 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistically Interpreting the Role of Sample Difficulty in RLVR for LLMs
May 27, 2026Reinforcement Learning with Verifiable Reward (RLVR) is empirically shown to notably enhance the reasoning performance of large language models (LLMs), particularly in mathematics and programming. However, the mechanistic role of Sample Difficulty in RLVR remains poorly understood. In this paper, we investigate RLVR through the lens of difficulty-wise and one-sample analysis. We find that sample difficulty has a non-monotonic effect on RLVR: easy and medium-difficulty problems yield the strongest and most stable reasoning improvements, whereas overly hard problems often provide weak learning signals, induce degenerate behaviors such as answer repetition or skipping necessary computation, and can ultimately degrade the model's pre-existing capabilities. Beyond the obverse of response, we further analyze the model's internal feature dynamics using Temporal Sparse Autoencoders (T-SAE). Easy problems mainly reinforce direct-answer and basic-computation features while suppressing deliberative-reasoning features; hard problems activate reasoning-related features but become useful only when successful trajectories are sampled; medium-difficulty problems provide a more balanced signal, strengthening both computation and multi-step reasoning features. Motivated by these findings, we propose difficulty-adaptive strategies for hard-sample utilization, using backward-reasoning reformulation and T-SAE-guided training signals to improve reward density and credit assignment during RLVR. Overall, our results identify sample difficulty as a key factor governing both the optimization dynamics and representation evolution of RLVR.
ZeRO-Prefill: Zero Redundancy Overheads in MoE Prefill Serving
May 03, 2026Production LLM workloads increasingly serve discriminative tasks, such as classification, recommendation, and verification, whose answers are read from the logits of a single prefill pass with no autoregressive decoding. Serving these prefill-only workloads on mixture-of-experts (MoE) models is bottlenecked not by compute but by the distributed execution required to fit the model: existing parallel strategies (tensor, expert, and pipeline parallelism) trade memory pressure for redundant computation, communication, and synchronization, severely degrading MoE prefill serving efficiency. We observe that these overheads stem from coupling expert placement with synchronous activation routing -- a design inherited from the decoding era. The long, compute-bound forward passes of large-batch prefill open a per-layer window wide enough to stream expert weights in the background, replacing per-layer activation AllToAll with asynchronous weight AllGather fully overlapped with computation. We propose ZeRO-Prefill, a prefill-only serving system whose backend, AsyncEP (Asynchronous Expert Parallelism), gathers experts by weight rather than routing them by activation, and whose frontend co-enforces a physically-derived saturation threshold through prefix-aware routing and true-FLOPs load tracking. On Qwen3-235B-A22B across four hardware/precision configurations, ZeRO-Prefill delivers 1.35-1.37x throughput over the strongest distributed baseline on real-world workloads and up to 1.59x on long-context synthetic workloads, sustaining 29.8-36.2% per-GPU model FLOPs utilization.
M3D-Net: Multi-Modal 3D Facial Feature Reconstruction Network for Deepfake Detection
Apr 16, 2026With the rapid advancement of deep learning in image generation, facial forgery techniques have achieved unprecedented realism, posing serious threats to cybersecurity and information authenticity. Most existing deepfake detection approaches rely on the reconstruction of isolated facial attributes without fully exploiting the complementary nature of multi-modal feature representations. To address these challenges, this paper proposes a novel Multi-Modal 3D Facial Feature Reconstruction Network (M3D-Net) for deepfake detection. Our method leverages an end-to-end dual-stream architecture that reconstructs fine-grained facial geometry and reflectance properties from single-view RGB images via a self-supervised 3D facial reconstruction module. The network further enhances detection performance through a 3D Feature Pre-fusion Module (PFM), which adaptively adjusts multi-scale features, and a Multi-modal Fusion Module (MFM) that effectively integrates RGB and 3D-reconstructed features using attention mechanisms. Extensive experiments on multiple public datasets demonstrate that our approach achieves state-of-the-art performance in terms of detection accuracy and robustness, significantly outperforming existing methods while exhibiting strong generalization across diverse scenarios.
Reducing Hallucination in Enterprise AI Workflows via Hybrid Utility Minimum Bayes Risk (HUMBR)
Apr 13, 2026Although LLMs drive automation, it is critical to ensure immense consideration for high-stakes enterprise workflows such as those involving legal matters, risk management, and privacy compliance. For Meta, and other organizations like ours, a single hallucinated clause in such high stakes workflows risks material consequences. We show that by framing hallucination mitigation as a Minimum Bayes Risk (MBR) problem, we can dramatically reduce this risk. Specifically, we introduce a Hybrid Utility MBR (HUMBR) framework that synthesizes semantic embedding similarity with lexical precision to identify consensus without ground-truth references, for which we derive rigorous error bounds. We complement this theoretical analysis with a comprehensive empirical evaluation on widely-used public benchmark suites (TruthfulQA and LegalBench) and also real world data from Meta production deployment. The results from our empirical study show that MBR significantly outperforms standard Universal Self-Consistency. Notably, 81% of the pipeline's suggestions were preferred over human-crafted ground truth, and critical recall failures were virtually eliminated.
ViviDoc: Generating Interactive Documents through Human-Agent Collaboration
Mar 30, 2026Interactive documents help readers engage with complex ideas through dynamic visualization, interactive animations, and exploratory interfaces. However, creating such documents remains costly, as it requires both domain expertise and web development skills. Recent Large Language Model (LLM)-based agents can automate content creation, but directly applying them to interactive document generation often produces outputs that are difficult to control. To address this, we present ViviDoc, to the best of our knowledge the first work to systematically address interactive document generation. ViviDoc introduces a multi-agent pipeline (Planner, Styler, Executor, Evaluator). To make the generation process controllable, we provide three levels of human control: (1) the Document Specification (DocSpec) with SRTC Interaction Specifications (State, Render, Transition, Constraint) for structured planning, (2) a content-aware Style Palette for customizing writing and interaction styles, and (3) chat-based editing for iterative refinement. We also construct ViviBench, a benchmark of 101 topics derived from real-world interactive documents across 11 domains, along with a taxonomy of 8 interaction types and a 4-dimensional automated evaluation framework validated against human ratings (Pearson r > 0.84). Experiments show that ViviDoc achieves the highest content richness and interaction quality in both automated and human evaluation. A 12-person user study confirms that the system is easy to use, provides effective control over the generation process, and produces documents that satisfy users.
ZenFlow: Enabling Stall-Free Offloading Training via Asynchronous Updates
May 18, 2025Fine-tuning large language models (LLMs) often exceeds GPU memory limits, prompting systems to offload model states to CPU memory. However, existing offloaded training frameworks like ZeRO-Offload treat all parameters equally and update the full model on the CPU, causing severe GPU stalls, where fast, expensive GPUs sit idle waiting for slow CPU updates and limited-bandwidth PCIe transfers. We present ZenFlow, a new offloading framework that prioritizes important parameters and decouples updates between GPU and CPU. ZenFlow performs in-place updates of important gradients on GPU, while asynchronously offloading and accumulating less important ones on CPU, fully overlapping CPU work with GPU computation. To scale across GPUs, ZenFlow introduces a lightweight gradient selection method that exploits a novel spatial and temporal locality property of important gradients, avoiding costly global synchronization. ZenFlow achieves up to 5x end-to-end speedup, 2x lower PCIe traffic, and reduces GPU stalls by over 85 percent, all while preserving accuracy.
LCGC: Learning from Consistency Gradient Conflicting for Class-Imbalanced Semi-Supervised Debiasing
Apr 09, 2025Classifiers often learn to be biased corresponding to the class-imbalanced dataset, especially under the semi-supervised learning (SSL) set. While previous work tries to appropriately re-balance the classifiers by subtracting a class-irrelevant image's logit, but lacks a firm theoretical basis. We theoretically analyze why exploiting a baseline image can refine pseudo-labels and prove that the black image is the best choice. We also indicated that as the training process deepens, the pseudo-labels before and after refinement become closer. Based on this observation, we propose a debiasing scheme dubbed LCGC, which Learning from Consistency Gradient Conflicting, by encouraging biased class predictions during training. We intentionally update the pseudo-labels whose gradient conflicts with the debiased logits, representing the optimization direction offered by the over-imbalanced classifier predictions. Then, we debiased the predictions by subtracting the baseline image logits during testing. Extensive experiments demonstrate that LCGC can significantly improve the prediction accuracy of existing CISSL models on public benchmarks.
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024
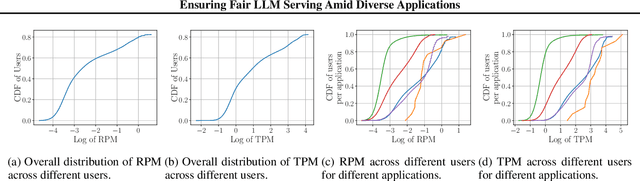
In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.
LOCAL: Learning with Orientation Matrix to Infer Causal Structure from Time Series Data
Oct 28, 2024


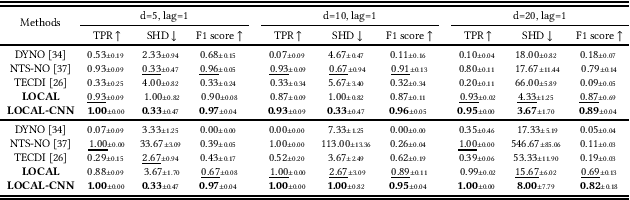
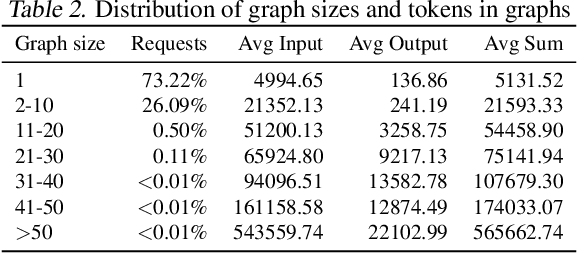
Discovering the underlying Directed Acyclic Graph (DAG) from time series observational data is highly challenging due to the dynamic nature and complex nonlinear interactions between variables. Existing methods often struggle with inefficiency and the handling of high-dimensional data. To address these research gap, we propose LOCAL, a highly efficient, easy-to-implement, and constraint-free method for recovering dynamic causal structures. LOCAL is the first attempt to formulate a quasi-maximum likelihood-based score function for learning the dynamic DAG equivalent to the ground truth. On this basis, we propose two adaptive modules for enhancing the algebraic characterization of acyclicity with new capabilities: Asymptotic Causal Mask Learning (ACML) and Dynamic Graph Parameter Learning (DGPL). ACML generates causal masks using learnable priority vectors and the Gumbel-Sigmoid function, ensuring the creation of DAGs while optimizing computational efficiency. DGPL transforms causal learning into decomposed matrix products, capturing the dynamic causal structure of high-dimensional data and enhancing interpretability. Extensive experiments on synthetic and real-world datasets demonstrate that LOCAL significantly outperforms existing methods, and highlight LOCAL's potential as a robust and efficient method for dynamic causal discovery. Our code will be available soon.
LinBridge: A Learnable Framework for Interpreting Nonlinear Neural Encoding Models
Oct 26, 2024



Neural encoding of artificial neural networks (ANNs) links their computational representations to brain responses, offering insights into how the brain processes information. Current studies mostly use linear encoding models for clarity, even though brain responses are often nonlinear. This has sparked interest in developing nonlinear encoding models that are still interpretable. To address this problem, we propose LinBridge, a learnable and flexible framework based on Jacobian analysis for interpreting nonlinear encoding models. LinBridge posits that the nonlinear mapping between ANN representations and neural responses can be factorized into a linear inherent component that approximates the complex nonlinear relationship, and a mapping bias that captures sample-selective nonlinearity. The Jacobian matrix, which reflects output change rates relative to input, enables the analysis of sample-selective mapping in nonlinear models. LinBridge employs a self-supervised learning strategy to extract both the linear inherent component and nonlinear mapping biases from the Jacobian matrices of the test set, allowing it to adapt effectively to various nonlinear encoding models. We validate the LinBridge framework in the scenario of neural visual encoding, using computational visual representations from CLIP-ViT to predict brain activity recorded via functional magnetic resonance imaging (fMRI). Our experimental results demonstrate that: 1) the linear inherent component extracted by LinBridge accurately reflects the complex mappings of nonlinear neural encoding models; 2) the sample-selective mapping bias elucidates the variability of nonlinearity across different levels of the visual processing hierarchy. This study presents a novel tool for interpreting nonlinear neural encoding models and offers fresh evidence about hierarchical nonlinearity distribution in the visual cortex.