 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025



The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.
LLM-based Evaluation Policy Extraction for Ecological Modeling
May 20, 2025Evaluating ecological time series is critical for benchmarking model performance in many important applications, including predicting greenhouse gas fluxes, capturing carbon-nitrogen dynamics, and monitoring hydrological cycles. Traditional numerical metrics (e.g., R-squared, root mean square error) have been widely used to quantify the similarity between modeled and observed ecosystem variables, but they often fail to capture domain-specific temporal patterns critical to ecological processes. As a result, these methods are often accompanied by expert visual inspection, which requires substantial human labor and limits the applicability to large-scale evaluation. To address these challenges, we propose a novel framework that integrates metric learning with large language model (LLM)-based natural language policy extraction to develop interpretable evaluation criteria. The proposed method processes pairwise annotations and implements a policy optimization mechanism to generate and combine different assessment metrics. The results obtained on multiple datasets for evaluating the predictions of crop gross primary production and carbon dioxide flux have confirmed the effectiveness of the proposed method in capturing target assessment preferences, including both synthetically generated and expert-annotated model comparisons. The proposed framework bridges the gap between numerical metrics and expert knowledge while providing interpretable evaluation policies that accommodate the diverse needs of different ecosystem modeling studies.
Exploring Generalizable Pre-training for Real-world Change Detection via Geometric Estimation
Apr 19, 2025As an essential procedure in earth observation system, change detection (CD) aims to reveal the spatial-temporal evolution of the observation regions. A key prerequisite for existing change detection algorithms is aligned geo-references between multi-temporal images by fine-grained registration. However, in the majority of real-world scenarios, a prior manual registration is required between the original images, which significantly increases the complexity of the CD workflow. In this paper, we proposed a self-supervision motivated CD framework with geometric estimation, called "MatchCD". Specifically, the proposed MatchCD framework utilizes the zero-shot capability to optimize the encoder with self-supervised contrastive representation, which is reused in the downstream image registration and change detection to simultaneously handle the bi-temporal unalignment and object change issues. Moreover, unlike the conventional change detection requiring segmenting the full-frame image into small patches, our MatchCD framework can directly process the original large-scale image (e.g., 6K*4K resolutions) with promising performance. The performance in multiple complex scenarios with significant geometric distortion demonstrates the effectiveness of our proposed framework.
Multiview Point Cloud Registration Based on Minimum Potential Energy for Free-Form Blade Measurement
Feb 11, 2025Point cloud registration is an essential step for free-form blade reconstruction in industrial measurement. Nonetheless, measuring defects of the 3D acquisition system unavoidably result in noisy and incomplete point cloud data, which renders efficient and accurate registration challenging. In this paper, we propose a novel global registration method that is based on the minimum potential energy (MPE) method to address these problems. The basic strategy is that the objective function is defined as the minimum potential energy optimization function of the physical registration system. The function distributes more weight to the majority of inlier points and less weight to the noise and outliers, which essentially reduces the influence of perturbations in the mathematical formulation. We decompose the solution into a globally optimal approximation procedure and a fine registration process with the trimmed iterative closest point algorithm to boost convergence. The approximation procedure consists of two main steps. First, according to the construction of the force traction operator, we can simply compute the position of the potential energy minimum. Second, to find the MPE point, we propose a new theory that employs two flags to observe the status of the registration procedure. We demonstrate the performance of the proposed algorithm on four types of blades. The proposed method outperforms the other global methods in terms of both accuracy and noise resistance.
Localization, balance and affinity: a stronger multifaceted collaborative salient object detector in remote sensing images
Oct 31, 2024


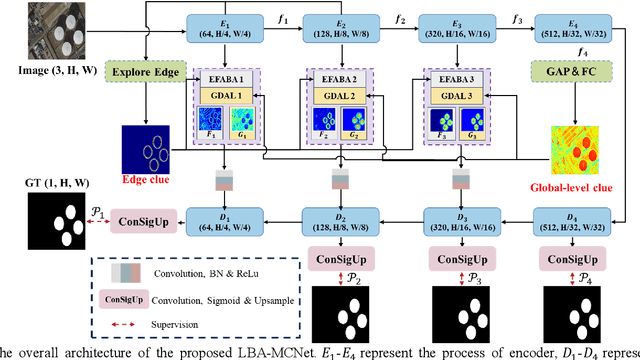
Despite significant advancements in salient object detection(SOD) in optical remote sensing images(ORSI), challenges persist due to the intricate edge structures of ORSIs and the complexity of their contextual relationships. Current deep learning approaches encounter difficulties in accurately identifying boundary features and lack efficiency in collaboratively modeling the foreground and background by leveraging contextual features. To address these challenges, we propose a stronger multifaceted collaborative salient object detector in ORSIs, termed LBA-MCNet, which incorporates aspects of localization, balance, and affinity. The network focuses on accurately locating targets, balancing detailed features, and modeling image-level global context information. Specifically, we design the Edge Feature Adaptive Balancing and Adjusting(EFABA) module for precise edge localization, using edge features to guide attention to boundaries and preserve spatial details. Moreover, we design the Global Distributed Affinity Learning(GDAL) module to model global context. It captures global context by generating an affinity map from the encoders final layer, ensuring effective modeling of global patterns. Additionally, deep supervision during deconvolution further enhances feature representation. Finally, we compared with 28 state of the art approaches on three publicly available datasets. The results clearly demonstrate the superiority of our method.
Daily Physical Activity Monitoring -- Adaptive Learning from Multi-source Motion Sensor Data
May 26, 2024



In healthcare applications, there is a growing need to develop machine learning models that use data from a single source, such as that from a wrist wearable device, to monitor physical activities, assess health risks, and provide immediate health recommendations or interventions. However, the limitation of using single-source data often compromises the model's accuracy, as it fails to capture the full scope of human activities. While a more comprehensive dataset can be gathered in a lab setting using multiple sensors attached to various body parts, this approach is not practical for everyday use due to the impracticality of wearing multiple sensors. To address this challenge, we introduce a transfer learning framework that optimizes machine learning models for everyday applications by leveraging multi-source data collected in a laboratory setting. We introduce a novel metric to leverage the inherent relationship between these multiple data sources, as they are all paired to capture aspects of the same physical activity. Through numerical experiments, our framework outperforms existing methods in classification accuracy and robustness to noise, offering a promising avenue for the enhancement of daily activity monitoring.
3D Object Detection from Point Cloud via Voting Step Diffusion
Mar 21, 2024



3D object detection is a fundamental task in scene understanding. Numerous research efforts have been dedicated to better incorporate Hough voting into the 3D object detection pipeline. However, due to the noisy, cluttered, and partial nature of real 3D scans, existing voting-based methods often receive votes from the partial surfaces of individual objects together with severe noises, leading to sub-optimal detection performance. In this work, we focus on the distributional properties of point clouds and formulate the voting process as generating new points in the high-density region of the distribution of object centers. To achieve this, we propose a new method to move random 3D points toward the high-density region of the distribution by estimating the score function of the distribution with a noise conditioned score network. Specifically, we first generate a set of object center proposals to coarsely identify the high-density region of the object center distribution. To estimate the score function, we perturb the generated object center proposals by adding normalized Gaussian noise, and then jointly estimate the score function of all perturbed distributions. Finally, we generate new votes by moving random 3D points to the high-density region of the object center distribution according to the estimated score function. Extensive experiments on two large scale indoor 3D scene datasets, SUN RGB-D and ScanNet V2, demonstrate the superiority of our proposed method. The code will be released at https://github.com/HHrEtvP/DiffVote.
AllSpark: a multimodal spatiotemporal general model
Dec 31, 2023



For a long time, due to the high heterogeneity in structure and semantics among various spatiotemporal modal data, the joint interpretation of multimodal spatiotemporal data has been an extremely challenging problem. The primary challenge resides in striking a trade-off between the cohesion and autonomy of diverse modalities, and this trade-off exhibits a progressively nonlinear nature as the number of modalities expands. We introduce the Language as Reference Framework (LaRF), a fundamental principle for constructing a multimodal unified model, aiming to strike a trade-off between the cohesion and autonomy among different modalities. We propose a multimodal spatiotemporal general artificial intelligence model, called AllSpark. Our model integrates thirteen different modalities into a unified framework, including 1D (text, code), 2D (RGB, infrared, SAR, multispectral, hyperspectral, tables, graphs, trajectory, oblique photography), and 3D (point clouds, videos) modalities. To achieve modal cohesion, AllSpark uniformly maps diverse modal features to the language modality. In addition, we design modality-specific prompts to guide multi-modal large language models in accurately perceiving multimodal data. To maintain modality autonomy, AllSpark introduces modality-specific encoders to extract the tokens of various spatiotemporal modalities. And modal bridge is employed to achieve dimensional projection from each modality to the language modality. Finally, observing a gap between the model's interpretation and downstream tasks, we designed task heads to enhance the model's generalization capability on specific downstream tasks. Experiments indicate that AllSpark achieves competitive accuracy in modalities such as RGB and trajectory compared to state-of-the-art models.
Machine Learning Driven Sensitivity Analysis of E3SM Land Model Parameters for Wetland Methane Emissions
Dec 05, 2023Methane (CH4) is the second most critical greenhouse gas after carbon dioxide, contributing to 16-25% of the observed atmospheric warming. Wetlands are the primary natural source of methane emissions globally. However, wetland methane emission estimates from biogeochemistry models contain considerable uncertainty. One of the main sources of this uncertainty arises from the numerous uncertain model parameters within various physical, biological, and chemical processes that influence methane production, oxidation, and transport. Sensitivity Analysis (SA) can help identify critical parameters for methane emission and achieve reduced biases and uncertainties in future projections. This study performs SA for 19 selected parameters responsible for critical biogeochemical processes in the methane module of the Energy Exascale Earth System Model (E3SM) land model (ELM). The impact of these parameters on various CH4 fluxes is examined at 14 FLUXNET- CH4 sites with diverse vegetation types. Given the extensive number of model simulations needed for global variance-based SA, we employ a machine learning (ML) algorithm to emulate the complex behavior of ELM methane biogeochemistry. ML enables the computational time to be shortened significantly from 6 CPU hours to 0.72 milliseconds, achieving reduced computational costs. We found that parameters linked to CH4 production and diffusion generally present the highest sensitivities despite apparent seasonal variation. Comparing simulated emissions from perturbed parameter sets against FLUXNET-CH4 observations revealed that better performances can be achieved at each site compared to the default parameter values. This presents a scope for further improving simulated emissions using parameter calibration with advanced optimization techniques like Bayesian optimization.
Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
Oct 06, 2023



Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.