 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAUP: Situation Awareness Uncertainty Propagation on LLM Agent
Dec 02, 2024



Large language models (LLMs) integrated into multistep agent systems enable complex decision-making processes across various applications. However, their outputs often lack reliability, making uncertainty estimation crucial. Existing uncertainty estimation methods primarily focus on final-step outputs, which fail to account for cumulative uncertainty over the multistep decision-making process and the dynamic interactions between agents and their environments. To address these limitations, we propose SAUP (Situation Awareness Uncertainty Propagation), a novel framework that propagates uncertainty through each step of an LLM-based agent's reasoning process. SAUP incorporates situational awareness by assigning situational weights to each step's uncertainty during the propagation. Our method, compatible with various one-step uncertainty estimation techniques, provides a comprehensive and accurate uncertainty measure. Extensive experiments on benchmark datasets demonstrate that SAUP significantly outperforms existing state-of-the-art methods, achieving up to 20% improvement in AUROC.
Uncertainty Decomposition and Quantification for In-Context Learning of Large Language Models
Feb 15, 2024
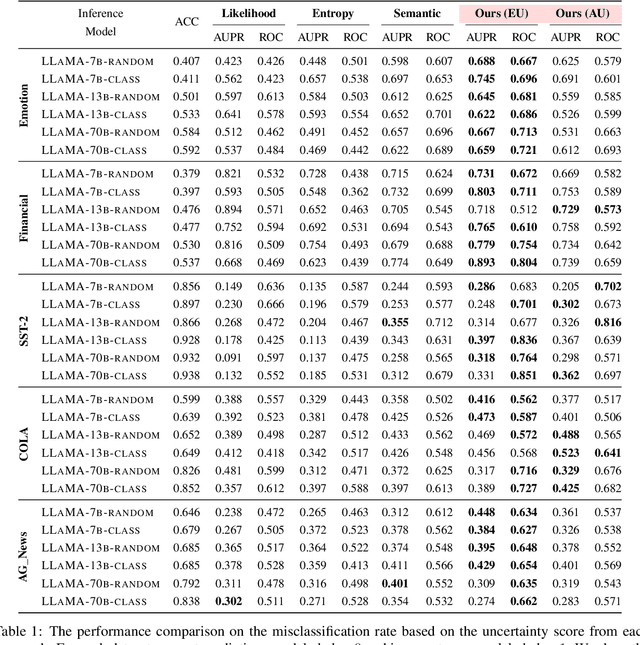
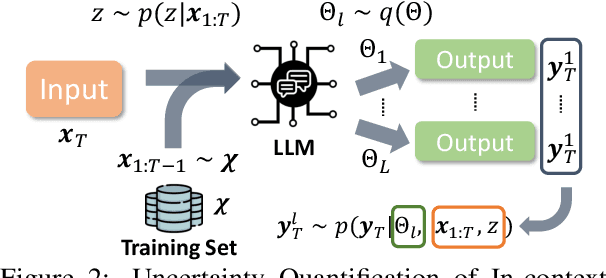
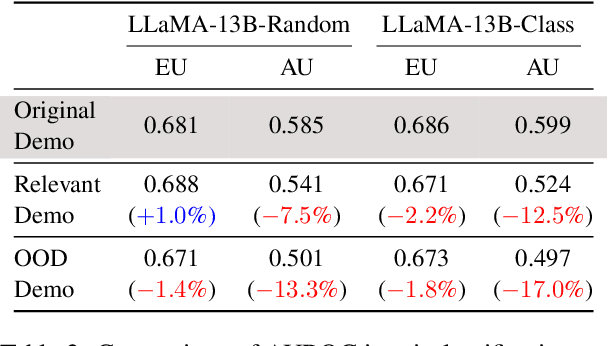
In-context learning has emerged as a groundbreaking ability of Large Language Models (LLMs) and revolutionized various fields by providing a few task-relevant demonstrations in the prompt. However, trustworthy issues with LLM's response, such as hallucination, have also been actively discussed. Existing works have been devoted to quantifying the uncertainty in LLM's response, but they often overlook the complex nature of LLMs and the uniqueness of in-context learning. In this work, we delve into the predictive uncertainty of LLMs associated with in-context learning, highlighting that such uncertainties may stem from both the provided demonstrations (aleatoric uncertainty) and ambiguities tied to the model's configurations (epistemic uncertainty). We propose a novel formulation and corresponding estimation method to quantify both types of uncertainties. The proposed method offers an unsupervised way to understand the prediction of in-context learning in a plug-and-play fashion. Extensive experiments are conducted to demonstrate the effectiveness of the decomposition. The code and data are available at: \url{https://github.com/lingchen0331/UQ_ICL}.
Open-ended Commonsense Reasoning with Unrestricted Answer Scope
Oct 27, 2023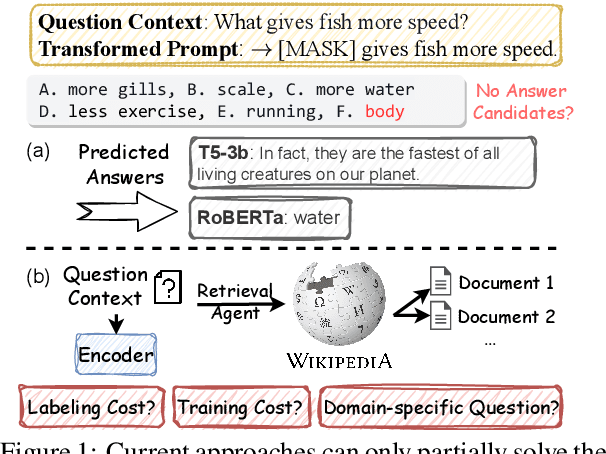
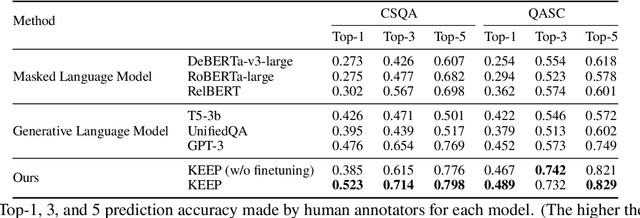
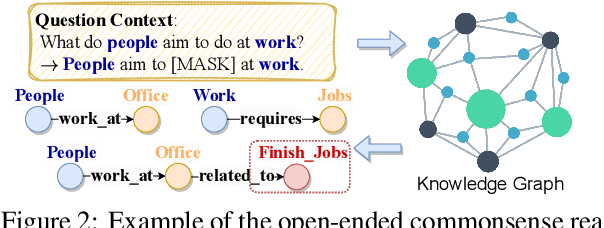
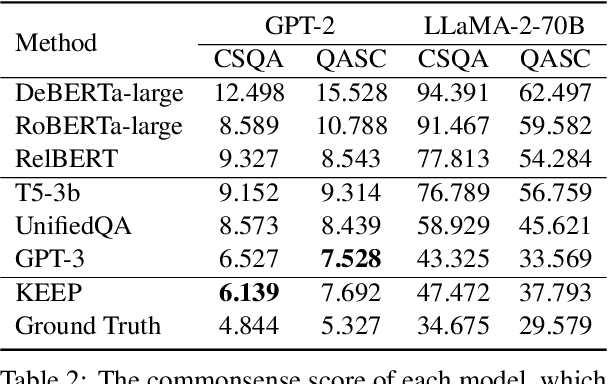
Open-ended Commonsense Reasoning is defined as solving a commonsense question without providing 1) a short list of answer candidates and 2) a pre-defined answer scope. Conventional ways of formulating the commonsense question into a question-answering form or utilizing external knowledge to learn retrieval-based methods are less applicable in the open-ended setting due to an inherent challenge. Without pre-defining an answer scope or a few candidates, open-ended commonsense reasoning entails predicting answers by searching over an extremely large searching space. Moreover, most questions require implicit multi-hop reasoning, which presents even more challenges to our problem. In this work, we leverage pre-trained language models to iteratively retrieve reasoning paths on the external knowledge base, which does not require task-specific supervision. The reasoning paths can help to identify the most precise answer to the commonsense question. We conduct experiments on two commonsense benchmark datasets. Compared to other approaches, our proposed method achieves better performance both quantitatively and qualitatively.
Improving Open Information Extraction with Large Language Models: A Study on Demonstration Uncertainty
Sep 07, 2023Open Information Extraction (OIE) task aims at extracting structured facts from unstructured text, typically in the form of (subject, relation, object) triples. Despite the potential of large language models (LLMs) like ChatGPT as a general task solver, they lag behind state-of-the-art (supervised) methods in OIE tasks due to two key issues. First, LLMs struggle to distinguish irrelevant context from relevant relations and generate structured output due to the restrictions on fine-tuning the model. Second, LLMs generates responses autoregressively based on probability, which makes the predicted relations lack confidence. In this paper, we assess the capabilities of LLMs in improving the OIE task. Particularly, we propose various in-context learning strategies to enhance LLM's instruction-following ability and a demonstration uncertainty quantification module to enhance the confidence of the generated relations. Our experiments on three OIE benchmark datasets show that our approach holds its own against established supervised methods, both quantitatively and qualitatively.