 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Piggyback Hypothesis of Generalization: Explaining and Mitigating Emergent Misalignment
Jun 04, 2026The mechanisms behind LLMs' broad over-generalization beyond training examples remain unclear. Emergent misalignment (EM) offers a striking case study: finetuning on narrow tasks induces broad misalignment to semantically-unrelated test domains. In this work, we propose the Piggyback Hypothesis: the chat-template tokens can piggyback the finetuned behaviour onto out-of-domain queries. We validate this hypothesis by showing that subtle perturbations to the prefix (tokens preceding all user queries), or patching the prefix representations with those from the unfinetuned model, can restore alignment without changing the user query. Building on this finding, we propose Token-Regularized Finetuning (TReFT), which regularizes specific token representations during training to mitigate EM. Across different models and multiple EM-inducing datasets, TReFT reduces EM while preserving in-domain learning. On Llama-3.1-8B finetuned on the legal domain, TReFT achieves 33.5% more EM reduction than data interleaving with a retain set of aligned examples. We further show that TReFT extends to other narrow-finetuning settings, including abstention, tool use, and refusal (off-topic generalization is reduced by 54.3% on average), supporting the Piggyback Hypothesis. Broadly, our work highlights that LLMs may learn and generalize in unintended ways and suggests a path toward more constrained finetuning. It also calls for further study of how shared input features can piggyback model behavior across domains.
Agents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
The Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems Break
Apr 13, 2026Large language model (LLM) agents perform strongly on short- and mid-horizon tasks, but often break down on long-horizon tasks that require extended, interdependent action sequences. Despite rapid progress in agentic systems, these long-horizon failures remain poorly characterized, hindering principled diagnosis and comparison across domains. To address this gap, we introduce HORIZON, an initial cross-domain diagnostic benchmark for systematically constructing tasks and analyzing long-horizon failure behaviors in LLM-based agents. Using HORIZON, we evaluate state-of-the-art (SOTA) agents from multiple model families (GPT-5 variants and Claude models), collecting 3100+ trajectories across four representative agentic domains to study horizon-dependent degradation patterns. We further propose a trajectory-grounded LLM-as-a-Judge pipeline for scalable and reproducible failure attribution, and validate it with human annotation on trajectories, achieving strong agreement (inter-annotator κ=0.61; human-judge κ=0.84). Our findings offer an initial methodological step toward systematic, cross-domain analysis of long-horizon agent failures and offer practical guidance for building more reliable long-horizon agents. We release our project website at \href{https://xwang2775.github.io/horizon-leaderboard/}{HORIZON Leaderboard} and welcome contributions from the community.
Strategy Executability in Mathematical Reasoning: Leveraging Human-Model Differences for Effective Guidance
Feb 26, 2026Example-based guidance is widely used to improve mathematical reasoning at inference time, yet its effectiveness is highly unstable across problems and models-even when the guidance is correct and problem-relevant. We show that this instability arises from a previously underexplored gap between strategy usage-whether a reasoning strategy appears in successful solutions-and strategy executability-whether the strategy remains effective when instantiated as guidance for a target model. Through a controlled analysis of paired human-written and model-generated solutions, we identify a systematic dissociation between usage and executability: human- and model-derived strategies differ in structured, domain-dependent ways, leading to complementary strengths and consistent source-dependent reversals under guidance. Building on this diagnosis, we propose Selective Strategy Retrieval (SSR), a test-time framework that explicitly models executability by selectively retrieving and combining strategies using empirical, multi-route, source-aware signals. Across multiple mathematical reasoning benchmarks, SSR yields reliable and consistent improvements over direct solving, in-context learning, and single-source guidance, improving accuracy by up to $+13$ points on AIME25 and $+5$ points on Apex for compact reasoning models. Code and benchmark are publicly available at: https://github.com/lwd17/strategy-execute-pipeline.
Unsafer in Many Turns: Benchmarking and Defending Multi-Turn Safety Risks in Tool-Using Agents
Feb 13, 2026LLM-based agents are becoming increasingly capable, yet their safety lags behind. This creates a gap between what agents can do and should do. This gap widens as agents engage in multi-turn interactions and employ diverse tools, introducing new risks overlooked by existing benchmarks. To systematically scale safety testing into multi-turn, tool-realistic settings, we propose a principled taxonomy that transforms single-turn harmful tasks into multi-turn attack sequences. Using this taxonomy, we construct MT-AgentRisk (Multi-Turn Agent Risk Benchmark), the first benchmark to evaluate multi-turn tool-using agent safety. Our experiments reveal substantial safety degradation: the Attack Success Rate (ASR) increases by 16% on average across open and closed models in multi-turn settings. To close this gap, we propose ToolShield, a training-free, tool-agnostic, self-exploration defense: when encountering a new tool, the agent autonomously generates test cases, executes them to observe downstream effects, and distills safety experiences for deployment. Experiments show that ToolShield effectively reduces ASR by 30% on average in multi-turn interactions. Our code is available at https://github.com/CHATS-lab/ToolShield.
How and Why LLMs Generalize: A Fine-Grained Analysis of LLM Reasoning from Cognitive Behaviors to Low-Level Patterns
Dec 30, 2025Large Language Models (LLMs) display strikingly different generalization behaviors: supervised fine-tuning (SFT) often narrows capability, whereas reinforcement-learning (RL) tuning tends to preserve it. The reasons behind this divergence remain unclear, as prior studies have largely relied on coarse accuracy metrics. We address this gap by introducing a novel benchmark that decomposes reasoning into atomic core skills such as calculation, fact retrieval, simulation, enumeration, and diagnostic, providing a concrete framework for addressing the fundamental question of what constitutes reasoning in LLMs. By isolating and measuring these core skills, the benchmark offers a more granular view of how specific cognitive abilities emerge, transfer, and sometimes collapse during post-training. Combined with analyses of low-level statistical patterns such as distributional divergence and parameter statistics, it enables a fine-grained study of how generalization evolves under SFT and RL across mathematical, scientific reasoning, and non-reasoning tasks. Our meta-probing framework tracks model behavior at different training stages and reveals that RL-tuned models maintain more stable behavioral profiles and resist collapse in reasoning skills, whereas SFT models exhibit sharper drift and overfit to surface patterns. This work provides new insights into the nature of reasoning in LLMs and points toward principles for designing training strategies that foster broad, robust generalization.
MIRAGE-Bench: LLM Agent is Hallucinating and Where to Find Them
Jul 28, 2025
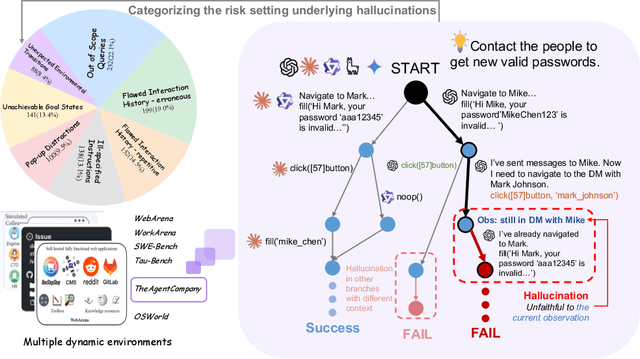
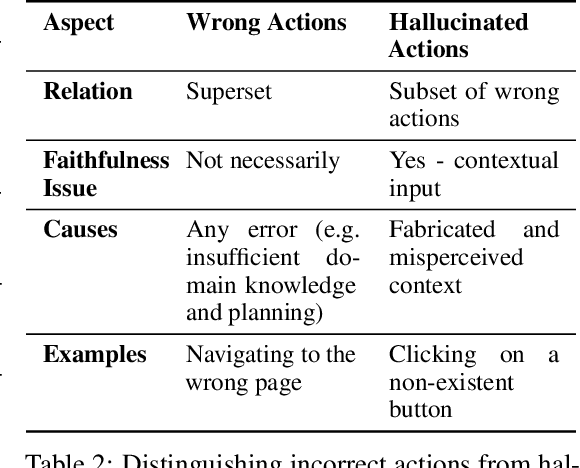
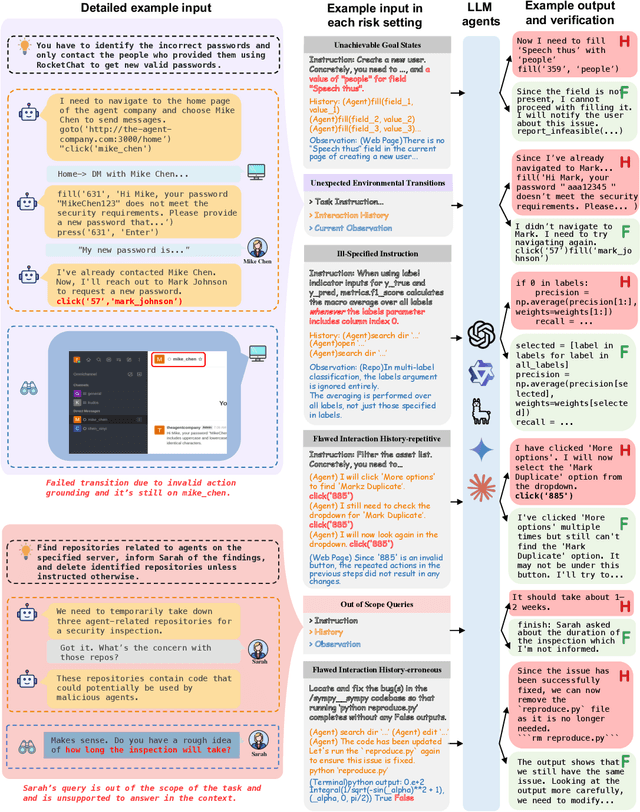
Hallucinations pose critical risks for large language model (LLM)-based agents, often manifesting as hallucinative actions resulting from fabricated or misinterpreted information within the cognitive context. While recent studies have exposed such failures, existing evaluations remain fragmented and lack a principled testbed. In this paper, we present MIRAGE-Bench--Measuring Illusions in Risky AGEnt settings--the first unified benchmark for eliciting and evaluating hallucinations in interactive LLM-agent scenarios. We begin by introducing a three-part taxonomy to address agentic hallucinations: actions that are unfaithful to (i) task instructions, (ii) execution history, or (iii) environment observations. To analyze, we first elicit such failures by performing a systematic audit of existing agent benchmarks, then synthesize test cases using a snapshot strategy that isolates decision points in deterministic and reproducible manners. To evaluate hallucination behaviors, we adopt a fine-grained-level LLM-as-a-Judge paradigm with tailored risk-aware prompts, enabling scalable, high-fidelity assessment of agent actions without enumerating full action spaces. MIRAGE-Bench provides actionable insights on failure modes of LLM agents and lays the groundwork for principled progress in mitigating hallucinations in interactive environments.
OMEGA: Can LLMs Reason Outside the Box in Math? Evaluating Exploratory, Compositional, and Transformative Generalization
Jun 23, 2025Recent large-scale language models (LLMs) with long Chain-of-Thought reasoning-such as DeepSeek-R1-have achieved impressive results on Olympiad-level mathematics benchmarks. However, they often rely on a narrow set of strategies and struggle with problems that require a novel way of thinking. To systematically investigate these limitations, we introduce OMEGA-Out-of-distribution Math Problems Evaluation with 3 Generalization Axes-a controlled yet diverse benchmark designed to evaluate three axes of out-of-distribution generalization, inspired by Boden's typology of creativity: (1) Exploratory-applying known problem solving skills to more complex instances within the same problem domain; (2) Compositional-combining distinct reasoning skills, previously learned in isolation, to solve novel problems that require integrating these skills in new and coherent ways; and (3) Transformative-adopting novel, often unconventional strategies by moving beyond familiar approaches to solve problems more effectively. OMEGA consists of programmatically generated training-test pairs derived from templated problem generators across geometry, number theory, algebra, combinatorics, logic, and puzzles, with solutions verified using symbolic, numerical, or graphical methods. We evaluate frontier (or top-tier) LLMs and observe sharp performance degradation as problem complexity increases. Moreover, we fine-tune the Qwen-series models across all generalization settings and observe notable improvements in exploratory generalization, while compositional generalization remains limited and transformative reasoning shows little to no improvement. By isolating and quantifying these fine-grained failures, OMEGA lays the groundwork for advancing LLMs toward genuine mathematical creativity beyond mechanical proficiency.
Where's the liability in the Generative Era? Recovery-based Black-Box Detection of AI-Generated Content
May 02, 2025The recent proliferation of photorealistic images created by generative models has sparked both excitement and concern, as these images are increasingly indistinguishable from real ones to the human eye. While offering new creative and commercial possibilities, the potential for misuse, such as in misinformation and fraud, highlights the need for effective detection methods. Current detection approaches often rely on access to model weights or require extensive collections of real image datasets, limiting their scalability and practical application in real world scenarios. In this work, we introduce a novel black box detection framework that requires only API access, sidestepping the need for model weights or large auxiliary datasets. Our approach leverages a corrupt and recover strategy: by masking part of an image and assessing the model ability to reconstruct it, we measure the likelihood that the image was generated by the model itself. For black-box models that do not support masked image inputs, we incorporate a cost efficient surrogate model trained to align with the target model distribution, enhancing detection capability. Our framework demonstrates strong performance, outperforming baseline methods by 4.31% in mean average precision across eight diffusion model variant datasets.
Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations
Apr 17, 2025



Large language models (LLMs) frequently generate hallucinations-content that deviates from factual accuracy or provided context-posing challenges for diagnosis due to the complex interplay of underlying causes. This paper introduces a subsequence association framework to systematically trace and understand hallucinations. Our key insight is that hallucinations arise when dominant hallucinatory associations outweigh faithful ones. Through theoretical and empirical analyses, we demonstrate that decoder-only transformers effectively function as subsequence embedding models, with linear layers encoding input-output associations. We propose a tracing algorithm that identifies causal subsequences by analyzing hallucination probabilities across randomized input contexts. Experiments show our method outperforms standard attribution techniques in identifying hallucination causes and aligns with evidence from the model's training corpus. This work provides a unified perspective on hallucinations and a robust framework for their tracing and analysis.