 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVid: Pyramid Diffusion Model for High Quality Video Generation
Mar 14, 2026Diffusion-based text-to-video generation (T2V) or image-to-video (I2V) generation have emerged as a prominent research focus. However, there exists a challenge in integrating the two generative paradigms into a unified model. In this paper, we present a unified video generation model (UniVid) with hybrid conditions of the text prompt and reference image. Given these two available controls, our model can extract objects' appearance and their motion descriptions from textual prompts, while obtaining texture details and structural information from image clues to guide the video generation process. Specifically, we scale up the pre-trained text-to-image diffusion model for generating temporally coherent frames via introducing our temporal-pyramid cross-frame spatial-temporal attention modules and convolutions. To support bimodal control, we introduce a dual-stream cross-attention mechanism, whose attention scores can be freely re-weighted for interpolation of between single and two modalities controls during inference. Extensive experiments showcase that our UniVid achieves superior temporal coherence on T2V, I2V and (T+I)2V tasks.
PA-Net: Precipitation-Adaptive Mixture-of-Experts for Long-Tail Rainfall Nowcasting
Mar 14, 2026Precipitation nowcasting is vital for flood warning, agricultural management, and emergency response, yet two bottlenecks persist: the prohibitive cost of modeling million-scale spatiotemporal tokens from multi-variate atmospheric fields, and the extreme long-tailed rainfall distribution where heavy-to-torrential events -- those of greatest societal impact -- constitute fewer than 0.1% of all samples. We propose the Precipitation-Adaptive Network (PA-Net), a Transformer framework whose computational budget is explicitly governed by rainfall intensity. Its core component, Precipitation-Adaptive MoE (PA-MoE), dynamically scales the number of activated experts per token according to local precipitation magnitude, channeling richer representational capacity toward the rare yet critical heavy-rainfall tail. A Dual-Axis Compressed Latent Attention mechanism factorizes spatiotemporal attention with convolutional reduction to manage massive context lengths, while an intensity-aware training protocol progressively amplifies learning signals from extreme-rainfall samples. Experiment on ERA5 demonstrate consistent improvements over state-of-the-art baselines, with particularly significant gains in heavy-rain and rainstorm regimes.
A Dual-Branch Framework for Semantic Change Detection with Boundary and Temporal Awareness
Feb 12, 2026Semantic Change Detection (SCD) aims to detect and categorize land-cover changes from bi-temporal remote sensing images. Existing methods often suffer from blurred boundaries and inadequate temporal modeling, limiting segmentation accuracy. To address these issues, we propose a Dual-Branch Framework for Semantic Change Detection with Boundary and Temporal Awareness, termed DBTANet. Specifically, we utilize a dual-branch Siamese encoder where a frozen SAM branch captures global semantic context and boundary priors, while a ResNet34 branch provides local spatial details, ensuring complementary feature representations. On this basis, we design a Bidirectional Temporal Awareness Module (BTAM) to aggregate multi-scale features and capture temporal dependencies in a symmetric manner. Furthermore, a Gaussian-smoothed Projection Module (GSPM) refines shallow SAM features, suppressing noise while enhancing edge information for boundary-aware constraints. Extensive experiments on two public benchmarks demonstrate that DBTANet effectively integrates global semantics, local details, temporal reasoning, and boundary awareness, achieving state-of-the-art performance.
Exploring Generalizable Pre-training for Real-world Change Detection via Geometric Estimation
Apr 19, 2025As an essential procedure in earth observation system, change detection (CD) aims to reveal the spatial-temporal evolution of the observation regions. A key prerequisite for existing change detection algorithms is aligned geo-references between multi-temporal images by fine-grained registration. However, in the majority of real-world scenarios, a prior manual registration is required between the original images, which significantly increases the complexity of the CD workflow. In this paper, we proposed a self-supervision motivated CD framework with geometric estimation, called "MatchCD". Specifically, the proposed MatchCD framework utilizes the zero-shot capability to optimize the encoder with self-supervised contrastive representation, which is reused in the downstream image registration and change detection to simultaneously handle the bi-temporal unalignment and object change issues. Moreover, unlike the conventional change detection requiring segmenting the full-frame image into small patches, our MatchCD framework can directly process the original large-scale image (e.g., 6K*4K resolutions) with promising performance. The performance in multiple complex scenarios with significant geometric distortion demonstrates the effectiveness of our proposed framework.
SAM-Based Building Change Detection with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping
Apr 17, 2025Building change detection remains challenging for urban development, disaster assessment, and military reconnaissance. While foundation models like Segment Anything Model (SAM) show strong segmentation capabilities, SAM is limited in the task of building change detection due to domain gap issues. Existing adapter-based fine-tuning approaches face challenges with imbalanced building distribution, resulting in poor detection of subtle changes and inaccurate edge extraction. Additionally, bi-temporal misalignment in change detection, typically addressed by optical flow, remains vulnerable to background noises. This affects the detection of building changes and compromises both detection accuracy and edge recognition. To tackle these challenges, we propose a new SAM-Based Network with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping (FAEWNet) for building change detection. FAEWNet utilizes the SAM encoder to extract rich visual features from remote sensing images. To guide SAM in focusing on specific ground objects in remote sensing scenes, we propose a Distribution-Aware Fourier Aggregated Adapter to aggregate task-oriented changed information. This adapter not only effectively addresses the domain gap issue, but also pays attention to the distribution of changed buildings. Furthermore, to mitigate noise interference and misalignment in height offset estimation, we design a novel flow module that refines building edge extraction and enhances the perception of changed buildings. Our state-of-the-art results on the LEVIR-CD, S2Looking and WHU-CD datasets highlight the effectiveness of FAEWNet. The code is available at https://github.com/SUPERMAN123000/FAEWNet.
RCCFormer: A Robust Crowd Counting Network Based on Transformer
Apr 07, 2025



Crowd counting, which is a key computer vision task, has emerged as a fundamental technology in crowd analysis and public safety management. However, challenges such as scale variations and complex backgrounds significantly impact the accuracy of crowd counting. To mitigate these issues, this paper proposes a robust Transformer-based crowd counting network, termed RCCFormer, specifically designed for background suppression and scale awareness. The proposed method incorporates a Multi-level Feature Fusion Module (MFFM), which meticulously integrates features extracted at diverse stages of the backbone architecture. It establishes a strong baseline capable of capturing intricate and comprehensive feature representations, surpassing traditional baselines. Furthermore, the introduced Detail-Embedded Attention Block (DEAB) captures contextual information and local details through global self-attention and local attention along with a learnable manner for efficient fusion. This enhances the model's ability to focus on foreground regions while effectively mitigating background noise interference. Additionally, we develop an Adaptive Scale-Aware Module (ASAM), with our novel Input-dependent Deformable Convolution (IDConv) as its fundamental building block. This module dynamically adapts to changes in head target shapes and scales, significantly improving the network's capability to accommodate large-scale variations. The effectiveness of the proposed method is validated on the ShanghaiTech Part_A and Part_B, NWPU-Crowd, and QNRF datasets. The results demonstrate that our RCCFormer achieves excellent performance across all four datasets, showcasing state-of-the-art outcomes.
Mamba-MOC: A Multicategory Remote Object Counting via State Space Model
Jan 12, 2025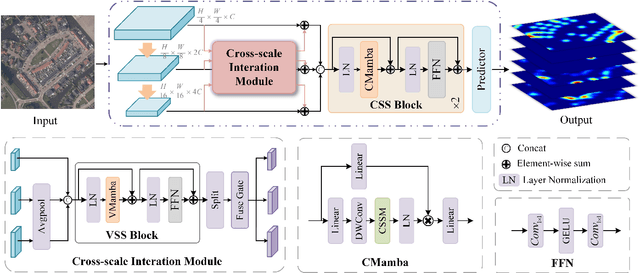
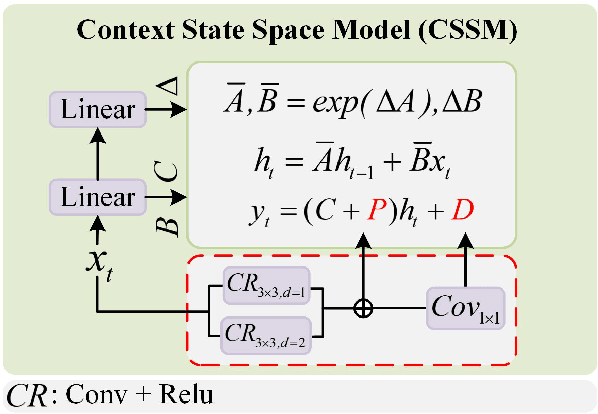
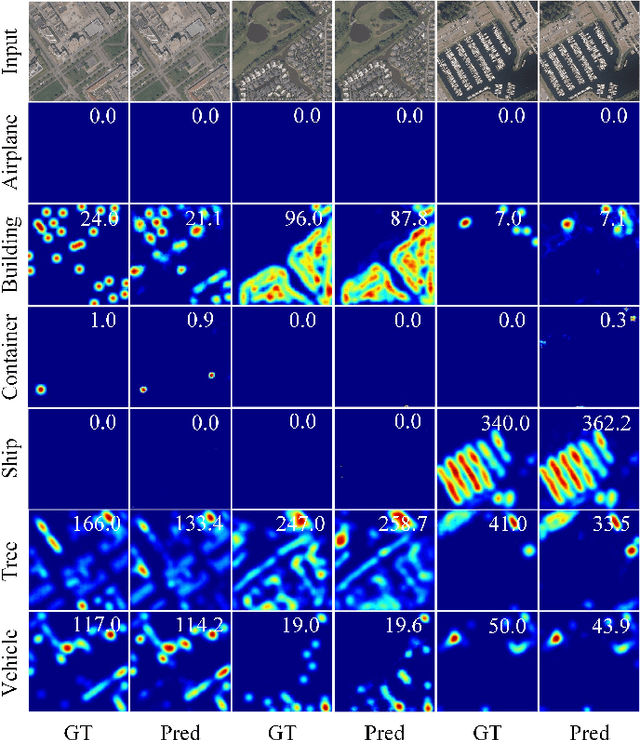

Multicategory remote object counting is a fundamental task in computer vision, aimed at accurately estimating the number of objects of various categories in remote images. Existing methods rely on CNNs and Transformers, but CNNs struggle to capture global dependencies, and Transformers are computationally expensive, which limits their effectiveness in remote applications. Recently, Mamba has emerged as a promising solution in the field of computer vision, offering a linear complexity for modeling global dependencies. To this end, we propose Mamba-MOC, a mamba-based network designed for multi-category remote object counting, which represents the first application of Mamba to remote sensing object counting. Specifically, we propose a cross-scale interaction module to facilitate the deep integration of hierarchical features. Then we design a context state space model to capture both global and local contextual information and provide local neighborhood information during the scan process. Experimental results in large-scale realistic scenarios demonstrate that our proposed method achieves state-of-the-art performance compared with some mainstream counting algorithms.
FER-YOLO-Mamba: Facial Expression Detection and Classification Based on Selective State Space
May 03, 2024



Facial Expression Recognition (FER) plays a pivotal role in understanding human emotional cues. However, traditional FER methods based on visual information have some limitations, such as preprocessing, feature extraction, and multi-stage classification procedures. These not only increase computational complexity but also require a significant amount of computing resources. Considering Convolutional Neural Network (CNN)-based FER schemes frequently prove inadequate in identifying the deep, long-distance dependencies embedded within facial expression images, and the Transformer's inherent quadratic computational complexity, this paper presents the FER-YOLO-Mamba model, which integrates the principles of Mamba and YOLO technologies to facilitate efficient coordination in facial expression image recognition and localization. Within the FER-YOLO-Mamba model, we further devise a FER-YOLO-VSS dual-branch module, which combines the inherent strengths of convolutional layers in local feature extraction with the exceptional capability of State Space Models (SSMs) in revealing long-distance dependencies. To the best of our knowledge, this is the first Vision Mamba model designed for facial expression detection and classification. To evaluate the performance of the proposed FER-YOLO-Mamba model, we conducted experiments on two benchmark datasets, RAF-DB and SFEW. The experimental results indicate that the FER-YOLO-Mamba model achieved better results compared to other models. The code is available from https://github.com/SwjtuMa/FER-YOLO-Mamba.
Continuous Remote Sensing Image Super-Resolution based on Context Interaction in Implicit Function Space
Feb 16, 2023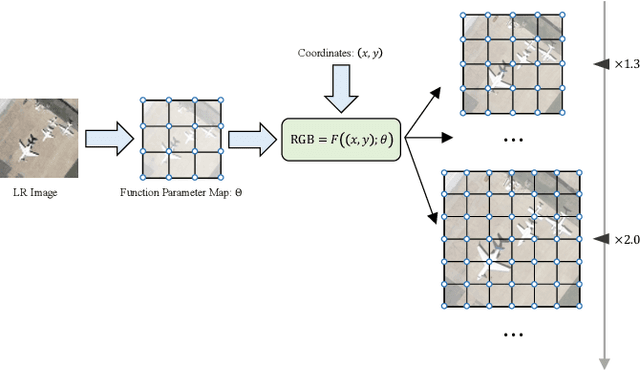
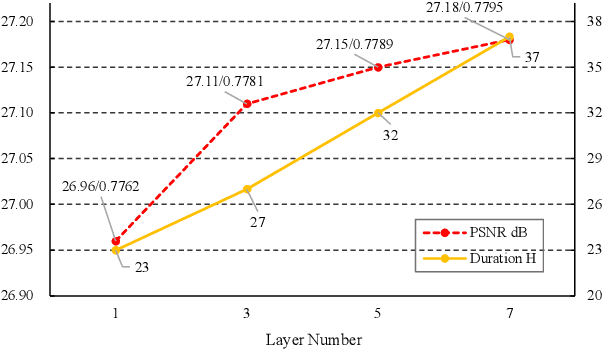
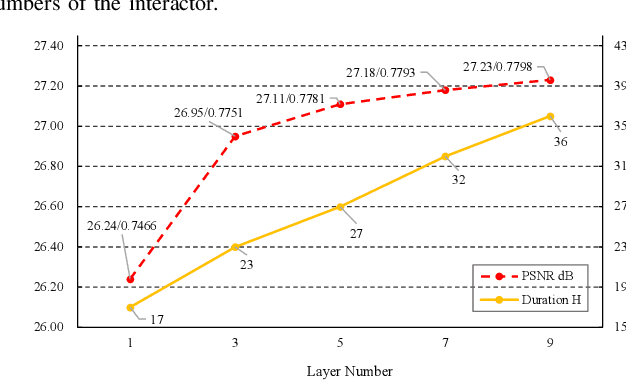
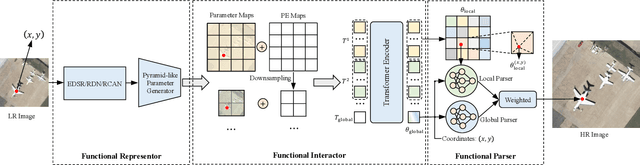
Despite its fruitful applications in remote sensing, image super-resolution is troublesome to train and deploy as it handles different resolution magnifications with separate models. Accordingly, we propose a highly-applicable super-resolution framework called FunSR, which settles different magnifications with a unified model by exploiting context interaction within implicit function space. FunSR composes a functional representor, a functional interactor, and a functional parser. Specifically, the representor transforms the low-resolution image from Euclidean space to multi-scale pixel-wise function maps; the interactor enables pixel-wise function expression with global dependencies; and the parser, which is parameterized by the interactor's output, converts the discrete coordinates with additional attributes to RGB values. Extensive experimental results demonstrate that FunSR reports state-of-the-art performance on both fixed-magnification and continuous-magnification settings, meanwhile, it provides many friendly applications thanks to its unified nature.