 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemora: A Harmonic Memory Representation Balancing Abstraction and Specificity
Feb 03, 2026Agent memory systems must accommodate continuously growing information while supporting efficient, context-aware retrieval for downstream tasks. Abstraction is essential for scaling agent memory, yet it often comes at the cost of specificity, obscuring the fine-grained details required for effective reasoning. We introduce Memora, a harmonic memory representation that structurally balances abstraction and specificity. Memora organizes information via its primary abstractions that index concrete memory values and consolidate related updates into unified memory entries, while cue anchors expand retrieval access across diverse aspects of the memory and connect related memories. Building on this structure, we employ a retrieval policy that actively exploits these memory connections to retrieve relevant information beyond direct semantic similarity. Theoretically, we show that standard Retrieval-Augmented Generation (RAG) and Knowledge Graph (KG)-based memory systems emerge as special cases of our framework. Empirically, Memora establishes a new state-of-the-art on the LoCoMo and LongMemEval benchmarks, demonstrating better retrieval relevance and reasoning effectiveness as memory scales.
Adapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
Attention Enhanced Entity Recommendation for Intelligent Monitoring in Cloud Systems
Oct 23, 2025In this paper, we present DiRecGNN, an attention-enhanced entity recommendation framework for monitoring cloud services at Microsoft. We provide insights on the usefulness of this feature as perceived by the cloud service owners and lessons learned from deployment. Specifically, we introduce the problem of recommending the optimal subset of attributes (dimensions) that should be tracked by an automated watchdog (monitor) for cloud services. To begin, we construct the monitor heterogeneous graph at production-scale. The interaction dynamics of these entities are often characterized by limited structural and engagement information, resulting in inferior performance of state-of-the-art approaches. Moreover, traditional methods fail to capture the dependencies between entities spanning a long range due to their homophilic nature. Therefore, we propose an attention-enhanced entity ranking model inspired by transformer architectures. Our model utilizes a multi-head attention mechanism to focus on heterogeneous neighbors and their attributes, and further attends to paths sampled using random walks to capture long-range dependencies. We also employ multi-faceted loss functions to optimize for relevant recommendations while respecting the inherent sparsity of the data. Empirical evaluations demonstrate significant improvements over existing methods, with our model achieving a 43.1% increase in MRR. Furthermore, product teams who consumed these features perceive the feature as useful and rated it 4.5 out of 5.
Synergistic Weak-Strong Collaboration by Aligning Preferences
Apr 22, 2025Current Large Language Models (LLMs) excel in general reasoning yet struggle with specialized tasks requiring proprietary or domain-specific knowledge. Fine-tuning large models for every niche application is often infeasible due to black-box constraints and high computational overhead. To address this, we propose a collaborative framework that pairs a specialized weak model with a general strong model. The weak model, tailored to specific domains, produces initial drafts and background information, while the strong model leverages its advanced reasoning to refine these drafts, extending LLMs' capabilities to critical yet specialized tasks. To optimize this collaboration, we introduce a collaborative feedback to fine-tunes the weak model, which quantifies the influence of the weak model's contributions in the collaboration procedure and establishes preference pairs to guide preference tuning of the weak model. We validate our framework through experiments on three domains. We find that the collaboration significantly outperforms each model alone by leveraging complementary strengths. Moreover, aligning the weak model with the collaborative preference further enhances overall performance.
LangCoop: Collaborative Driving with Language
Apr 21, 2025



Multi-agent collaboration holds great promise for enhancing the safety, reliability, and mobility of autonomous driving systems by enabling information sharing among multiple connected agents. However, existing multi-agent communication approaches are hindered by limitations of existing communication media, including high bandwidth demands, agent heterogeneity, and information loss. To address these challenges, we introduce LangCoop, a new paradigm for collaborative autonomous driving that leverages natural language as a compact yet expressive medium for inter-agent communication. LangCoop features two key innovations: Mixture Model Modular Chain-of-thought (M$^3$CoT) for structured zero-shot vision-language reasoning and Natural Language Information Packaging (LangPack) for efficiently packaging information into concise, language-based messages. Through extensive experiments conducted in the CARLA simulations, we demonstrate that LangCoop achieves a remarkable 96\% reduction in communication bandwidth (< 2KB per message) compared to image-based communication, while maintaining competitive driving performance in the closed-loop evaluation. Our project page and code are at https://xiangbogaobarry.github.io/LangCoop/.
UFO2: The Desktop AgentOS
Apr 20, 2025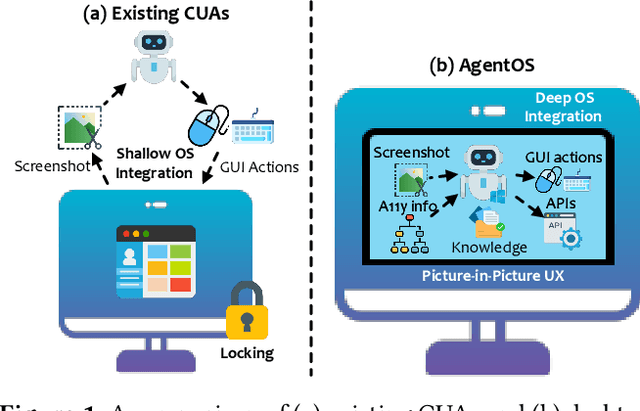
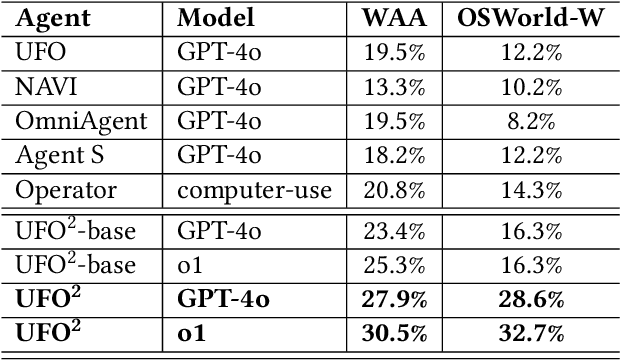
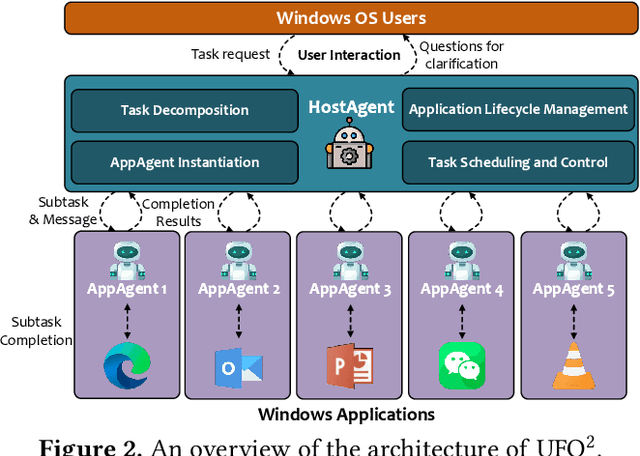
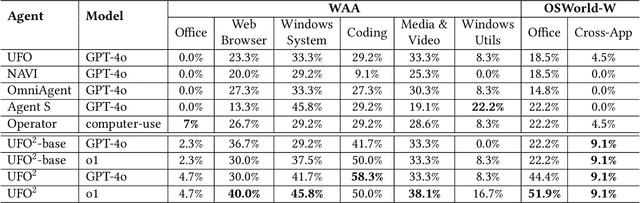
Recent Computer-Using Agents (CUAs), powered by multimodal large language models (LLMs), offer a promising direction for automating complex desktop workflows through natural language. However, most existing CUAs remain conceptual prototypes, hindered by shallow OS integration, fragile screenshot-based interaction, and disruptive execution. We present UFO2, a multiagent AgentOS for Windows desktops that elevates CUAs into practical, system-level automation. UFO2 features a centralized HostAgent for task decomposition and coordination, alongside a collection of application-specialized AppAgent equipped with native APIs, domain-specific knowledge, and a unified GUI--API action layer. This architecture enables robust task execution while preserving modularity and extensibility. A hybrid control detection pipeline fuses Windows UI Automation (UIA) with vision-based parsing to support diverse interface styles. Runtime efficiency is further enhanced through speculative multi-action planning, reducing per-step LLM overhead. Finally, a Picture-in-Picture (PiP) interface enables automation within an isolated virtual desktop, allowing agents and users to operate concurrently without interference. We evaluate UFO2 across over 20 real-world Windows applications, demonstrating substantial improvements in robustness and execution accuracy over prior CUAs. Our results show that deep OS integration unlocks a scalable path toward reliable, user-aligned desktop automation.
AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds
Jan 12, 2025



AI for IT Operations (AIOps) aims to automate complex operational tasks, such as fault localization and root cause analysis, to reduce human workload and minimize customer impact. While traditional DevOps tools and AIOps algorithms often focus on addressing isolated operational tasks, recent advances in Large Language Models (LLMs) and AI agents are revolutionizing AIOps by enabling end-to-end and multitask automation. This paper envisions a future where AI agents autonomously manage operational tasks throughout the entire incident lifecycle, leading to self-healing cloud systems, a paradigm we term AgentOps. Realizing this vision requires a comprehensive framework to guide the design, development, and evaluation of these agents. To this end, we present AIOPSLAB, a framework that not only deploys microservice cloud environments, injects faults, generates workloads, and exports telemetry data but also orchestrates these components and provides interfaces for interacting with and evaluating agents. We discuss the key requirements for such a holistic framework and demonstrate how AIOPSLAB can facilitate the evaluation of next-generation AIOps agents. Through evaluations of state-of-the-art LLM agents within the benchmark created by AIOPSLAB, we provide insights into their capabilities and limitations in handling complex operational tasks in cloud environments.
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024
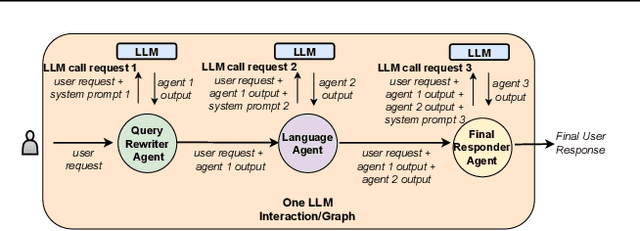
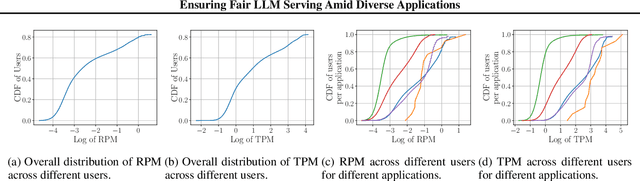
In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.
Automated Root Causing of Cloud Incidents using In-Context Learning with GPT-4
Jan 24, 2024



Root Cause Analysis (RCA) plays a pivotal role in the incident diagnosis process for cloud services, requiring on-call engineers to identify the primary issues and implement corrective actions to prevent future recurrences. Improving the incident RCA process is vital for minimizing service downtime, customer impact and manual toil. Recent advances in artificial intelligence have introduced state-of-the-art Large Language Models (LLMs) like GPT-4, which have proven effective in tackling various AIOps problems, ranging from code authoring to incident management. Nonetheless, the GPT-4 model's immense size presents challenges when trying to fine-tune it on user data because of the significant GPU resource demand and the necessity for continuous model fine-tuning with the emergence of new data. To address the high cost of fine-tuning LLM, we propose an in-context learning approach for automated root causing, which eliminates the need for fine-tuning. We conduct extensive study over 100,000 production incidents, comparing several large language models using multiple metrics. The results reveal that our in-context learning approach outperforms the previous fine-tuned large language models such as GPT-3 by an average of 24.8\% across all metrics, with an impressive 49.7\% improvement over the zero-shot model. Moreover, human evaluation involving actual incident owners demonstrates its superiority over the fine-tuned model, achieving a 43.5\% improvement in correctness and an 8.7\% enhancement in readability. The impressive results demonstrate the viability of utilizing a vanilla GPT model for the RCA task, thereby avoiding the high computational and maintenance costs associated with a fine-tuned model.