 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiFL: A Tier-based Federated Learning System
Paper and Code
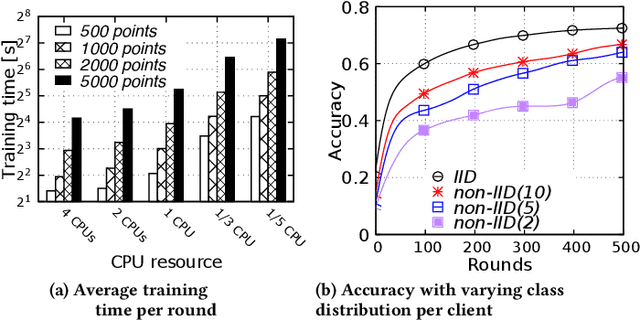
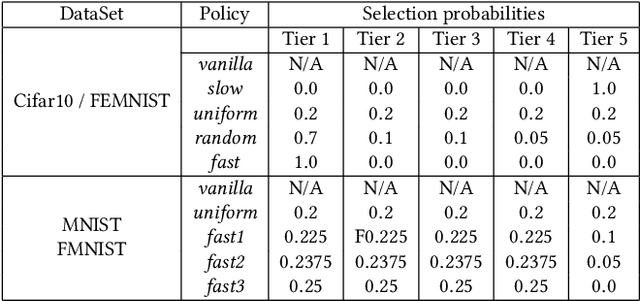
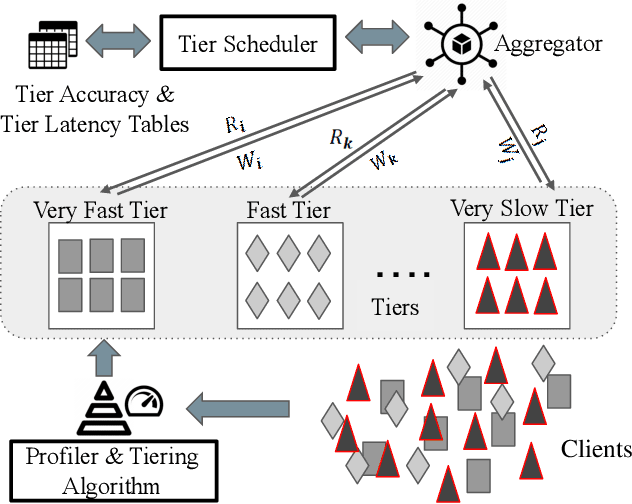
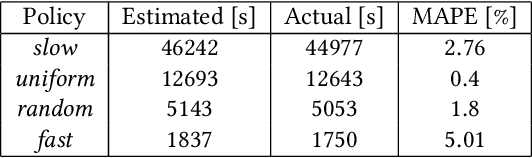
Federated Learning (FL) enables learning a shared model across many clients without violating the privacy requirements. One of the key attributes in FL is the heterogeneity that exists in both resource and data due to the differences in computation and communication capacity, as well as the quantity and content of data among different clients. We conduct a case study to show that heterogeneity in resource and data has a significant impact on training time and model accuracy in conventional FL systems. To this end, we propose TiFL, a Tier-based Federated Learning System, which divides clients into tiers based on their training performance and selects clients from the same tier in each training round to mitigate the straggler problem caused by heterogeneity in resource and data quantity. To further tame the heterogeneity caused by non-IID (Independent and Identical Distribution) data and resources, TiFL employs an adaptive tier selection approach to update the tiering on-the-fly based on the observed training performance and accuracy overtime. We prototype TiFL in a FL testbed following Google's FL architecture and evaluate it using popular benchmarks and the state-of-the-art FL benchmark LEAF. Experimental evaluation shows that TiFL outperforms the conventional FL in various heterogeneous conditions. With the proposed adaptive tier selection policy, we demonstrate that TiFL achieves much faster training performance while keeping the same (and in some cases - better) test accuracy across the board.