 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemora: A Harmonic Memory Representation Balancing Abstraction and Specificity
Feb 03, 2026Agent memory systems must accommodate continuously growing information while supporting efficient, context-aware retrieval for downstream tasks. Abstraction is essential for scaling agent memory, yet it often comes at the cost of specificity, obscuring the fine-grained details required for effective reasoning. We introduce Memora, a harmonic memory representation that structurally balances abstraction and specificity. Memora organizes information via its primary abstractions that index concrete memory values and consolidate related updates into unified memory entries, while cue anchors expand retrieval access across diverse aspects of the memory and connect related memories. Building on this structure, we employ a retrieval policy that actively exploits these memory connections to retrieve relevant information beyond direct semantic similarity. Theoretically, we show that standard Retrieval-Augmented Generation (RAG) and Knowledge Graph (KG)-based memory systems emerge as special cases of our framework. Empirically, Memora establishes a new state-of-the-art on the LoCoMo and LongMemEval benchmarks, demonstrating better retrieval relevance and reasoning effectiveness as memory scales.
Your Self-Play Algorithm is Secretly an Adversarial Imitator: Understanding LLM Self-Play through the Lens of Imitation Learning
Feb 01, 2026Self-play post-training methods has emerged as an effective approach for finetuning large language models and turn the weak language model into strong language model without preference data. However, the theoretical foundations for self-play finetuning remain underexplored. In this work, we tackle this by connecting self-play finetuning with adversarial imitation learning by formulating finetuning procedure as a min-max game between the model and a regularized implicit reward player parameterized by the model itself. This perspective unifies self-play imitation and general preference alignment within a common framework. Under this formulation, we present a game-theoretic analysis showing that the self-play finetuning will converge to it's equilibrium. Guided by this theoretical formulation, we propose a new self-play imitation finetuning algorithm based on the $χ^2$-divergence variational objective with bounded rewards and improved stability. Experiments on various of language model finetuning tasks demonstrate consistent improvements over existing self-play methods and validate our theoretical insights.
Adapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
LEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation
Oct 06, 2025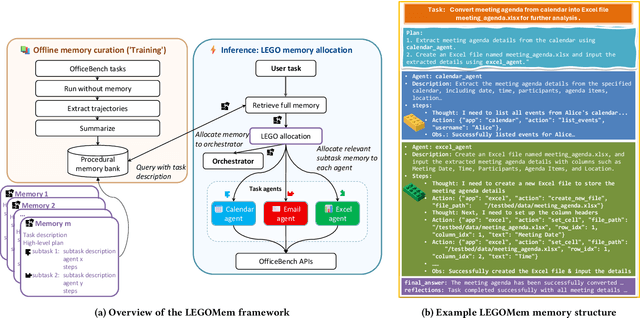
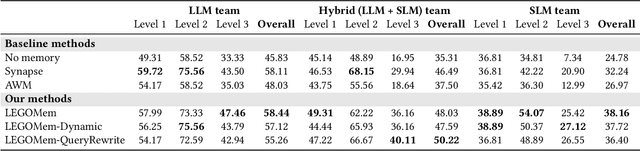
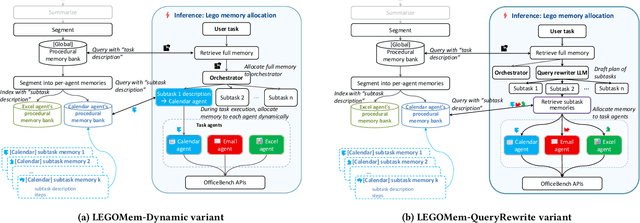
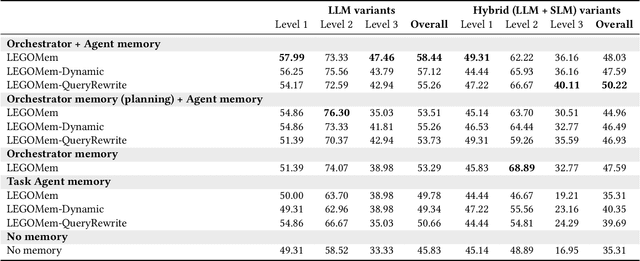
We introduce LEGOMem, a modular procedural memory framework for multi-agent large language model (LLM) systems in workflow automation. LEGOMem decomposes past task trajectories into reusable memory units and flexibly allocates them across orchestrators and task agents to support planning and execution. To explore the design space of memory in multi-agent systems, we use LEGOMem as a lens and conduct a systematic study of procedural memory in multi-agent systems, examining where memory should be placed, how it should be retrieved, and which agents benefit most. Experiments on the OfficeBench benchmark show that orchestrator memory is critical for effective task decomposition and delegation, while fine-grained agent memory improves execution accuracy. We find that even teams composed of smaller language models can benefit substantially from procedural memory, narrowing the performance gap with stronger agents by leveraging prior execution traces for more accurate planning and tool use. These results position LEGOMem as both a practical framework for memory-augmented agent systems and a research tool for understanding memory design in multi-agent workflow automation.
Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Jun 10, 2025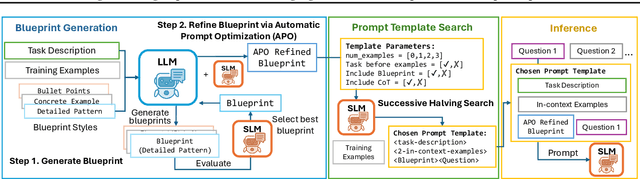
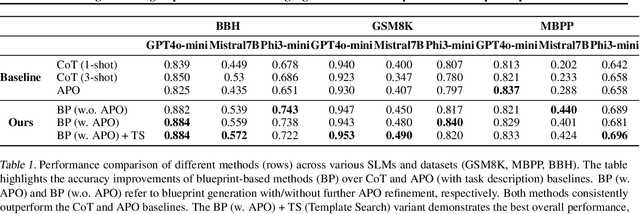


Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs' limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs' sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025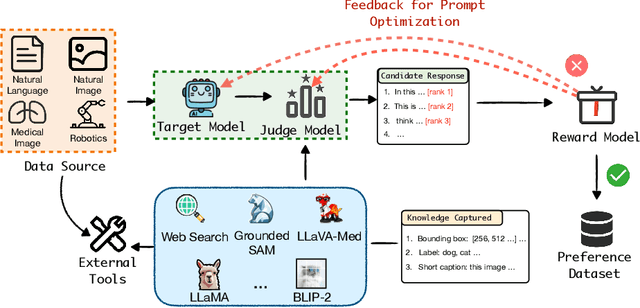
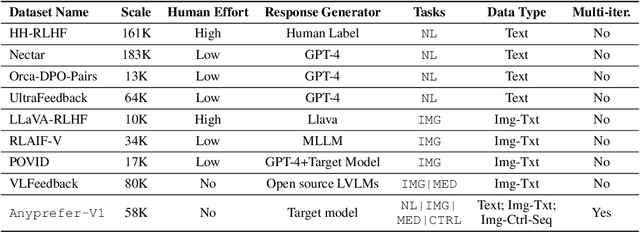
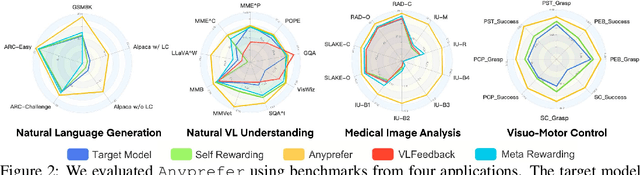
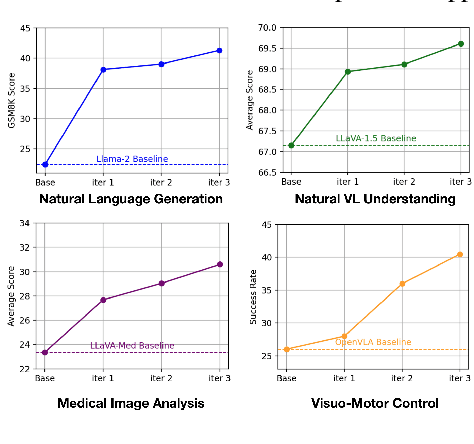
High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.
Synergistic Weak-Strong Collaboration by Aligning Preferences
Apr 22, 2025Current Large Language Models (LLMs) excel in general reasoning yet struggle with specialized tasks requiring proprietary or domain-specific knowledge. Fine-tuning large models for every niche application is often infeasible due to black-box constraints and high computational overhead. To address this, we propose a collaborative framework that pairs a specialized weak model with a general strong model. The weak model, tailored to specific domains, produces initial drafts and background information, while the strong model leverages its advanced reasoning to refine these drafts, extending LLMs' capabilities to critical yet specialized tasks. To optimize this collaboration, we introduce a collaborative feedback to fine-tunes the weak model, which quantifies the influence of the weak model's contributions in the collaboration procedure and establishes preference pairs to guide preference tuning of the weak model. We validate our framework through experiments on three domains. We find that the collaboration significantly outperforms each model alone by leveraging complementary strengths. Moreover, aligning the weak model with the collaborative preference further enhances overall performance.
AMPO: Active Multi-Preference Optimization
Feb 25, 2025Multi-preference optimization enriches language-model alignment beyond pairwise preferences by contrasting entire sets of helpful and undesired responses, thereby enabling richer training signals for large language models. During self-play alignment, these models often produce numerous candidate answers per query, rendering it computationally infeasible to include all responses in the training objective. In this work, we propose $\textit{Active Multi-Preference Optimization}$ (AMPO), a novel approach that combines on-policy generation, a multi-preference group-contrastive loss, and active subset selection. Specifically, we score and embed large candidate pools of responses and then select a small, yet informative, subset that covers reward extremes and distinct semantic clusters for preference optimization. Our contrastive training scheme is capable of identifying not only the best and worst answers but also subtle, underexplored modes that are crucial for robust alignment. Theoretically, we provide guarantees for expected reward maximization using our active selection method, and empirically, AMPO achieves state-of-the-art results on $\textit{AlpacaEval}$ using Llama 8B.
Verifiable Format Control for Large Language Model Generations
Feb 06, 2025Recent Large Language Models (LLMs) have demonstrated satisfying general instruction following ability. However, small LLMs with about 7B parameters still struggle fine-grained format following (e.g., JSON format), which seriously hinder the advancements of their applications. Most existing methods focus on benchmarking general instruction following while overlook how to improve the specific format following ability for small LLMs. Besides, these methods often rely on evaluations based on advanced LLMs (e.g., GPT-4), which can introduce the intrinsic bias of LLMs and be costly due to the API calls. In this paper, we first curate a fully verifiable format following dataset VFF. In contrast to existing works often adopting external LLMs for instruction-following validations, every sample of VFF can be easily validated with a Python function. Further, we propose to leverage this verifiable feature to synthesize massive data for progressively training small LLMs, in order to improve their format following abilities. Experimental results highlight the prevalent limitations in the format following capabilities of 7B level open-source LLMs and demonstrate the effectiveness of our method in enhancing this essential ability.
REFA: Reference Free Alignment for multi-preference optimization
Dec 20, 2024We introduce REFA, a family of reference-free alignment methods that optimize over multiple user preferences while enforcing fine-grained length control. Our approach integrates deviation-based weighting to emphasize high-quality responses more strongly, length normalization to prevent trivial short-response solutions, and an EOS-probability regularizer to mitigate dataset-induced brevity biases. Theoretically, we show that under the Uncertainty Reduction with Sequence Length Assertion (URSLA), naive length normalization can still incentivize length-based shortcuts. By contrast, REFA corrects these subtle incentives, guiding models toward genuinely more informative and higher-quality outputs. Empirically, REFA sets a new state-of-the-art among reference-free alignment methods, producing richer responses aligned more closely with human preferences. Compared to a base supervised fine-tuned (SFT) mistral-7b model that achieves 8.4% length-controlled win rate (LC-WR) and 6.2% win rate (WR), our best REFA configuration attains 21.62% LC-WR and 19.87% WR on the AlpacaEval v2 benchmark. This represents a substantial improvement over both the strongest multi-preference baseline, InfoNCA (16.82% LC-WR, 10.44% WR), and the strongest reference-free baseline, SimPO (20.01% LC-WR, 17.65% WR)