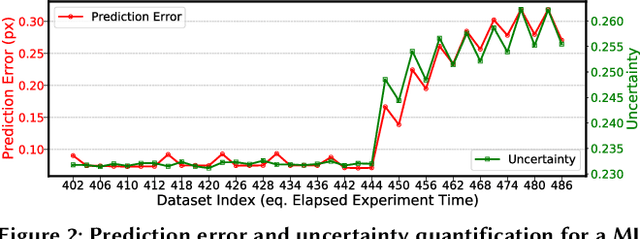
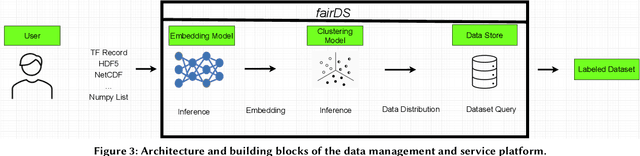
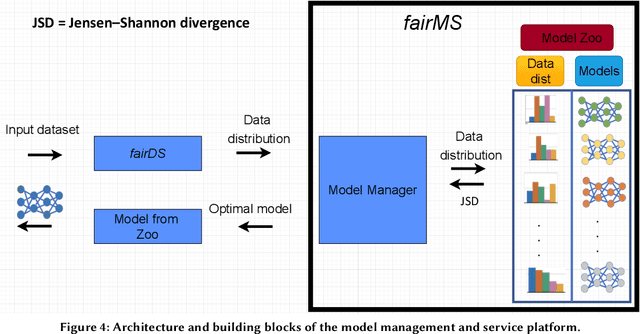
Extracting actionable information from data sources such as the Linac Coherent Light Source (LCLS-II) and Advanced Photon Source Upgrade (APS-U) is becoming more challenging due to the fast-growing data generation rate. The rapid analysis possible with ML methods can enable fast feedback loops that can be used to adjust experimental setups in real-time, for example when errors occur or interesting events are detected. However, to avoid degradation in ML performance over time due to changes in an instrument or sample, we need a way to update ML models rapidly while an experiment is running. We present here a data service and model service to accelerate deep neural network training with a focus on ML-based scientific applications. Our proposed data service achieves 100x speedup in terms of data labeling compare to the current state-of-the-art. Further, our model service achieves up to 200x improvement in training speed. Overall, fairDMS achieves up to 92x speedup in terms of end-to-end model updating time.
Bridge Data Center AI Systems with Edge Computing for Actionable Information Retrieval
May 28, 2021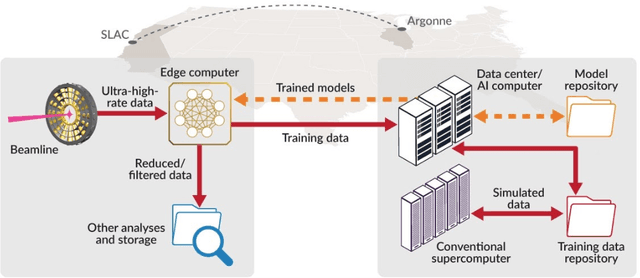

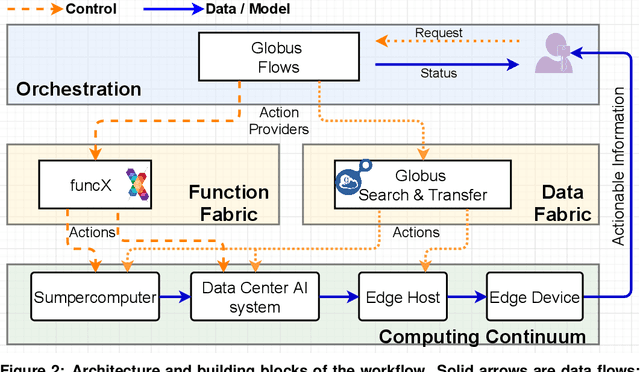
Extremely high data rates at modern synchrotron and X-ray free-electron lasers (XFELs) light source beamlines motivate the use of machine learning methods for data reduction, feature detection, and other purposes. Regardless of the application, the basic concept is the same: data collected in early stages of an experiment, data from past similar experiments, and/or data simulated for the upcoming experiment are used to train machine learning models that, in effect, learn specific characteristics of those data; these models are then used to process subsequent data more efficiently than would general-purpose models that lack knowledge of the specific dataset or data class. Thus, a key challenge is to be able to train models with sufficient rapidity that they can be deployed and used within useful timescales. We describe here how specialized data center AI systems can be used for this purpose.
Curse or Redemption? How Data Heterogeneity Affects the Robustness of Federated Learning
Feb 01, 2021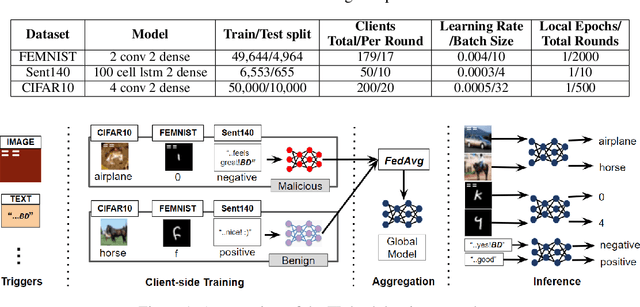
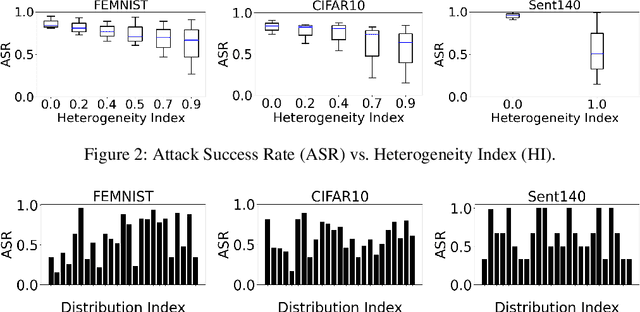
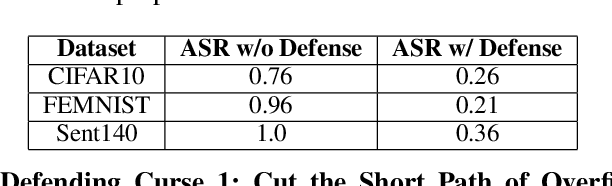
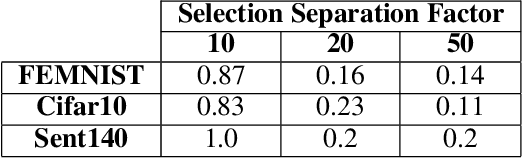
Data heterogeneity has been identified as one of the key features in federated learning but often overlooked in the lens of robustness to adversarial attacks. This paper focuses on characterizing and understanding its impact on backdooring attacks in federated learning through comprehensive experiments using synthetic and the LEAF benchmarks. The initial impression driven by our experimental results suggests that data heterogeneity is the dominant factor in the effectiveness of attacks and it may be a redemption for defending against backdooring as it makes the attack less efficient, more challenging to design effective attack strategies, and the attack result also becomes less predictable. However, with further investigations, we found data heterogeneity is more of a curse than a redemption as the attack effectiveness can be significantly boosted by simply adjusting the client-side backdooring timing. More importantly,data heterogeneity may result in overfitting at the local training of benign clients, which can be utilized by attackers to disguise themselves and fool skewed-feature based defenses. In addition, effective attack strategies can be made by adjusting attack data distribution. Finally, we discuss the potential directions of defending the curses brought by data heterogeneity. The results and lessons learned from our extensive experiments and analysis offer new insights for designing robust federated learning methods and systems
TiFL: A Tier-based Federated Learning System
Jan 25, 2020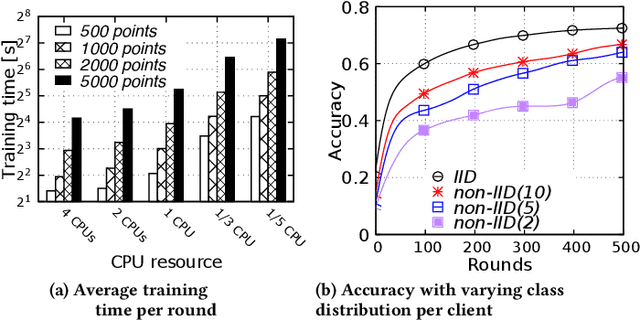
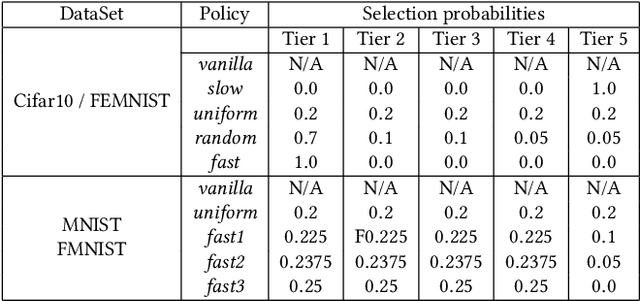
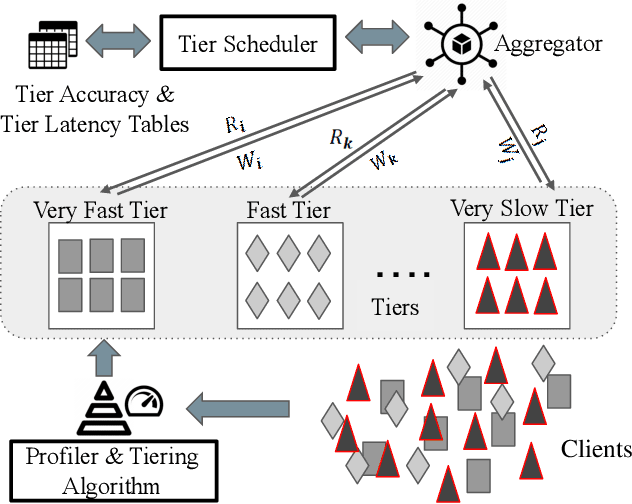
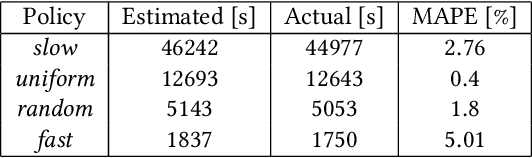
Federated Learning (FL) enables learning a shared model across many clients without violating the privacy requirements. One of the key attributes in FL is the heterogeneity that exists in both resource and data due to the differences in computation and communication capacity, as well as the quantity and content of data among different clients. We conduct a case study to show that heterogeneity in resource and data has a significant impact on training time and model accuracy in conventional FL systems. To this end, we propose TiFL, a Tier-based Federated Learning System, which divides clients into tiers based on their training performance and selects clients from the same tier in each training round to mitigate the straggler problem caused by heterogeneity in resource and data quantity. To further tame the heterogeneity caused by non-IID (Independent and Identical Distribution) data and resources, TiFL employs an adaptive tier selection approach to update the tiering on-the-fly based on the observed training performance and accuracy overtime. We prototype TiFL in a FL testbed following Google's FL architecture and evaluate it using popular benchmarks and the state-of-the-art FL benchmark LEAF. Experimental evaluation shows that TiFL outperforms the conventional FL in various heterogeneous conditions. With the proposed adaptive tier selection policy, we demonstrate that TiFL achieves much faster training performance while keeping the same (and in some cases - better) test accuracy across the board.