 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation
Oct 06, 2025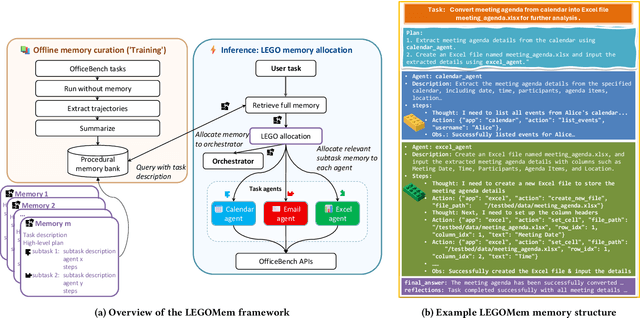
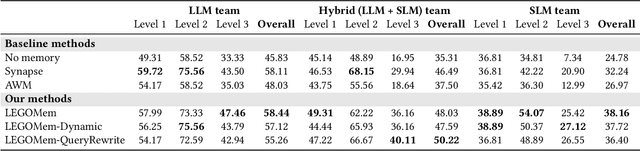
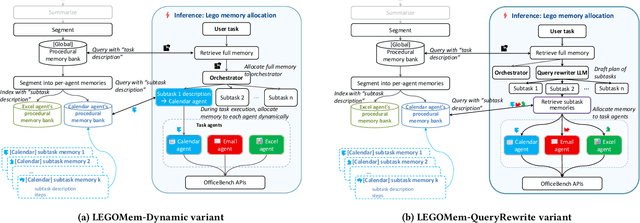
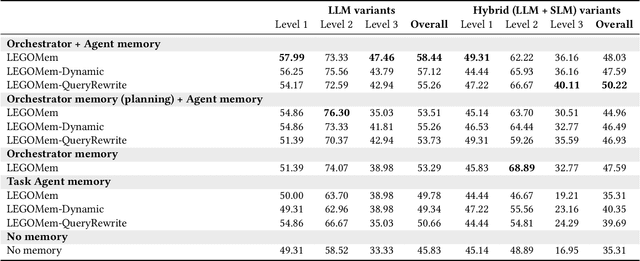
We introduce LEGOMem, a modular procedural memory framework for multi-agent large language model (LLM) systems in workflow automation. LEGOMem decomposes past task trajectories into reusable memory units and flexibly allocates them across orchestrators and task agents to support planning and execution. To explore the design space of memory in multi-agent systems, we use LEGOMem as a lens and conduct a systematic study of procedural memory in multi-agent systems, examining where memory should be placed, how it should be retrieved, and which agents benefit most. Experiments on the OfficeBench benchmark show that orchestrator memory is critical for effective task decomposition and delegation, while fine-grained agent memory improves execution accuracy. We find that even teams composed of smaller language models can benefit substantially from procedural memory, narrowing the performance gap with stronger agents by leveraging prior execution traces for more accurate planning and tool use. These results position LEGOMem as both a practical framework for memory-augmented agent systems and a research tool for understanding memory design in multi-agent workflow automation.
Semantic Caching of Contextual Summaries for Efficient Question-Answering with Language Models
May 16, 2025Large Language Models (LLMs) are increasingly deployed across edge and cloud platforms for real-time question-answering and retrieval-augmented generation. However, processing lengthy contexts in distributed systems incurs high computational overhead, memory usage, and network bandwidth. This paper introduces a novel semantic caching approach for storing and reusing intermediate contextual summaries, enabling efficient information reuse across similar queries in LLM-based QA workflows. Our method reduces redundant computations by up to 50-60% while maintaining answer accuracy comparable to full document processing, as demonstrated on NaturalQuestions, TriviaQA, and a synthetic ArXiv dataset. This approach balances computational cost and response quality, critical for real-time AI assistants.
Exploring How LLMs Capture and Represent Domain-Specific Knowledge
Apr 24, 2025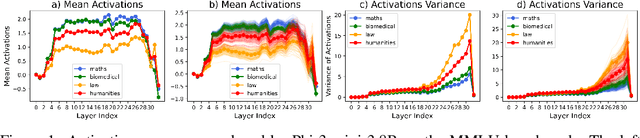

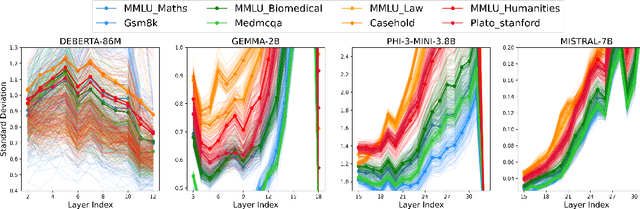

We study whether Large Language Models (LLMs) inherently capture domain-specific nuances in natural language. Our experiments probe the domain sensitivity of LLMs by examining their ability to distinguish queries from different domains using hidden states generated during the prefill phase. We reveal latent domain-related trajectories that indicate the model's internal recognition of query domains. We also study the robustness of these domain representations to variations in prompt styles and sources. Our approach leverages these representations for model selection, mapping the LLM that best matches the domain trace of the input query (i.e., the model with the highest performance on similar traces). Our findings show that LLMs can differentiate queries for related domains, and that the fine-tuned model is not always the most accurate. Unlike previous work, our interpretations apply to both closed and open-ended generative tasks
Hybrid Retrieval-Augmented Generation for Real-time Composition Assistance
Aug 08, 2023



Retrieval augmented models show promise in enhancing traditional language models by improving their contextual understanding, integrating private data, and reducing hallucination. However, the processing time required for retrieval augmented large language models poses a challenge when applying them to tasks that require real-time responses, such as composition assistance. To overcome this limitation, we propose the Hybrid Retrieval-Augmented Generation (HybridRAG) framework that leverages a hybrid setting that combines both client and cloud models. HybridRAG incorporates retrieval-augmented memory generated asynchronously by a Large Language Model (LLM) in the cloud. By integrating this retrieval augmented memory, the client model acquires the capability to generate highly effective responses, benefiting from the LLM's capabilities. Furthermore, through asynchronous memory integration, the client model is capable of delivering real-time responses to user requests without the need to wait for memory synchronization from the cloud. Our experiments on Wikitext and Pile subsets show that HybridRAG achieves lower latency than a cloud-based retrieval-augmented LLM, while outperforming client-only models in utility.