 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Perception to Symbolic Task Planning: Vision-Language Guided Human-Robot Collaborative Structured Assembly
Jan 02, 2026Human-robot collaboration (HRC) in structured assembly requires reliable state estimation and adaptive task planning under noisy perception and human interventions. To address these challenges, we introduce a design-grounded human-aware planning framework for human-robot collaborative structured assembly. The framework comprises two coupled modules. Module I, Perception-to-Symbolic State (PSS), employs vision-language models (VLMs) based agents to align RGB-D observations with design specifications and domain knowledge, synthesizing verifiable symbolic assembly states. It outputs validated installed and uninstalled component sets for online state tracking. Module II, Human-Aware Planning and Replanning (HPR), performs task-level multi-robot assignment and updates the plan only when the observed state deviates from the expected execution outcome. It applies a minimal-change replanning rule to selectively revise task assignments and preserve plan stability even under human interventions. We validate the framework on a 27-component timber-frame assembly. The PSS module achieves 97% state synthesis accuracy, and the HPR module maintains feasible task progression across diverse HRC scenarios. Results indicate that integrating VLM-based perception with knowledge-driven planning improves robustness of state estimation and task planning under dynamic conditions.
Robust Semi-supervised Multimodal Medical Image Segmentation via Cross Modality Collaboration
Aug 14, 2024



Multimodal learning leverages complementary information derived from different modalities, thereby enhancing performance in medical image segmentation. However, prevailing multimodal learning methods heavily rely on extensive well-annotated data from various modalities to achieve accurate segmentation performance. This dependence often poses a challenge in clinical settings due to limited availability of such data. Moreover, the inherent anatomical misalignment between different imaging modalities further complicates the endeavor to enhance segmentation performance. To address this problem, we propose a novel semi-supervised multimodal segmentation framework that is robust to scarce labeled data and misaligned modalities. Our framework employs a novel cross modality collaboration strategy to distill modality-independent knowledge, which is inherently associated with each modality, and integrates this information into a unified fusion layer for feature amalgamation. With a channel-wise semantic consistency loss, our framework ensures alignment of modality-independent information from a feature-wise perspective across modalities, thereby fortifying it against misalignments in multimodal scenarios. Furthermore, our framework effectively integrates contrastive consistent learning to regulate anatomical structures, facilitating anatomical-wise prediction alignment on unlabeled data in semi-supervised segmentation tasks. Our method achieves competitive performance compared to other multimodal methods across three tasks: cardiac, abdominal multi-organ, and thyroid-associated orbitopathy segmentations. It also demonstrates outstanding robustness in scenarios involving scarce labeled data and misaligned modalities.
Unsupervised domain adaptation semantic segmentation of high-resolution remote sensing imagery with invariant domain-level context memory
Aug 16, 2022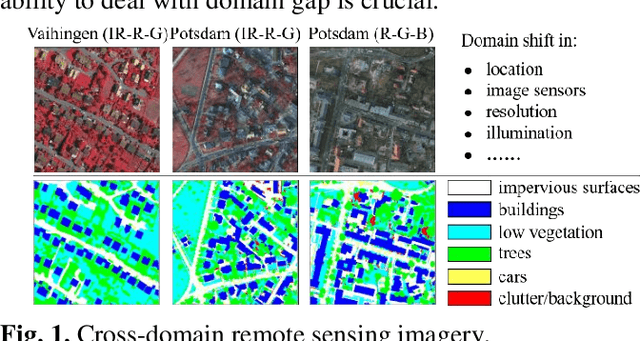
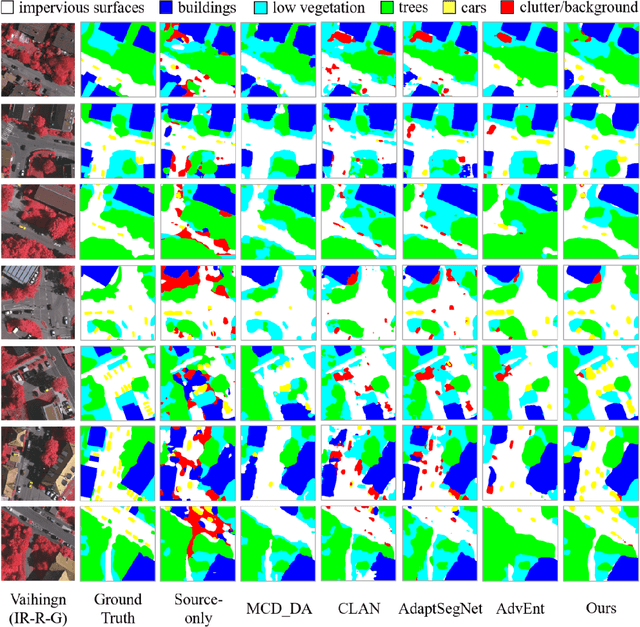
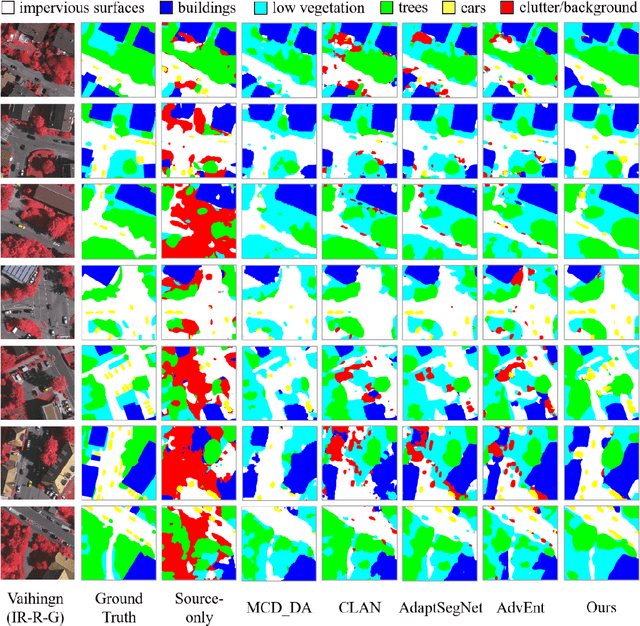
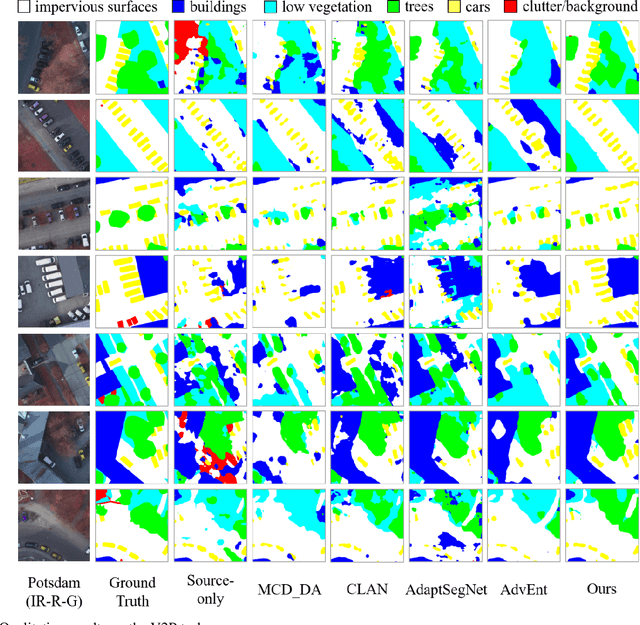
Semantic segmentation is a key technique involved in automatic interpretation of high-resolution remote sensing (HRS) imagery and has drawn much attention in the remote sensing community. Deep convolutional neural networks (DCNNs) have been successfully applied to the HRS imagery semantic segmentation task due to their hierarchical representation ability. However, the heavy dependency on a large number of training data with dense annotation and the sensitiveness to the variation of data distribution severely restrict the potential application of DCNNs for the semantic segmentation of HRS imagery. This study proposes a novel unsupervised domain adaptation semantic segmentation network (MemoryAdaptNet) for the semantic segmentation of HRS imagery. MemoryAdaptNet constructs an output space adversarial learning scheme to bridge the domain distribution discrepancy between source domain and target domain and to narrow the influence of domain shift. Specifically, we embed an invariant feature memory module to store invariant domain-level context information because the features obtained from adversarial learning only tend to represent the variant feature of current limited inputs. This module is integrated by a category attention-driven invariant domain-level context aggregation module to current pseudo invariant feature for further augmenting the pixel representations. An entropy-based pseudo label filtering strategy is used to update the memory module with high-confident pseudo invariant feature of current target images. Extensive experiments under three cross-domain tasks indicate that our proposed MemoryAdaptNet is remarkably superior to the state-of-the-art methods.
Learning by Active Forgetting for Neural Networks
Nov 21, 2021
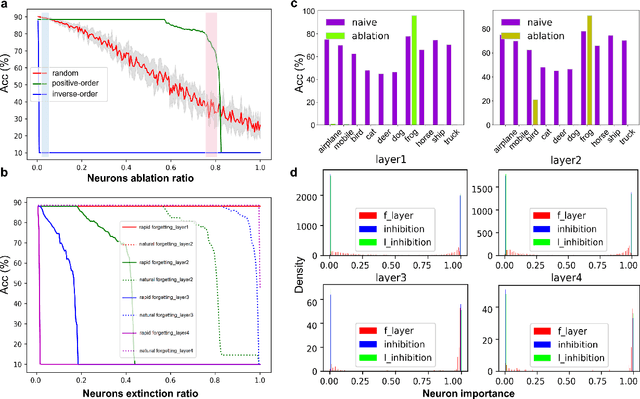
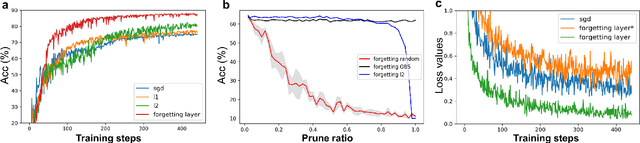
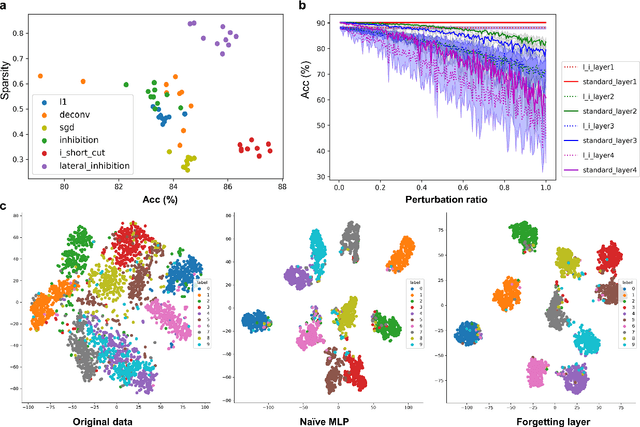
Remembering and forgetting mechanisms are two sides of the same coin in a human learning-memory system. Inspired by human brain memory mechanisms, modern machine learning systems have been working to endow machine with lifelong learning capability through better remembering while pushing the forgetting as the antagonist to overcome. Nevertheless, this idea might only see the half picture. Up until very recently, increasing researchers argue that a brain is born to forget, i.e., forgetting is a natural and active process for abstract, rich, and flexible representations. This paper presents a learning model by active forgetting mechanism with artificial neural networks. The active forgetting mechanism (AFM) is introduced to a neural network via a "plug-and-play" forgetting layer (P\&PF), consisting of groups of inhibitory neurons with Internal Regulation Strategy (IRS) to adjust the extinction rate of themselves via lateral inhibition mechanism and External Regulation Strategy (ERS) to adjust the extinction rate of excitatory neurons via inhibition mechanism. Experimental studies have shown that the P\&PF offers surprising benefits: self-adaptive structure, strong generalization, long-term learning and memory, and robustness to data and parameter perturbation. This work sheds light on the importance of forgetting in the learning process and offers new perspectives to understand the underlying mechanisms of neural networks.
Bottom-up mechanism and improved contract net protocol for the dynamic task planning of heterogeneous Earth observation resources
Jul 13, 2020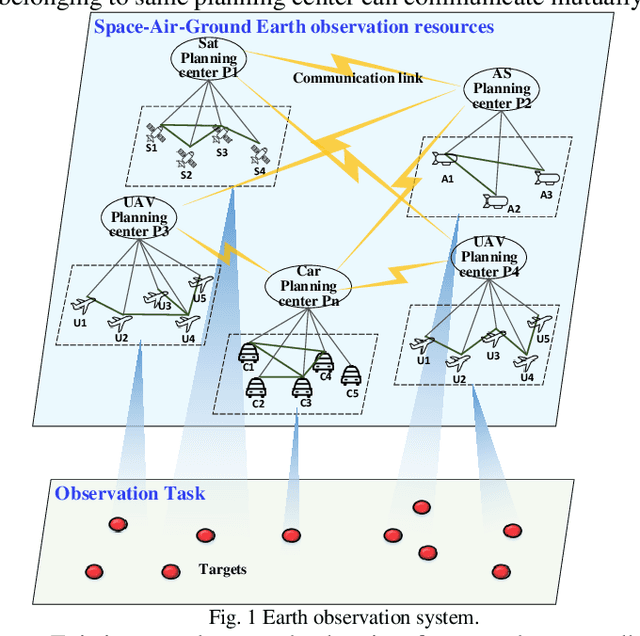
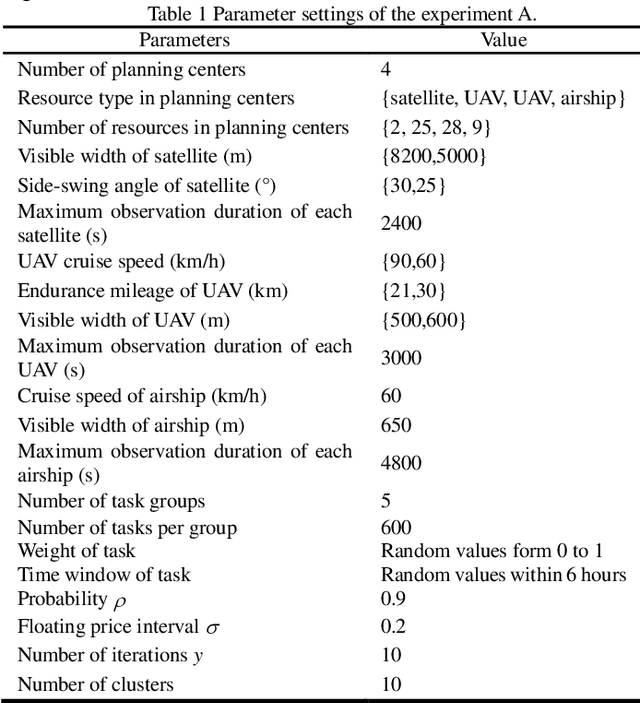
Earth observation resources are becoming increasingly indispensable in disaster relief, damage assessment and related domains. Many unpredicted factors, such as the change of observation task requirements, to the occurring of bad weather and resource failures, may cause the scheduled observation scheme to become infeasible. Therefore, it is crucial to be able to promptly and maybe frequently develop high-quality replanned observation schemes that minimize the effects on the scheduled tasks. A bottom-up distributed coordinated framework together with an improved contract net are proposed to facilitate the dynamic task replanning for heterogeneous Earth observation resources. This hierarchical framework consists of three levels, namely, neighboring resource coordination, single planning center coordination, and multiple planning center coordination. Observation tasks affected by unpredicted factors are assigned and treated along with a bottom-up route from resources to planning centers. This bottom-up distributed coordinated framework transfers part of the computing load to various nodes of the observation systems to allocate tasks more efficiently and robustly. To support the prompt assignment of large-scale tasks to proper Earth observation resources in dynamic environments, we propose a multiround combinatorial allocation (MCA) method. Moreover, a new float interval-based local search algorithm is proposed to obtain the promising planning scheme more quickly. The experiments demonstrate that the MCA method can achieve a better task completion rate for large-scale tasks with satisfactory time efficiency. It also demonstrates that this method can help to efficiently obtain replanning schemes based on original scheme in dynamic environments.
Temporal Graph Convolutional Network for Urban Traffic Flow Prediction Method
Dec 05, 2018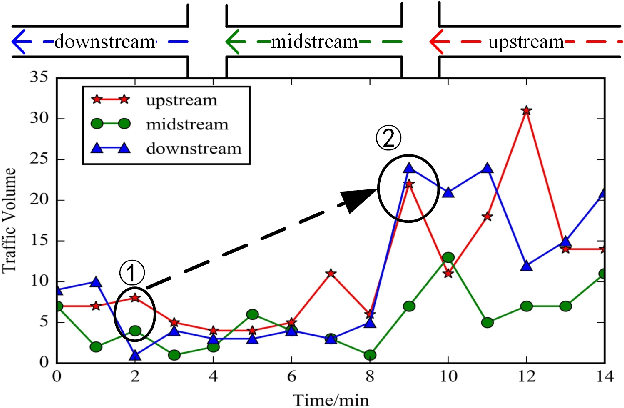
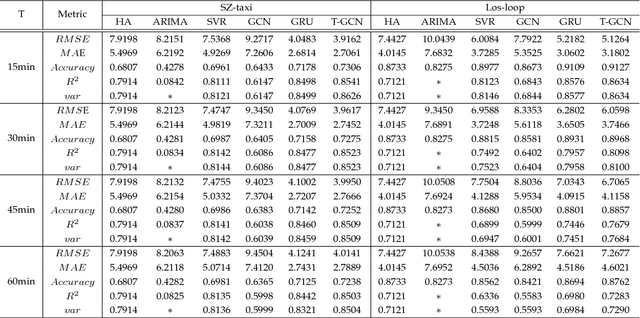
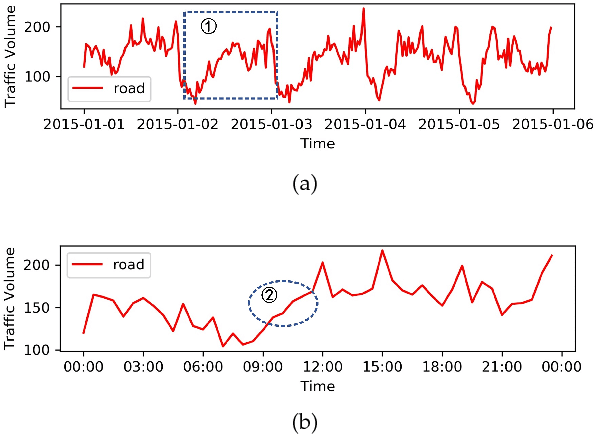
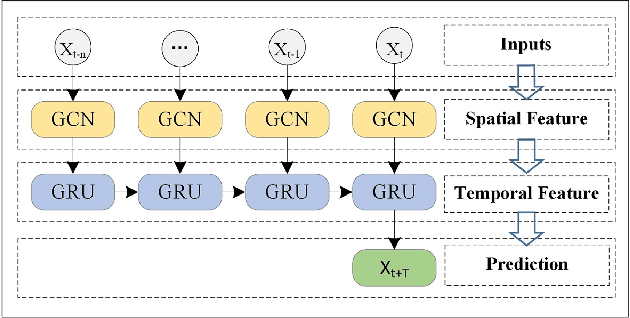
Accurate and real-time traffic forecasting plays an important role in the Intelligent Traffic System (ITS) and is of great significance for urban traffic planning, traffic management, and traffic control. However, traffic forecasting has always been considered an open scientific issue, owing to the constraints of urban road network topological structure and the law of dynamic change with time, namely, spatial dependence and temporal dependence. To capture the spatial and temporal dependences simultaneously, we propose a novel neural network-based traffic forecasting method, the temporal graph convolutional network (T-GCN) model, which is in combination with the graph convolutional network (GCN) and gated recurrent unit (GRU). Specifically, the graph convolutional network is used to learn complex topological structures to capture the spatial dependence and the gated recurrent unit is used to learn dynamic changes of traffic flow to capture the temporal dependence. Then, the T-GCN model is employed to forecast traffic based on the urban road network. Experiments demonstrate that our T-GCN model can obtain the spatiotemporal correlation from traffic data and the predictions outperform state-of-art baselines on real-world traffic datasets. Our tensorflow implementation of T-GCN is available at https://github.com/lehaifeng/T-GCN.
Learning to Measure Change: Fully Convolutional Siamese Metric Networks for Scene Change Detection
Nov 02, 2018


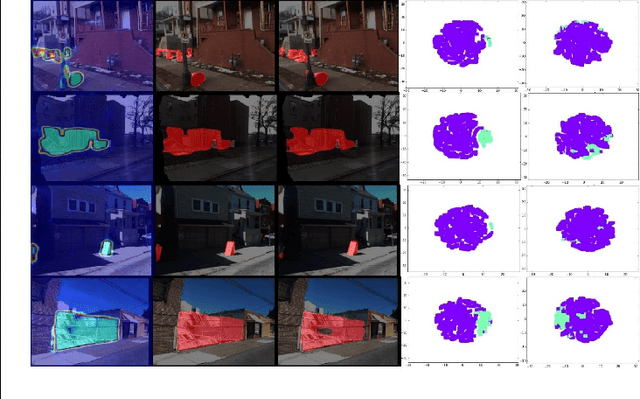
Following the intuitive idea of detecting changes by directly comparing dissimilarity between a pair of images, we propose a novel Fully Convolutional siamese metric Network (CosimNet) to measure changes by customizing implicit metric. To learn more discriminative metrics, we utilize contrastive loss to reduce the distance between the unchanged feature pair and enlarge the distance between changed feature pair. Specially, to address the issue of large viewpoint difference, we propose Thresholded Contrastive Loss (TCL) with more tolerance strategy to punish this noisy change. We demonstrate the effectiveness of the proposed approach with experiments on three challenging datasets including CDnet, PCD2015, and VL-CMU-CD. Source code is available at https://github.com/gmayday1997/ChangeDet.
On the Selective and Invariant Representation of DCNN for High-Resolution Remote Sensing Image Recognition
Aug 04, 2017
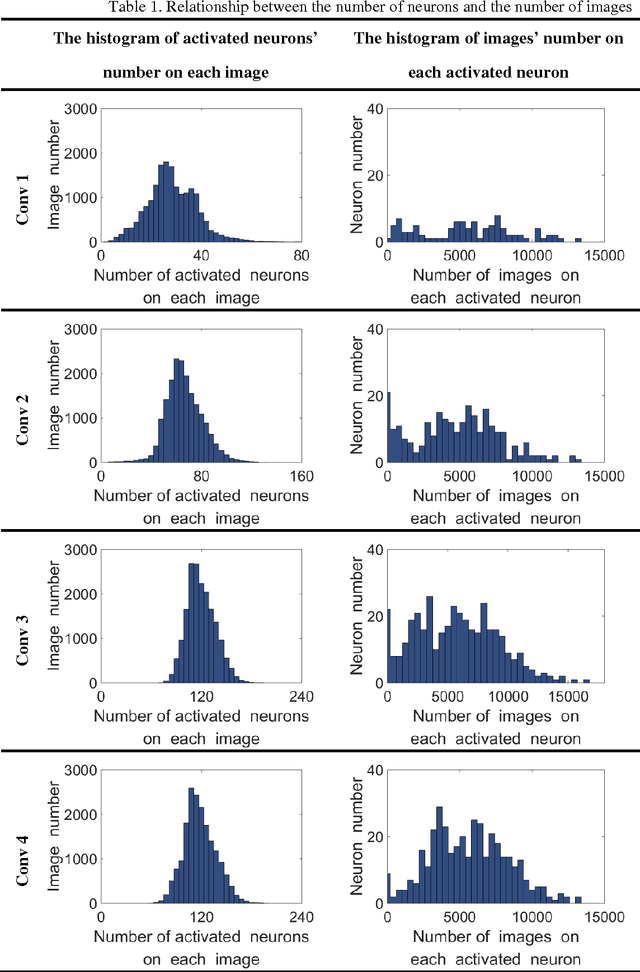
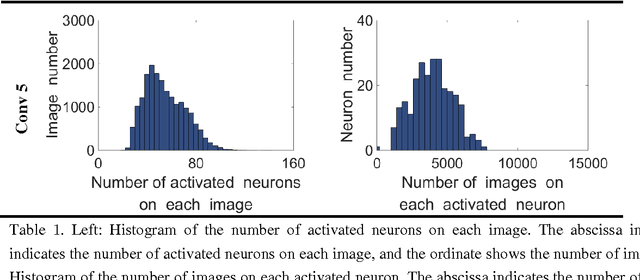
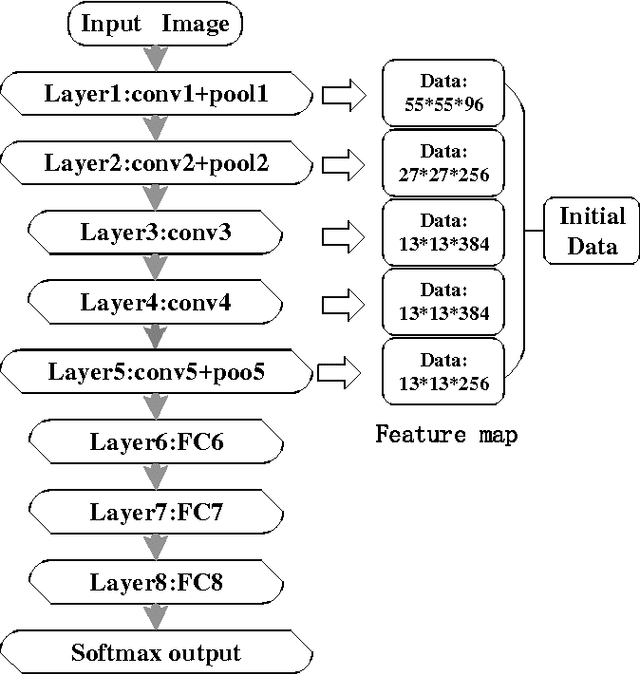
Human vision possesses strong invariance in image recognition. The cognitive capability of deep convolutional neural network (DCNN) is close to the human visual level because of hierarchical coding directly from raw image. Owing to its superiority in feature representation, DCNN has exhibited remarkable performance in scene recognition of high-resolution remote sensing (HRRS) images and classification of hyper-spectral remote sensing images. In-depth investigation is still essential for understanding why DCNN can accurately identify diverse ground objects via its effective feature representation. Thus, we train the deep neural network called AlexNet on our large scale remote sensing image recognition benchmark. At the neuron level in each convolution layer, we analyze the general properties of DCNN in HRRS image recognition by use of a framework of visual stimulation-characteristic response combined with feature coding-classification decoding. Specifically, we use histogram statistics, representational dissimilarity matrix, and class activation mapping to observe the selective and invariance representations of DCNN in HRRS image recognition. We argue that selective and invariance representations play important roles in remote sensing images tasks, such as classification, detection, and segment. Also selective and invariance representations are significant to design new DCNN liked models for analyzing and understanding remote sensing images.
RSI-CB: A Large Scale Remote Sensing Image Classification Benchmark via Crowdsource Data
Jun 11, 2017
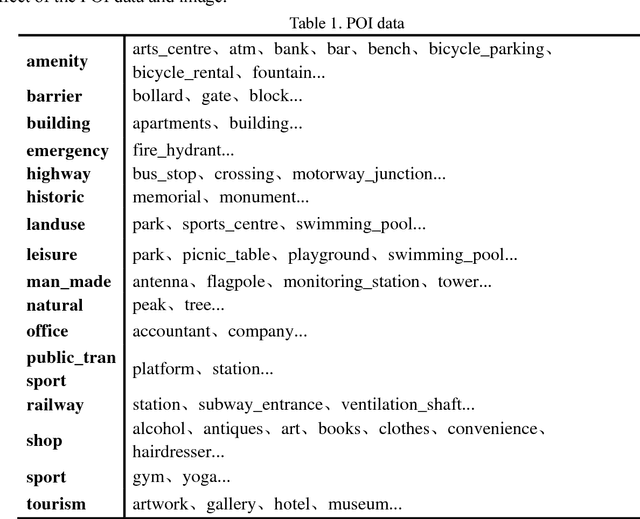

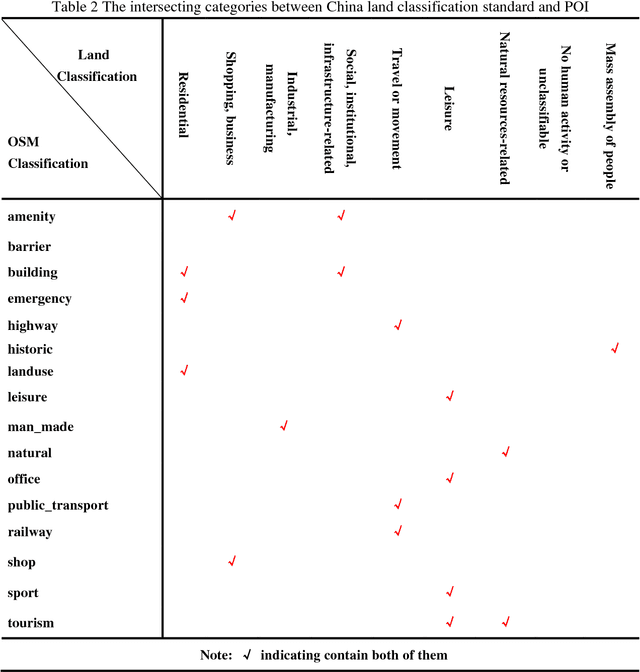
Remote sensing image classification is a fundamental task in remote sensing image processing. Remote sensing field still lacks of such a large-scale benchmark compared to ImageNet, Place2. We propose a remote sensing image classification benchmark (RSI-CB) based on crowd-source data which is massive, scalable, and diversity. Using crowdsource data, we can efficiently annotate ground objects in remotes sensing image by point of interests, vectors data from OSM or other crowd-source data. Based on this method, we construct a worldwide large-scale benchmark for remote sensing image classification. In this benchmark, there are two sub datasets with 256 * 256 and 128 * 128 size respectively since different convolution neural networks requirement different image size. The former sub dataset contains 6 categories with 35 subclasses with total of more than 24,000 images; the later one contains 6 categories with 45 subclasses with total of more than 36,000 images. The six categories are agricultural land, construction land and facilities, transportation and facilities, water and water conservancy facilities, woodland and other land, and each category has several subclasses. This classification system is defined according to the national standard of land use classification in China, and is inspired by the hierarchy mechanism of ImageNet. Finally, we have done a large number of experiments to compare RSI-CB with SAT-4, UC-Merced datasets on handcrafted features, such as such as SIFT, and classical CNN models, such as AlexNet, VGG, GoogleNet, and ResNet. We also show CNN models trained by RSI-CB have good performance when transfer to other dataset, i.e. UC-Merced, and good generalization ability. The experiments show that RSI-CB is more suitable as a benchmark for remote sensing image classification task than other ones in big data era, and can be potentially used in practical applications.
What do We Learn by Semantic Scene Understanding for Remote Sensing imagery in CNN framework?
May 19, 2017
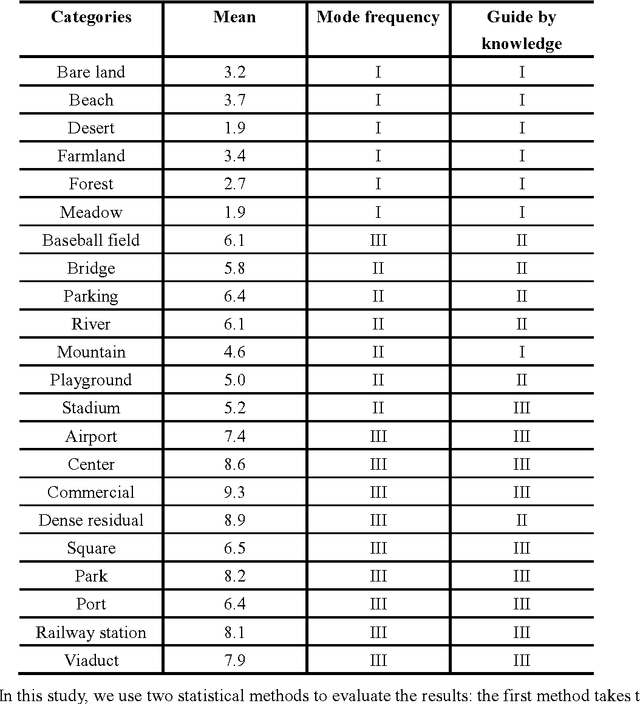
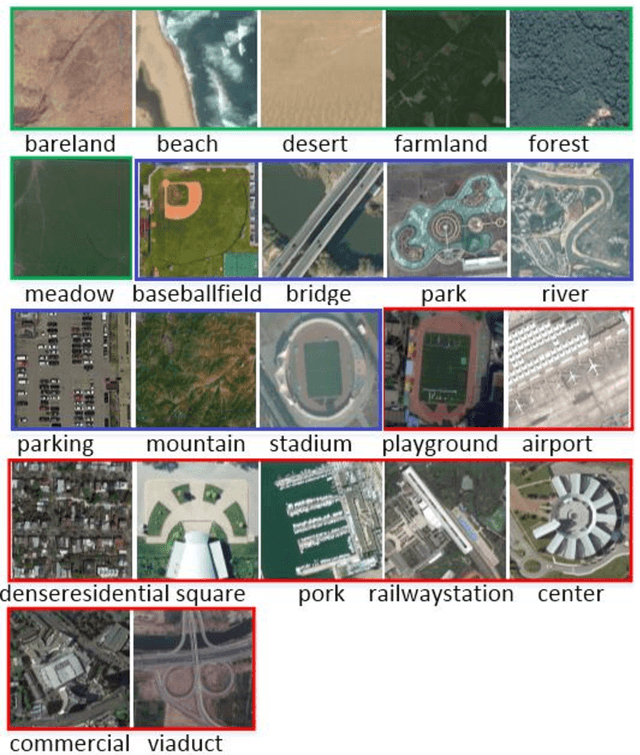

Recently, deep convolutional neural network (DCNN) achieved increasingly remarkable success and rapidly developed in the field of natural image recognition. Compared with the natural image, the scale of remote sensing image is larger and the scene and the object it represents are more macroscopic. This study inquires whether remote sensing scene and natural scene recognitions differ and raises the following questions: What are the key factors in remote sensing scene recognition? Is the DCNN recognition mechanism centered on object recognition still applicable to the scenarios of remote sensing scene understanding? We performed several experiments to explore the influence of the DCNN structure and the scale of remote sensing scene understanding from the perspective of scene complexity. Our experiment shows that understanding a complex scene depends on an in-depth network and multiple-scale perception. Using a visualization method, we qualitatively and quantitatively analyze the recognition mechanism in a complex remote sensing scene and demonstrate the importance of multi-objective joint semantic support.