 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Caching of Contextual Summaries for Efficient Question-Answering with Language Models
May 16, 2025Large Language Models (LLMs) are increasingly deployed across edge and cloud platforms for real-time question-answering and retrieval-augmented generation. However, processing lengthy contexts in distributed systems incurs high computational overhead, memory usage, and network bandwidth. This paper introduces a novel semantic caching approach for storing and reusing intermediate contextual summaries, enabling efficient information reuse across similar queries in LLM-based QA workflows. Our method reduces redundant computations by up to 50-60% while maintaining answer accuracy comparable to full document processing, as demonstrated on NaturalQuestions, TriviaQA, and a synthetic ArXiv dataset. This approach balances computational cost and response quality, critical for real-time AI assistants.
HERA: Hybrid Edge-cloud Resource Allocation for Cost-Efficient AI Agents
Apr 01, 2025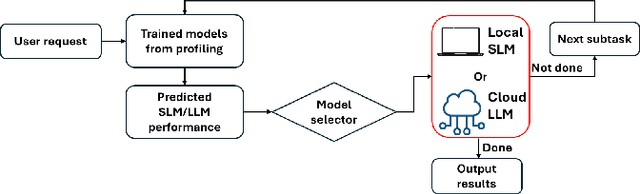

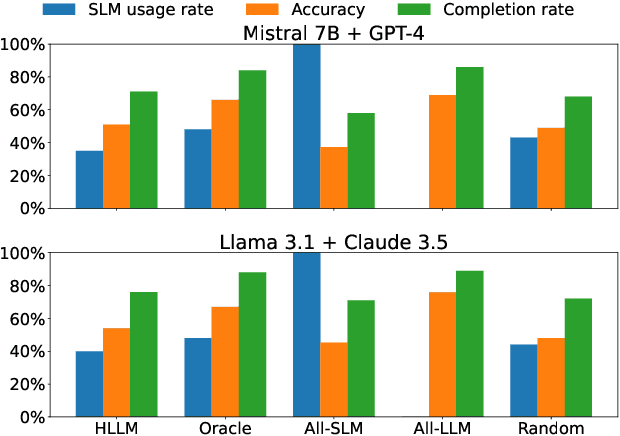
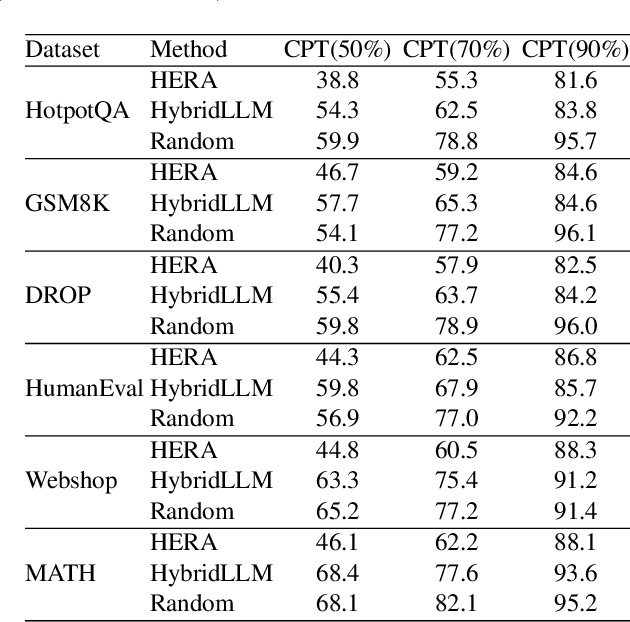
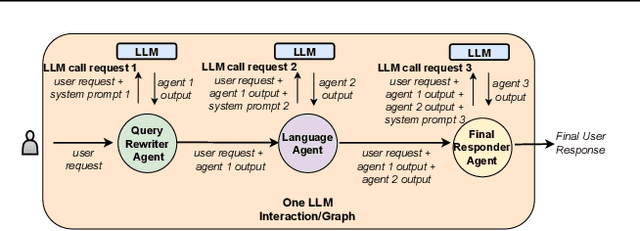
In the realm of AI, large language models (LLMs) like GPT-4, central to the operation of AI agents, predominantly operate in the cloud, incurring high operational costs. With local-based small language models (SLMs) becoming more accurate, the necessity of cloud-exclusive processing is being reconsidered. An AI agent's response to a user's request comprises a series of subtasks or iterations. Existing approaches only allocate a single request between SLM and LLM to ensure their outputs are similar, but adopting this approach in the AI agent scenario for assigning each subtask is not effective since SLM will output a different subsequent subtask, which affects the accuracy of the final output. In this paper, we first conduct experimental analysis to understand the features of AI agent operations. Leveraging our findings, we propose the Adaptive Iteration-level Model Selector (AIMS), a lightweight scheduler to automatically partition AI agent's subtasks between local-based SLM and cloud-based LLM. AIMS considers the varying subtask features and strategically decides the location for each subtask in order to use SLM as much as possible while attaining the accuracy level. Our experimental results demonstrate that AIMS increases accuracy by up to 9.1% and SLM usage by up to 10.8% compared to HybridLLM. It offloads 45.67% of subtasks to a local SLM while attaining similar accuracy on average compared with the cloud-only LLM approach.
Mitigating KV Cache Competition to Enhance User Experience in LLM Inference
Mar 17, 2025In Large Language Model (LLM) serving, the KV-cache (KVC) bottleneck causes high tail Time-to-First-Token (TTFT) and Time-Between-Tokens (TBT), impairing user experience, particularly in time-sensitive applications. However, satisfying both TTFT and TBT service-level objectives (SLOs) is challenging. To address this, we propose a system, named CacheOPT for mitigating KV Cache competition, based on key insights from our measurements, incorporating novel components. First, it estimates a request's output length, bounding the deviation with a high specified probability, adjusted based on the request arrival rate. Second, it allocates the estimated KVC demand to a request, and reuses other requests' allocated KVC to avoid preemptions while reducing waiting time. Third, it proactively allocates KVC before instead of at the time a request exhausts its allocation and reserves KVC globally to prevent preemptions. Fourth, it chooses a request that has long TBT SLO, long job remaining time and short preemption time to preempt. Fifth, it selects the shortest-latency strategy between swapping and recomputation for preemptions. Experiments show that CacheOPT achieves up to 3.29$\times$ and 2.83$\times$ lower tail TBT and tail TTFT, 47\% and 53\% higher TTFT and TBT SLO attainments, and supports up to 1.58$\times$ higher request arrival rate than the state-of-the-art methods.
AccelGen: Heterogeneous SLO-Guaranteed High-Throughput LLM Inference Serving for Diverse Applications
Mar 17, 2025In this paper, we consider a mixed-prompt scenario for a large language model (LLM) inference serving system that supports diverse applications with both short prompts and long prompts and heterogeneous SLOs for iteration time. To improve throughput when handling long prompts, previous research introduces a chunking method, but has not addressed heterogeneous SLOs. To address the limitation, we propose AccelGen, a high-throughput LLM inference serving system with heterogeneous SLO guarantees for diverse applications. AccelGen introduces four core components: (1) SLO-guaranteed dynamic chunking, which dynamically adjusts chunk sizes to maximize GPU compute utilization while meeting iteration-level SLOs; (2) Iteration-level SLO-based task prioritization, which prioritizes tight-SLO requests and batches requests with similar SLOs; (3) Multi-resource-aware batching, which selects queued requests to maximize the utilizations of both GPU compute resource and key-value cache (KVC). Trace-driven real experiments demonstrate that AccelGen achieves 1.42-11.21X higher throughput, 1.43-13.71X higher goodput, 37-90% higher SLO attainment, and 1.61-12.22X lower response latency compared to the state-of-the-art approaches. It achieves performance near the Oracle, which optimally maximizes goodput.
eMoE: Task-aware Memory Efficient Mixture-of-Experts-Based (MoE) Model Inference
Mar 10, 2025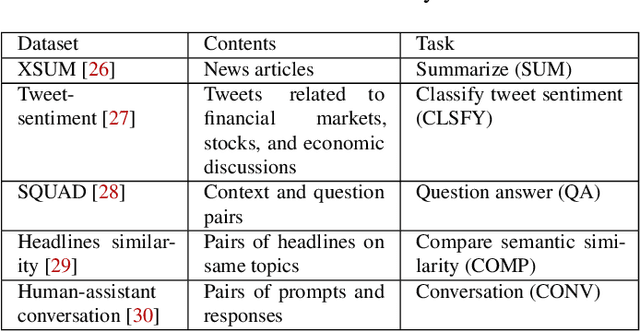
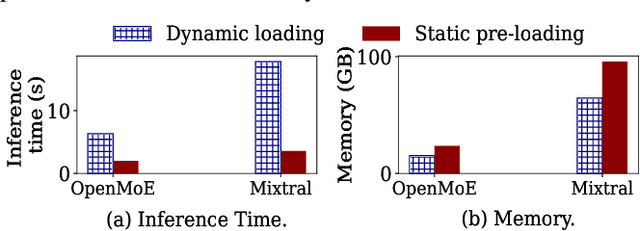
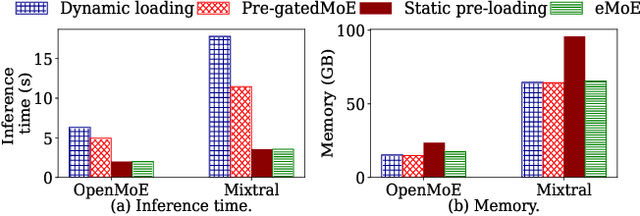
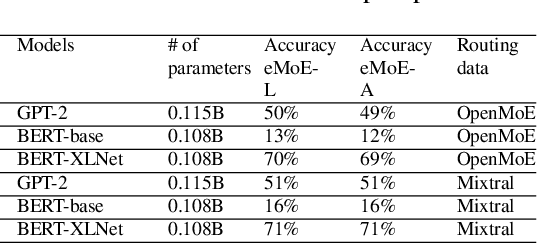
In recent years, Mixture-of-Experts (MoE) has emerged as an effective approach for enhancing the capacity of deep neural network (DNN) with sub-linear computational costs. However, storing all experts on GPUs incurs significant memory overhead, increasing the monetary cost of MoE-based inference. To address this, we propose eMoE, a memory efficient inference system for MoE-based large language models (LLMs) by leveraging our observations from experiment measurements. eMoE reduces memory usage by predicting and loading only the required experts based on recurrent patterns in expert routing. To reduce loading latency while maintaining accuracy, as we found using the same experts for subsequent prompts has minimal impact on perplexity, eMoE invokes the expert predictor every few prompts rather than for each prompt. In addition, it skips predictions for tasks less sensitive to routing accuracy. Finally, it has task-aware scheduling to minimize inference latency by considering Service Level Objectives (SLOs), task-specific output lengths, and expert loading latencies. Experimental results show that compared to existing systems, eMoE reduces memory consumption by up to 80% while maintaining accuracy and reduces inference latency by up to 17%. It also enables processing prompts 40x longer, batches 4.5x larger, and achieves 1.5x higher throughput.
HACK: Homomorphic Acceleration via Compression of the Key-Value Cache for Disaggregated LLM Inference
Feb 05, 2025

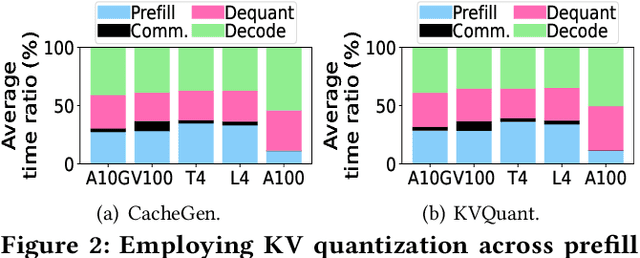

Disaggregated Large Language Model (LLM) inference has gained popularity as it separates the computation-intensive prefill stage from the memory-intensive decode stage, avoiding the prefill-decode interference and improving resource utilization. However, transmitting Key-Value (KV) data between the two stages can be a bottleneck, especially for long prompts. Additionally, the computation time overhead for prefill and decode is key for optimizing Job Completion Time (JCT), and KV data size can become prohibitive for long prompts and sequences. Existing KV quantization methods can alleviate the transmission bottleneck and reduce memory requirements, but they introduce significant dequantization overhead, exacerbating the computation time. We propose Homomorphic Acceleration via Compression of the KV cache (HACK) for disaggregated LLM inference. HACK eliminates the heavy KV dequantization step, and directly performs computations on quantized KV data to approximate and reduce the cost of the expensive matrix-multiplication step. Extensive trace-driven experiments show that HACK reduces JCT by up to 70.9% compared to disaggregated LLM inference baseline and by up to 52.3% compared to state-of-the-art KV quantization methods.
Towards Efficient Large Multimodal Model Serving
Feb 02, 2025Recent advances in generative AI have led to large multi-modal models (LMMs) capable of simultaneously processing inputs of various modalities such as text, images, video, and audio. While these models demonstrate impressive capabilities, efficiently serving them in production environments poses significant challenges due to their complex architectures and heterogeneous resource requirements. We present the first comprehensive systems analysis of two prominent LMM architectures, decoder-only and cross-attention, on six representative open-source models. We investigate their multi-stage inference pipelines and resource utilization patterns that lead to unique systems design implications. We also present an in-depth analysis of production LMM inference traces, uncovering unique workload characteristics, including variable, heavy-tailed request distributions, diverse modal combinations, and bursty traffic patterns. Our key findings reveal that different LMM inference stages exhibit highly heterogeneous performance characteristics and resource demands, while concurrent requests across modalities lead to significant performance interference. To address these challenges, we propose a decoupled serving architecture that enables independent resource allocation and adaptive scaling for each stage. We further propose optimizations such as stage colocation to maximize throughput and resource utilization while meeting the latency objectives.
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024
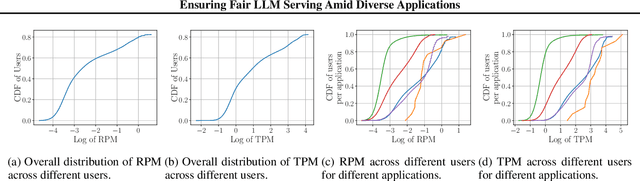
In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.
Zero-Delay QKV Compression for Mitigating KV Cache and Network Bottlenecks in LLM Inference
Aug 07, 2024
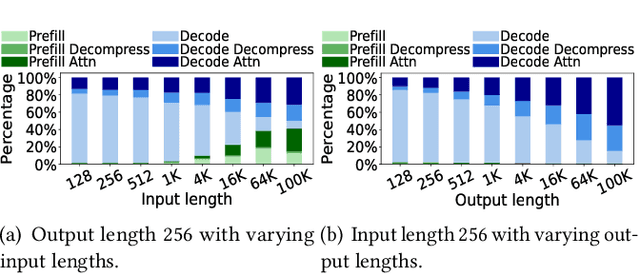
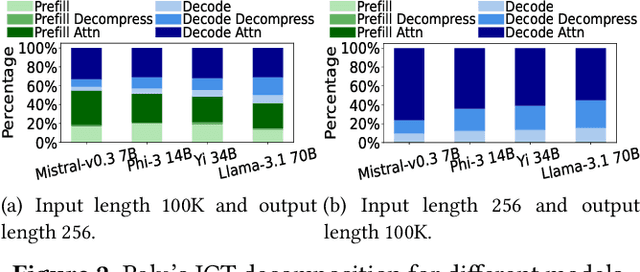
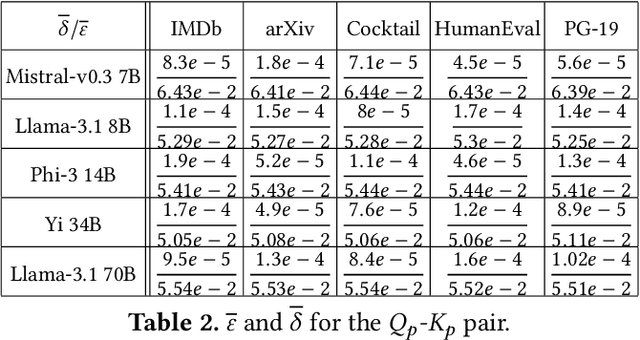
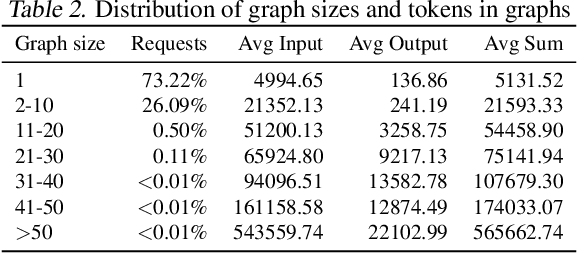
In large-language models, memory constraints in the key-value cache (KVC) pose a challenge during inference, especially with long prompts. In this work, we observed that compressing KV values is more effective than compressing the model regarding accuracy and job completion time (JCT). However, quantizing KV values and dropping less-important tokens incur significant runtime computational time overhead, delaying JCT. These methods also cannot reduce computation time or high network communication time overhead in sequence-parallelism (SP) frameworks for long prompts. To tackle these issues, based on our insightful observations from experimental analysis, we propose ZeroC, a Zero-delay QKV Compression system that eliminates time overhead and even reduces computation and communication time of the model operations. ZeroC innovatively embeds compression and decompression operations within model operations and adaptively determines compression ratios at a hybrid layer-token level. Further, it enables a communication-efficient SP inference framework. Trace-driven experiments demonstrate that ZeroC achieves up to 80% lower average JCT, 35% lower average perplexity, and 2.8x higher throughput with the same latency compared to state-of-the-art compression methods. ZeroC also reduces the average JCT of current LLM serving systems by up to 91% with the constraint of 0.1 perplexity increase. We open-sourced the code.