 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Remote Sensing Instance Segmentation with Linear-Time State Space Distilled Visual Foundation Models
Jun 24, 2026The computational complexity of Transformers scales quadratically with the number of tokens, which significantly constrains the efficiency of vision models, particularly recent ViT-based foundation models in dense prediction tasks. Instance segmentation, a typical dense visual prediction task in the remote sensing field, faces similar challenges. In this paper, inspired by the recent advances of knowledge distillation in large language models, we introduce RS4D - a new remote sensing instance segmentation method with linear computational complexity, which addresses the inefficiency of long sequence modeling through distilled state space modeling (SSM). We propose an adaptive noise and masking knowledge distillation training method for pre-training lightweight SSM backbones, which effectively compresses knowledge from the vast self-attention space into a compact, dense linear state space. We also design a remote sensing image instance segmentation architecture based on this lightweight visual encoder, where we explore variants of three different backbones and two segmentation heads. Extensive experiments are conducted on multiple benchmark datasets, including SSDD, WHU, and NWPU. Compared to ViT-based approaches, our proposed SSM backbone achieves an 8x reduction in parameters and a 9x reduction in FLOPs while maintaining comparable or superior accuracy to both ViT- and CNN-based instance segmentation methods. The implementation codes have been publicly available at https://github.com/QinzheYang/RS4D.
* 17 pages, 11 figures, has been published in IEEE TGRS vol. 64, pp. 5625417-5625417, 2026, Art no. 5625417, doi: 10.1109/TGRS.2026.3696104
SFR-Net: Learning Scale-Frustum Representations for Ultra-Wide Area Remote Sensing Image Segmentation
May 25, 2026Pixel count and geographical coverage are two key characteristics of remote sensing images. Existing remote sensing image segmentation methods typically focus on images with either a small pixel count or a large pixel count but limited geographical coverage. In this paper, we introduce a novel segmentation task targeting ultra-wide area (UWA) remote sensing images, characterized by both a large pixel count and extremely wide geographical coverage. The core challenges of UWA segmentation lie in simultaneously handling ground objects with significantly varying scales and maintaining long-range contextual semantic continuity. To address these challenges, we propose the Scale-Frustum Representation Network (SFR-Net). Inspired by the viewing frustums of remote sensing images captured from different altitudes, we construct scale-frustum representations, enabling unified modeling of ground objects and contextual features at different scales. Furthermore, we design a cascaded cross-scale fusion mechanism to effectively integrate these representations, enhancing local semantic understanding while ensuring long-range contextual continuity. Experimental results on GID and FBPS demonstrate that SFR-Net achieves state-of-the-art performance, improving mIoU by 1.72% and 4.29%, respectively, over the strongest competing methods. In addition, the proposed scale-frustum representations can be integrated into generic segmentation networks to improve both segmentation accuracy and convergence speed. The implementation code will be publicly available at https://github.com/ChuyuZhong/SFR-Net.
CloudMamba: An Uncertainty-Guided Dual-Scale Mamba Network for Cloud Detection in Remote Sensing Imagery
Apr 08, 2026Cloud detection in remote sensing imagery is a fundamental, critical, and highly challenging problem. Existing deep learning-based cloud detection methods generally formulate it as a single-stage pixel-wise binary segmentation task with one forward pass. However, such single-stage approaches exhibit ambiguity and uncertainty in thin-cloud regions and struggle to accurately handle fragmented clouds and boundary details. In this paper, we propose a novel deep learning framework termed CloudMamba. To address the ambiguity in thin-cloud regions, we introduce an uncertainty-guided two-stage cloud detection strategy. An embedded uncertainty estimation module is proposed to automatically quantify the confidence of thin-cloud segmentation, and a second-stage refinement segmentation is introduced to improve the accuracy in low-confidence hard regions. To better handle fragmented clouds and fine-grained boundary details, we design a dual-scale Mamba network based on a CNN-Mamba hybrid architecture. Compared with Transformer-based models with quadratic computational complexity, the proposed method maintains linear computational complexity while effectively capturing both large-scale structural characteristics and small-scale boundary details of clouds, enabling accurate delineation of overall cloud morphology and precise boundary segmentation. Extensive experiments conducted on the GF1_WHU and Levir_CS public datasets demonstrate that the proposed method outperforms existing approaches across multiple segmentation accuracy metrics, while offering high efficiency and process transparency. Our code is available at https://github.com/jayoungo/CloudMamba.
Multi-Modal Building Change Detection for Large-Scale Small Changes: Benchmark and Baseline
Mar 19, 2026Change detection in optical remote sensing imagery is susceptible to illumination fluctuations, seasonal changes, and variations in surface land-cover materials. Relying solely on RGB imagery often produces pseudo-changes and leads to semantic ambiguity in features. Incorporating near-infrared (NIR) information provides heterogeneous physical cues that are complementary to visible light, thereby enhancing the discriminability of building materials and tiny structures while improving detection accuracy. However, existing multi-modal datasets generally lack high-resolution and accurately registered bi-temporal imagery, and current methods often fail to fully exploit the inherent heterogeneity between these modalities. To address these issues, we introduce the Large-scale Small-change Multi-modal Dataset (LSMD), a bi-temporal RGB-NIR building change detection benchmark dataset targeting small changes in realistic scenarios, providing a rigorous testing platform for evaluating multi-modal change detection methods in complex environments. Based on LSMD, we further propose the Multi-modal Spectral Complementarity Network (MSCNet) to achieve effective cross-modal feature fusion. MSCNet comprises three key components: the Neighborhood Context Enhancement Module (NCEM) to strengthen local spatial details, the Cross-modal Alignment and Interaction Module (CAIM) to enable deep interaction between RGB and NIR features, and the Saliency-aware Multisource Refinement Module (SMRM) to progressively refine fused features. Extensive experiments demonstrate that MSCNet effectively leverages multi-modal information and consistently outperforms existing methods under multiple input configurations, validating its efficacy for fine-grained building change detection. The source code will be made publicly available at: https://github.com/AeroVILab-AHU/LSMD
FoBa: A Foreground-Background co-Guided Method and New Benchmark for Remote Sensing Semantic Change Detection
Sep 19, 2025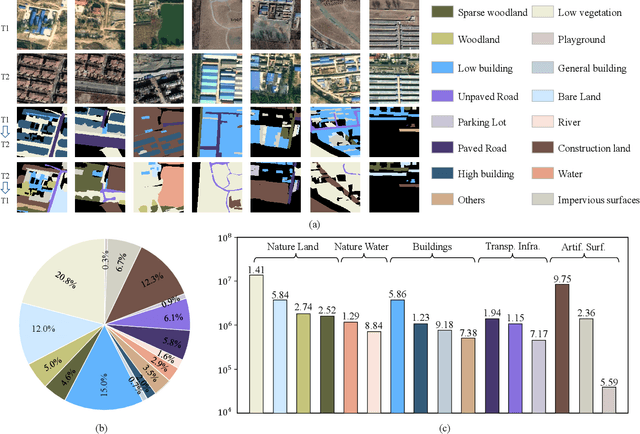

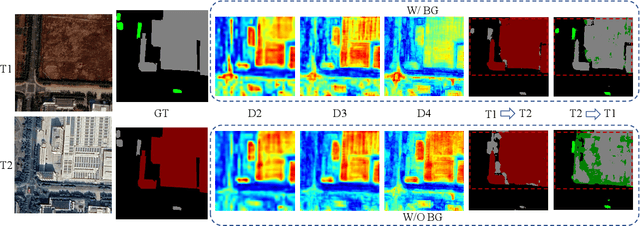
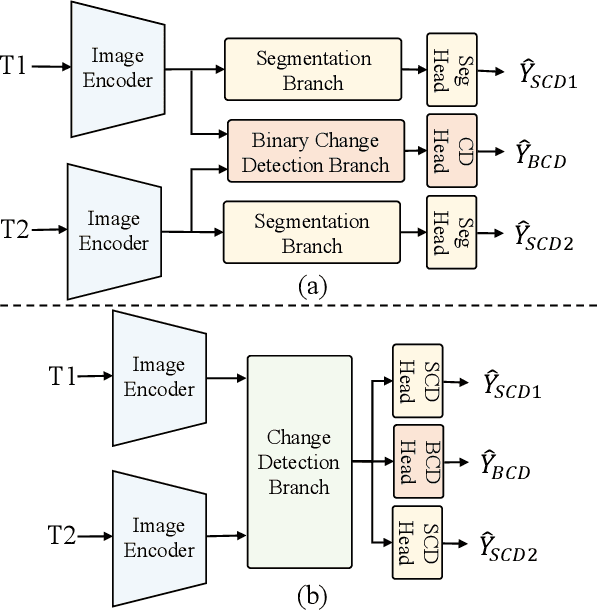
Despite the remarkable progress achieved in remote sensing semantic change detection (SCD), two major challenges remain. At the data level, existing SCD datasets suffer from limited change categories, insufficient change types, and a lack of fine-grained class definitions, making them inadequate to fully support practical applications. At the methodological level, most current approaches underutilize change information, typically treating it as a post-processing step to enhance spatial consistency, which constrains further improvements in model performance. To address these issues, we construct a new benchmark for remote sensing SCD, LevirSCD. Focused on the Beijing area, the dataset covers 16 change categories and 210 specific change types, with more fine-grained class definitions (e.g., roads are divided into unpaved and paved roads). Furthermore, we propose a foreground-background co-guided SCD (FoBa) method, which leverages foregrounds that focus on regions of interest and backgrounds enriched with contextual information to guide the model collaboratively, thereby alleviating semantic ambiguity while enhancing its ability to detect subtle changes. Considering the requirements of bi-temporal interaction and spatial consistency in SCD, we introduce a Gated Interaction Fusion (GIF) module along with a simple consistency loss to further enhance the model's detection performance. Extensive experiments on three datasets (SECOND, JL1, and the proposed LevirSCD) demonstrate that FoBa achieves competitive results compared to current SOTA methods, with improvements of 1.48%, 3.61%, and 2.81% in the SeK metric, respectively. Our code and dataset are available at https://github.com/zmoka-zht/FoBa.
RSRefSeg 2: Decoupling Referring Remote Sensing Image Segmentation with Foundation Models
Jul 08, 2025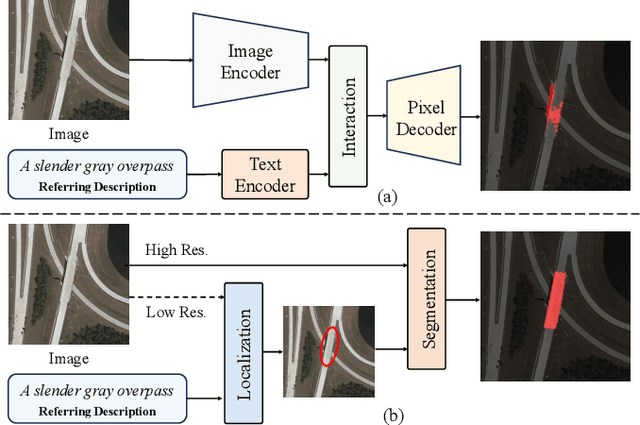
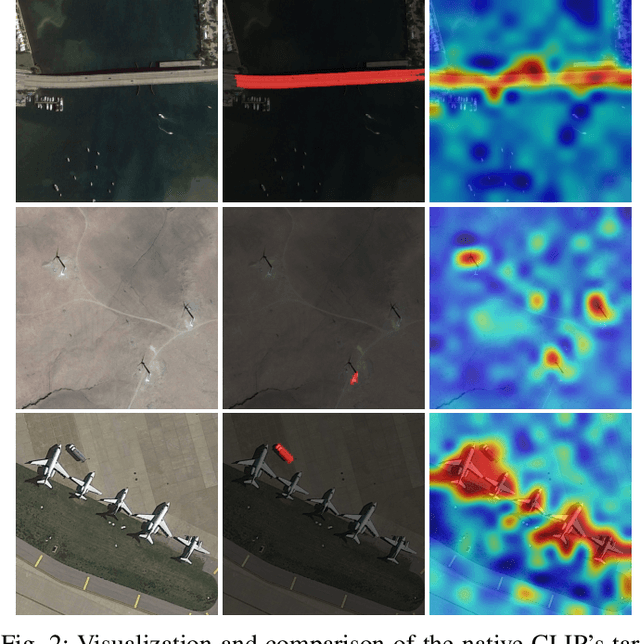
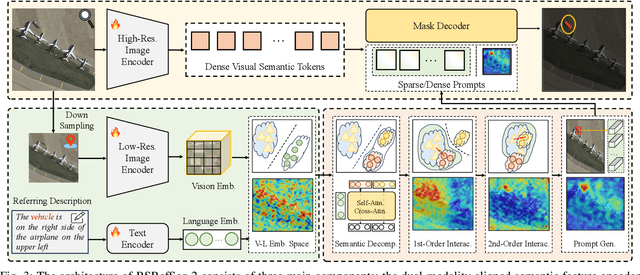
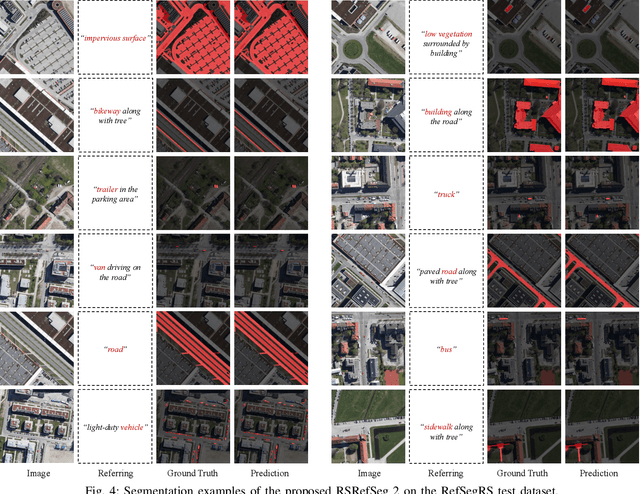
Referring Remote Sensing Image Segmentation provides a flexible and fine-grained framework for remote sensing scene analysis via vision-language collaborative interpretation. Current approaches predominantly utilize a three-stage pipeline encompassing dual-modal encoding, cross-modal interaction, and pixel decoding. These methods demonstrate significant limitations in managing complex semantic relationships and achieving precise cross-modal alignment, largely due to their coupled processing mechanism that conflates target localization with boundary delineation. This architectural coupling amplifies error propagation under semantic ambiguity while restricting model generalizability and interpretability. To address these issues, we propose RSRefSeg 2, a decoupling paradigm that reformulates the conventional workflow into a collaborative dual-stage framework: coarse localization followed by fine segmentation. RSRefSeg 2 integrates CLIP's cross-modal alignment strength with SAM's segmentation generalizability through strategic foundation model collaboration. Specifically, CLIP is employed as the dual-modal encoder to activate target features within its pre-aligned semantic space and generate localization prompts. To mitigate CLIP's misactivation challenges in multi-entity scenarios described by referring texts, a cascaded second-order prompter is devised, which enhances precision through implicit reasoning via decomposition of text embeddings into complementary semantic subspaces. These optimized semantic prompts subsequently direct the SAM to generate pixel-level refined masks, thereby completing the semantic transmission pipeline. Extensive experiments (RefSegRS, RRSIS-D, and RISBench) demonstrate that RSRefSeg 2 surpasses contemporary methods in segmentation accuracy (+~3% gIoU) and complex semantic interpretation. Code is available at: https://github.com/KyanChen/RSRefSeg2.
Fine-grained Hierarchical Crop Type Classification from Integrated Hyperspectral EnMAP Data and Multispectral Sentinel-2 Time Series: A Large-scale Dataset and Dual-stream Transformer Method
Jun 09, 2025Fine-grained crop type classification serves as the fundamental basis for large-scale crop mapping and plays a vital role in ensuring food security. It requires simultaneous capture of both phenological dynamics (obtained from multi-temporal satellite data like Sentinel-2) and subtle spectral variations (demanding nanometer-scale spectral resolution from hyperspectral imagery). Research combining these two modalities remains scarce currently due to challenges in hyperspectral data acquisition and crop types annotation costs. To address these issues, we construct a hierarchical hyperspectral crop dataset (H2Crop) by integrating 30m-resolution EnMAP hyperspectral data with Sentinel-2 time series. With over one million annotated field parcels organized in a four-tier crop taxonomy, H2Crop establishes a vital benchmark for fine-grained agricultural crop classification and hyperspectral image processing. We propose a dual-stream Transformer architecture that synergistically processes these modalities. It coordinates two specialized pathways: a spectral-spatial Transformer extracts fine-grained signatures from hyperspectral EnMAP data, while a temporal Swin Transformer extracts crop growth patterns from Sentinel-2 time series. The designed hierarchical classification head with hierarchical fusion then simultaneously delivers multi-level crop type classification across all taxonomic tiers. Experiments demonstrate that adding hyperspectral EnMAP data to Sentinel-2 time series yields a 4.2% average F1-scores improvement (peaking at 6.3%). Extensive comparisons also confirm our method's higher accuracy over existing deep learning approaches for crop type classification and the consistent benefits of hyperspectral data across varying temporal windows and crop change scenarios. Codes and dataset are available at https://github.com/flyakon/H2Crop.
A Novel Large-scale Crop Dataset and Dual-stream Transformer Method for Fine-grained Hierarchical Crop Classification from Integrated Hyperspectral EnMAP Data and Multispectral Sentinel-2 Time Series
Jun 06, 2025Fine-grained crop classification is crucial for precision agriculture and food security monitoring. It requires simultaneous capture of both phenological dynamics (obtained from multi-temporal satellite data like Sentinel-2) and subtle spectral variations (demanding nanometer-scale spectral resolution from hyperspectral imagery). Research combining these two modalities remains scarce currently due to challenges in hyperspectral data acquisition and crop types annotation costs. To address these issues, we construct a hierarchical hyperspectral crop dataset (H2Crop) by integrating 30m-resolution EnMAP hyperspectral data with Sentinel-2 time series. With over one million annotated field parcels organized in a four-tier crop taxonomy, H2Crop establishes a vital benchmark for fine-grained agricultural crop classification and hyperspectral image processing. We propose a dual-stream Transformer architecture that synergistically processes these modalities. It coordinates two specialized pathways: a spectral-spatial Transformer extracts fine-grained signatures from hyperspectral EnMAP data, while a temporal Swin Transformer extracts crop growth patterns from Sentinel-2 time series. The designed hierarchy classification heads with hierarchical fusion then simultaneously delivers multi-level classification across all taxonomic tiers. Experiments demonstrate that adding hyperspectral EnMAP data to Sentinel-2 time series yields a 4.2% average F1-scores improvement (peaking at 6.3%). Extensive comparisons also confirming our method's higher accuracy over existing deep learning approaches for crop type classification and the consistent benefits of hyperspectral data across varying temporal windows and crop change scenarios. Codes and dataset will be available at https://github.com/flyakon/H2Crop and www.glass.hku.hk Keywords: Crop type classification, precision agriculture, remote sensing, deep learning, hyperspectral data, Sentinel-2 time series, fine-grained crops
SeG-SR: Integrating Semantic Knowledge into Remote Sensing Image Super-Resolution via Vision-Language Model
May 29, 2025High-resolution (HR) remote sensing imagery plays a vital role in a wide range of applications, including urban planning and environmental monitoring. However, due to limitations in sensors and data transmission links, the images acquired in practice often suffer from resolution degradation. Remote Sensing Image Super-Resolution (RSISR) aims to reconstruct HR images from low-resolution (LR) inputs, providing a cost-effective and efficient alternative to direct HR image acquisition. Existing RSISR methods primarily focus on low-level characteristics in pixel space, while neglecting the high-level understanding of remote sensing scenes. This may lead to semantically inconsistent artifacts in the reconstructed results. Motivated by this observation, our work aims to explore the role of high-level semantic knowledge in improving RSISR performance. We propose a Semantic-Guided Super-Resolution framework, SeG-SR, which leverages Vision-Language Models (VLMs) to extract semantic knowledge from input images and uses it to guide the super resolution (SR) process. Specifically, we first design a Semantic Feature Extraction Module (SFEM) that utilizes a pretrained VLM to extract semantic knowledge from remote sensing images. Next, we propose a Semantic Localization Module (SLM), which derives a series of semantic guidance from the extracted semantic knowledge. Finally, we develop a Learnable Modulation Module (LMM) that uses semantic guidance to modulate the features extracted by the SR network, effectively incorporating high-level scene understanding into the SR pipeline. We validate the effectiveness and generalizability of SeG-SR through extensive experiments: SeG-SR achieves state-of-the-art performance on two datasets and consistently delivers performance improvements across various SR architectures. Codes can be found at https://github.com/Mr-Bamboo/SeG-SR.
AgriFM: A Multi-source Temporal Remote Sensing Foundation Model for Crop Mapping
May 28, 2025Accurate crop mapping fundamentally relies on modeling multi-scale spatiotemporal patterns, where spatial scales range from individual field textures to landscape-level context, and temporal scales capture both short-term phenological transitions and full growing-season dynamics. Transformer-based remote sensing foundation models (RSFMs) offer promising potential for crop mapping due to their innate ability for unified spatiotemporal processing. However, current RSFMs remain suboptimal for crop mapping: they either employ fixed spatiotemporal windows that ignore the multi-scale nature of crop systems or completely disregard temporal information by focusing solely on spatial patterns. To bridge these gaps, we present AgriFM, a multi-source remote sensing foundation model specifically designed for agricultural crop mapping. Our approach begins by establishing the necessity of simultaneous hierarchical spatiotemporal feature extraction, leading to the development of a modified Video Swin Transformer architecture where temporal down-sampling is synchronized with spatial scaling operations. This modified backbone enables efficient unified processing of long time-series satellite inputs. AgriFM leverages temporally rich data streams from three satellite sources including MODIS, Landsat-8/9 and Sentinel-2, and is pre-trained on a global representative dataset comprising over 25 million image samples supervised by land cover products. The resulting framework incorporates a versatile decoder architecture that dynamically fuses these learned spatiotemporal representations, supporting diverse downstream tasks. Comprehensive evaluations demonstrate AgriFM's superior performance over conventional deep learning approaches and state-of-the-art general-purpose RSFMs across all downstream tasks. Codes will be available at https://github.com/flyakon/AgriFM.