 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Generalizable Pre-training for Real-world Change Detection via Geometric Estimation
Apr 19, 2025As an essential procedure in earth observation system, change detection (CD) aims to reveal the spatial-temporal evolution of the observation regions. A key prerequisite for existing change detection algorithms is aligned geo-references between multi-temporal images by fine-grained registration. However, in the majority of real-world scenarios, a prior manual registration is required between the original images, which significantly increases the complexity of the CD workflow. In this paper, we proposed a self-supervision motivated CD framework with geometric estimation, called "MatchCD". Specifically, the proposed MatchCD framework utilizes the zero-shot capability to optimize the encoder with self-supervised contrastive representation, which is reused in the downstream image registration and change detection to simultaneously handle the bi-temporal unalignment and object change issues. Moreover, unlike the conventional change detection requiring segmenting the full-frame image into small patches, our MatchCD framework can directly process the original large-scale image (e.g., 6K*4K resolutions) with promising performance. The performance in multiple complex scenarios with significant geometric distortion demonstrates the effectiveness of our proposed framework.
SAM-Based Building Change Detection with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping
Apr 17, 2025Building change detection remains challenging for urban development, disaster assessment, and military reconnaissance. While foundation models like Segment Anything Model (SAM) show strong segmentation capabilities, SAM is limited in the task of building change detection due to domain gap issues. Existing adapter-based fine-tuning approaches face challenges with imbalanced building distribution, resulting in poor detection of subtle changes and inaccurate edge extraction. Additionally, bi-temporal misalignment in change detection, typically addressed by optical flow, remains vulnerable to background noises. This affects the detection of building changes and compromises both detection accuracy and edge recognition. To tackle these challenges, we propose a new SAM-Based Network with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping (FAEWNet) for building change detection. FAEWNet utilizes the SAM encoder to extract rich visual features from remote sensing images. To guide SAM in focusing on specific ground objects in remote sensing scenes, we propose a Distribution-Aware Fourier Aggregated Adapter to aggregate task-oriented changed information. This adapter not only effectively addresses the domain gap issue, but also pays attention to the distribution of changed buildings. Furthermore, to mitigate noise interference and misalignment in height offset estimation, we design a novel flow module that refines building edge extraction and enhances the perception of changed buildings. Our state-of-the-art results on the LEVIR-CD, S2Looking and WHU-CD datasets highlight the effectiveness of FAEWNet. The code is available at https://github.com/SUPERMAN123000/FAEWNet.
RCCFormer: A Robust Crowd Counting Network Based on Transformer
Apr 07, 2025Crowd counting, which is a key computer vision task, has emerged as a fundamental technology in crowd analysis and public safety management. However, challenges such as scale variations and complex backgrounds significantly impact the accuracy of crowd counting. To mitigate these issues, this paper proposes a robust Transformer-based crowd counting network, termed RCCFormer, specifically designed for background suppression and scale awareness. The proposed method incorporates a Multi-level Feature Fusion Module (MFFM), which meticulously integrates features extracted at diverse stages of the backbone architecture. It establishes a strong baseline capable of capturing intricate and comprehensive feature representations, surpassing traditional baselines. Furthermore, the introduced Detail-Embedded Attention Block (DEAB) captures contextual information and local details through global self-attention and local attention along with a learnable manner for efficient fusion. This enhances the model's ability to focus on foreground regions while effectively mitigating background noise interference. Additionally, we develop an Adaptive Scale-Aware Module (ASAM), with our novel Input-dependent Deformable Convolution (IDConv) as its fundamental building block. This module dynamically adapts to changes in head target shapes and scales, significantly improving the network's capability to accommodate large-scale variations. The effectiveness of the proposed method is validated on the ShanghaiTech Part_A and Part_B, NWPU-Crowd, and QNRF datasets. The results demonstrate that our RCCFormer achieves excellent performance across all four datasets, showcasing state-of-the-art outcomes.
Co-Paced Learning Strategy Based on Confidence for Flying Bird Object Detection Model Training
Jan 21, 2025

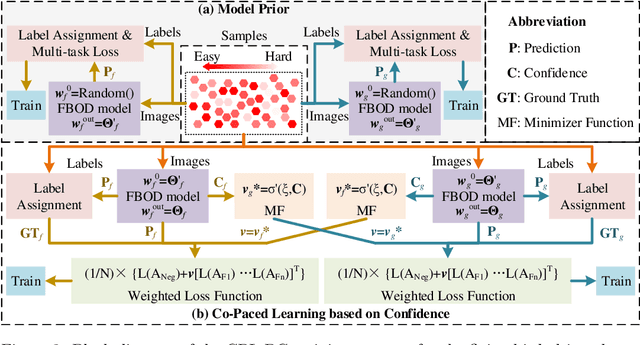
To mitigate the adverse effects of hard samples on the training of the Flying Bird Object Detection (FBOD) model for surveillance videos, we propose a Co-Paced Learning Based on Confidence (CPL-BC) strategy and apply this strategy to the training process of the FBOD model. This strategy involves maintaining two models with identical structures but different initial parameter configurations, which collaborate with each other to select easy samples with prediction confidence exceeding a set threshold for training. As training progresses, the strategy gradually lowers the threshold, allowing more samples to participate, enhancing the model's ability to recognize objects from easy to hard. Before applying the CPL-BC strategy to train the FBOD models, we initially trained the two FBOD models to equip them with the capability to assess the difficulty level of flying bird object samples. Experimental results on two different datasets of flying bird objects in surveillance videos demonstrate that, compared to other model learning strategies, CPL-BC significantly improves detection accuracy, verifying the effectiveness and advancement of this method.
Mamba-MOC: A Multicategory Remote Object Counting via State Space Model
Jan 12, 2025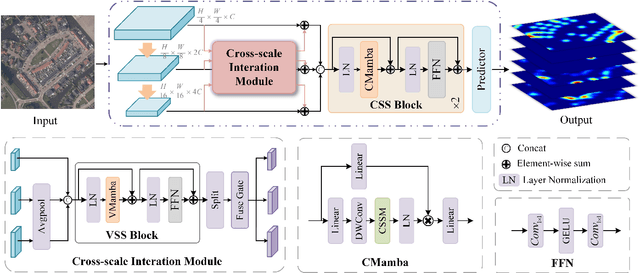
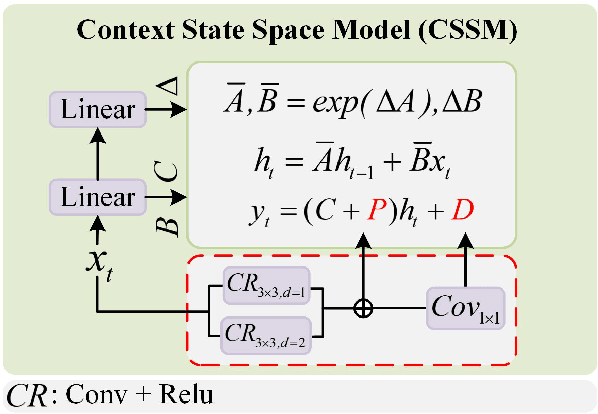

Multicategory remote object counting is a fundamental task in computer vision, aimed at accurately estimating the number of objects of various categories in remote images. Existing methods rely on CNNs and Transformers, but CNNs struggle to capture global dependencies, and Transformers are computationally expensive, which limits their effectiveness in remote applications. Recently, Mamba has emerged as a promising solution in the field of computer vision, offering a linear complexity for modeling global dependencies. To this end, we propose Mamba-MOC, a mamba-based network designed for multi-category remote object counting, which represents the first application of Mamba to remote sensing object counting. Specifically, we propose a cross-scale interaction module to facilitate the deep integration of hierarchical features. Then we design a context state space model to capture both global and local contextual information and provide local neighborhood information during the scan process. Experimental results in large-scale realistic scenarios demonstrate that our proposed method achieves state-of-the-art performance compared with some mainstream counting algorithms.
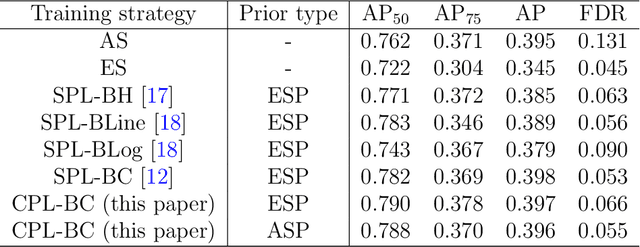
Self-Paced Learning Strategy with Easy Sample Prior Based on Confidence for the Flying Bird Object Detection Model Training
Dec 09, 2024In order to avoid the impact of hard samples on the training process of the Flying Bird Object Detection model (FBOD model, in our previous work, we designed the FBOD model according to the characteristics of flying bird objects in surveillance video), the Self-Paced Learning strategy with Easy Sample Prior Based on Confidence (SPL-ESP-BC), a new model training strategy, is proposed. Firstly, the loss-based Minimizer Function in Self-Paced Learning (SPL) is improved, and the confidence-based Minimizer Function is proposed, which makes it more suitable for one-class object detection tasks. Secondly, to give the model the ability to judge easy and hard samples at the early stage of training by using the SPL strategy, an SPL strategy with Easy Sample Prior (ESP) is proposed. The FBOD model is trained using the standard training strategy with easy samples first, then the SPL strategy with all samples is used to train it. Combining the strategy of the ESP and the Minimizer Function based on confidence, the SPL-ESP-BC model training strategy is proposed. Using this strategy to train the FBOD model can make it to learn the characteristics of the flying bird object in the surveillance video better, from easy to hard. The experimental results show that compared with the standard training strategy that does not distinguish between easy and hard samples, the AP50 of the FBOD model trained by the SPL-ESP-BC is increased by 2.1%, and compared with other loss-based SPL strategies, the FBOD model trained with SPL-ESP-BC strategy has the best comprehensive detection performance.
FBD-SV-2024: Flying Bird Object Detection Dataset in Surveillance Video
Aug 31, 2024A Flying Bird Dataset for Surveillance Videos (FBD-SV-2024) is introduced and tailored for the development and performance evaluation of flying bird detection algorithms in surveillance videos. This dataset comprises 483 video clips, amounting to 28,694 frames in total. Among them, 23,833 frames contain 28,366 instances of flying birds. The proposed dataset of flying birds in surveillance videos is collected from realistic surveillance scenarios, where the birds exhibit characteristics such as inconspicuous features in single frames (in some instances), generally small sizes, and shape variability during flight. These attributes pose challenges that need to be addressed when developing flying bird detection methods for surveillance videos. Finally, advanced (video) object detection algorithms were selected for experimentation on the proposed dataset, and the results demonstrated that this dataset remains challenging for the algorithms above. The FBD-SV-2024 is now publicly available: Please visit https://github.com/Ziwei89/FBD-SV-2024_github for the dataset download link and related processing scripts.
SSLChange: A Self-supervised Change Detection Framework Based on Domain Adaptation
May 28, 2024



In conventional remote sensing change detection (RS CD) procedures, extensive manual labeling for bi-temporal images is first required to maintain the performance of subsequent fully supervised training. However, pixel-level labeling for CD tasks is very complex and time-consuming. In this paper, we explore a novel self-supervised contrastive framework applicable to the RS CD task, which promotes the model to accurately capture spatial, structural, and semantic information through domain adapter and hierarchical contrastive head. The proposed SSLChange framework accomplishes self-learning only by taking a single-temporal sample and can be flexibly transferred to main-stream CD baselines. With self-supervised contrastive learning, feature representation pre-training can be performed directly based on the original data even without labeling. After a certain amount of labels are subsequently obtained, the pre-trained features will be aligned with the labels for fully supervised fine-tuning. Without introducing any additional data or labels, the performance of downstream baselines will experience a significant enhancement. Experimental results on 2 entire datasets and 6 diluted datasets show that our proposed SSLChange improves the performance and stability of CD baseline in data-limited situations. The code of SSLChange will be released at \url{https://github.com/MarsZhaoYT/SSLChange}
FER-YOLO-Mamba: Facial Expression Detection and Classification Based on Selective State Space
May 03, 2024



Facial Expression Recognition (FER) plays a pivotal role in understanding human emotional cues. However, traditional FER methods based on visual information have some limitations, such as preprocessing, feature extraction, and multi-stage classification procedures. These not only increase computational complexity but also require a significant amount of computing resources. Considering Convolutional Neural Network (CNN)-based FER schemes frequently prove inadequate in identifying the deep, long-distance dependencies embedded within facial expression images, and the Transformer's inherent quadratic computational complexity, this paper presents the FER-YOLO-Mamba model, which integrates the principles of Mamba and YOLO technologies to facilitate efficient coordination in facial expression image recognition and localization. Within the FER-YOLO-Mamba model, we further devise a FER-YOLO-VSS dual-branch module, which combines the inherent strengths of convolutional layers in local feature extraction with the exceptional capability of State Space Models (SSMs) in revealing long-distance dependencies. To the best of our knowledge, this is the first Vision Mamba model designed for facial expression detection and classification. To evaluate the performance of the proposed FER-YOLO-Mamba model, we conducted experiments on two benchmark datasets, RAF-DB and SFEW. The experimental results indicate that the FER-YOLO-Mamba model achieved better results compared to other models. The code is available from https://github.com/SwjtuMa/FER-YOLO-Mamba.
CLIP-guided Source-free Object Detection in Aerial Images
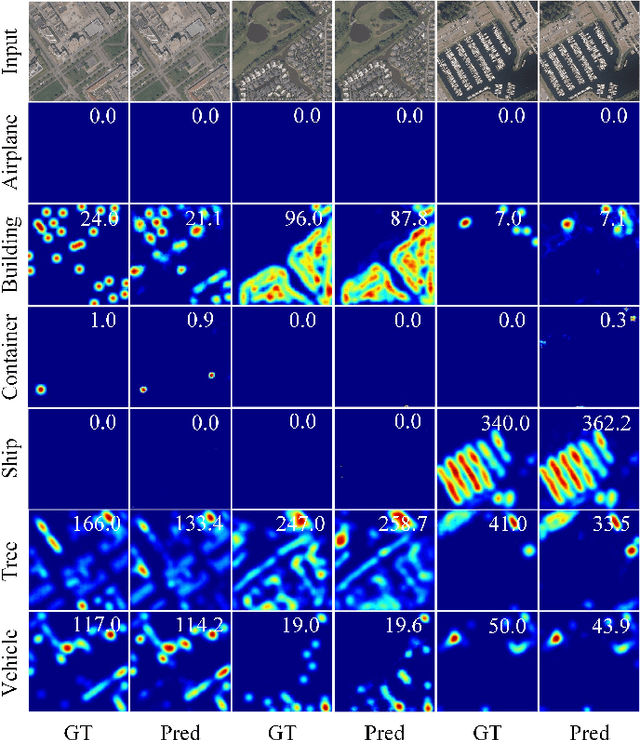
Jan 10, 2024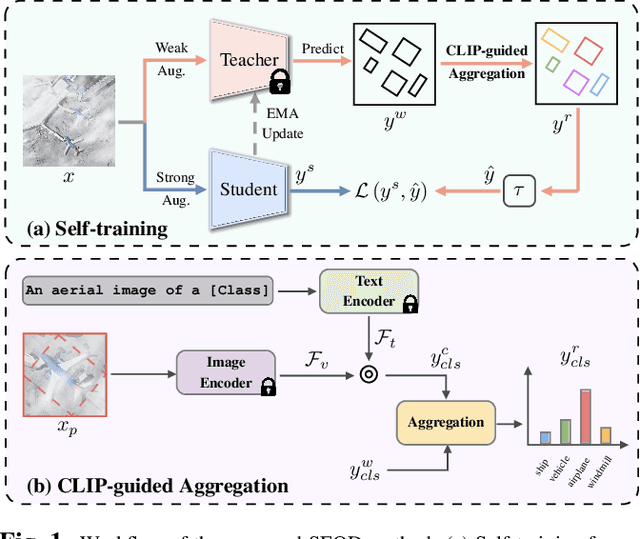
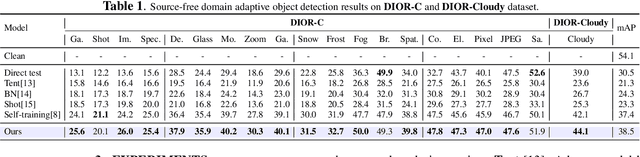
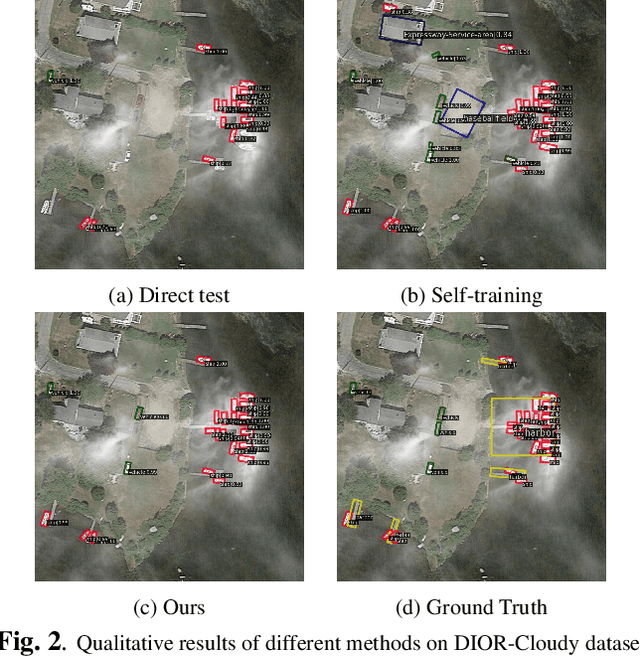
Domain adaptation is crucial in aerial imagery, as the visual representation of these images can significantly vary based on factors such as geographic location, time, and weather conditions. Additionally, high-resolution aerial images often require substantial storage space and may not be readily accessible to the public. To address these challenges, we propose a novel Source-Free Object Detection (SFOD) method. Specifically, our approach is built upon a self-training framework; however, self-training can lead to inaccurate learning in the absence of labeled training data. To address this issue, we further integrate Contrastive Language-Image Pre-training (CLIP) to guide the generation of pseudo-labels, termed CLIP-guided Aggregation. By leveraging CLIP's zero-shot classification capability, we use it to aggregate scores with the original predicted bounding boxes, enabling us to obtain refined scores for the pseudo-labels. To validate the effectiveness of our method, we constructed two new datasets from different domains based on the DIOR dataset, named DIOR-C and DIOR-Cloudy. Experiments demonstrate that our method outperforms other comparative algorithms.