 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPo : Motion-Aware Partitioning of Deformable 3D Gaussian Splatting for High-Fidelity Dynamic Scene Reconstruction
Aug 27, 2025
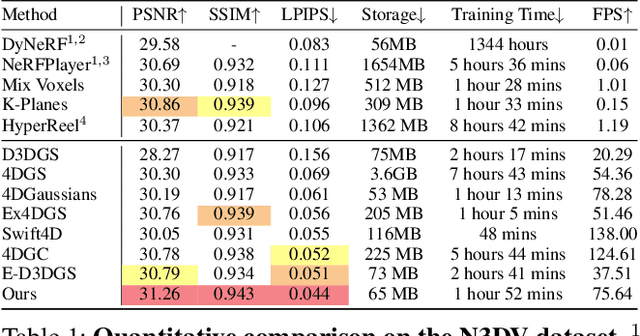

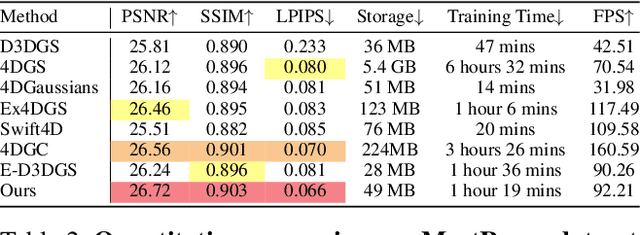
3D Gaussian Splatting, known for enabling high-quality static scene reconstruction with fast rendering, is increasingly being applied to dynamic scene reconstruction. A common strategy involves learning a deformation field to model the temporal changes of a canonical set of 3D Gaussians. However, these deformation-based methods often produce blurred renderings and lose fine motion details in highly dynamic regions due to the inherent limitations of a single, unified model in representing diverse motion patterns. To address these challenges, we introduce Motion-Aware Partitioning of Deformable 3D Gaussian Splatting (MAPo), a novel framework for high-fidelity dynamic scene reconstruction. Its core is a dynamic score-based partitioning strategy that distinguishes between high- and low-dynamic 3D Gaussians. For high-dynamic 3D Gaussians, we recursively partition them temporally and duplicate their deformation networks for each new temporal segment, enabling specialized modeling to capture intricate motion details. Concurrently, low-dynamic 3DGs are treated as static to reduce computational costs. However, this temporal partitioning strategy for high-dynamic 3DGs can introduce visual discontinuities across frames at the partition boundaries. To address this, we introduce a cross-frame consistency loss, which not only ensures visual continuity but also further enhances rendering quality. Extensive experiments demonstrate that MAPo achieves superior rendering quality compared to baselines while maintaining comparable computational costs, particularly in regions with complex or rapid motions.
Pseudo-Physics-Informed Neural Operators: Enhancing Operator Learning from Limited Data
Feb 04, 2025



Neural operators have shown great potential in surrogate modeling. However, training a well-performing neural operator typically requires a substantial amount of data, which can pose a major challenge in complex applications. In such scenarios, detailed physical knowledge can be unavailable or difficult to obtain, and collecting extensive data is often prohibitively expensive. To mitigate this challenge, we propose the Pseudo Physics-Informed Neural Operator (PPI-NO) framework. PPI-NO constructs a surrogate physics system for the target system using partial differential equations (PDEs) derived from simple, rudimentary physics principles, such as basic differential operators. This surrogate system is coupled with a neural operator model, using an alternating update and learning process to iteratively enhance the model's predictive power. While the physics derived via PPI-NO may not mirror the ground-truth underlying physical laws -- hence the term ``pseudo physics'' -- this approach significantly improves the accuracy of standard operator learning models in data-scarce scenarios, which is evidenced by extensive evaluations across five benchmark tasks and a fatigue modeling application.
MC-VTON: Minimal Control Virtual Try-On Diffusion Transformer
Jan 07, 2025


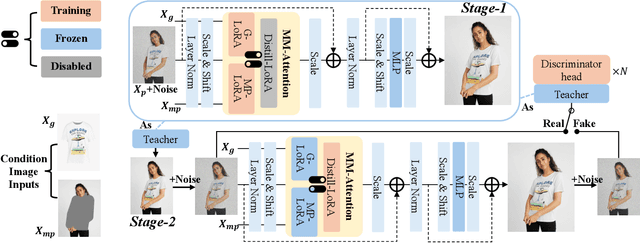
Virtual try-on methods based on diffusion models achieve realistic try-on effects. They use an extra reference network or an additional image encoder to process multiple conditional image inputs, which results in high training costs. Besides, they require more than 25 inference steps, bringing a long inference time. In this work, with the development of diffusion transformer (DiT), we rethink the necessity of reference network or image encoder, then propose MC-VTON, enabling DiT to integrate minimal conditional try-on inputs by utilizing its intrinsic backbone. Compared to existing methods, the superiority of MC-VTON is demonstrated in four aspects: (1)Superior detail fidelity. Our DiT-based MC-VTON exhibits superior fidelity in preserving fine-grained details. (2)Simplified network and inputs. We remove any extra reference network or image encoder. We also remove unnecessary conditions like the long prompt, pose estimation, human parsing, and depth map. We require only the masked person image and the garment image. (3)Parameter-efficient training. To process the try-on task, we fine-tune the FLUX.1-dev with only 39.7M additional parameters 0.33% of the backbone parameters). (4)Less inference steps. We apply distillation diffusion on MC-VTON and only need 8 steps to generate a realistic try-on image, with only 86.8M additional parameters (0.72% of the backbone parameters). Experiments show that MC-VTON achieves superior qualitative and quantitative results with fewer condition inputs, fewer inference steps, and fewer trainable parameters than baseline methods.
Rethinking Video Deblurring with Wavelet-Aware Dynamic Transformer and Diffusion Model
Aug 24, 2024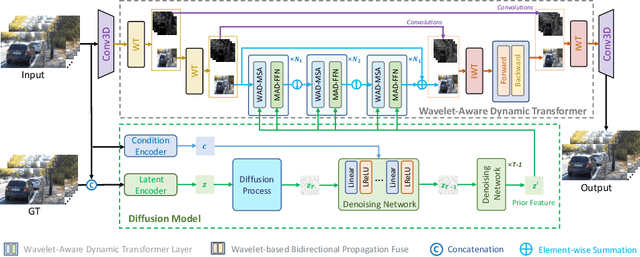
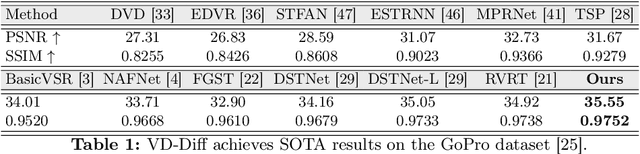
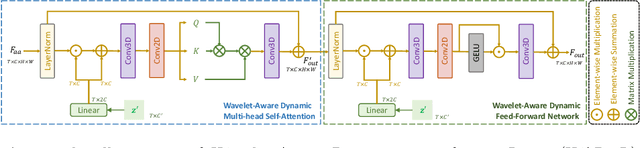
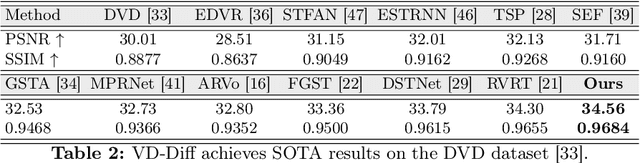
Current video deblurring methods have limitations in recovering high-frequency information since the regression losses are conservative with high-frequency details. Since Diffusion Models (DMs) have strong capabilities in generating high-frequency details, we consider introducing DMs into the video deblurring task. However, we found that directly applying DMs to the video deblurring task has the following problems: (1) DMs require many iteration steps to generate videos from Gaussian noise, which consumes many computational resources. (2) DMs are easily misled by the blurry artifacts in the video, resulting in irrational content and distortion of the deblurred video. To address the above issues, we propose a novel video deblurring framework VD-Diff that integrates the diffusion model into the Wavelet-Aware Dynamic Transformer (WADT). Specifically, we perform the diffusion model in a highly compact latent space to generate prior features containing high-frequency information that conforms to the ground truth distribution. We design the WADT to preserve and recover the low-frequency information in the video while utilizing the high-frequency information generated by the diffusion model. Extensive experiments show that our proposed VD-Diff outperforms SOTA methods on GoPro, DVD, BSD, and Real-World Video datasets.
Rethink Arbitrary Style Transfer with Transformer and Contrastive Learning
Apr 21, 2024



Arbitrary style transfer holds widespread attention in research and boasts numerous practical applications. The existing methods, which either employ cross-attention to incorporate deep style attributes into content attributes or use adaptive normalization to adjust content features, fail to generate high-quality stylized images. In this paper, we introduce an innovative technique to improve the quality of stylized images. Firstly, we propose Style Consistency Instance Normalization (SCIN), a method to refine the alignment between content and style features. In addition, we have developed an Instance-based Contrastive Learning (ICL) approach designed to understand the relationships among various styles, thereby enhancing the quality of the resulting stylized images. Recognizing that VGG networks are more adept at extracting classification features and need to be better suited for capturing style features, we have also introduced the Perception Encoder (PE) to capture style features. Extensive experiments demonstrate that our proposed method generates high-quality stylized images and effectively prevents artifacts compared with the existing state-of-the-art methods.
Towards Highly Realistic Artistic Style Transfer via Stable Diffusion with Step-aware and Layer-aware Prompt
Apr 17, 2024
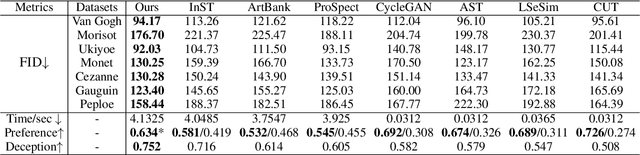
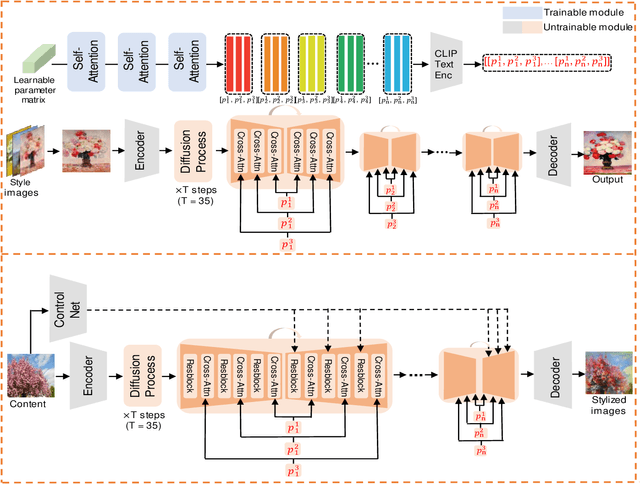
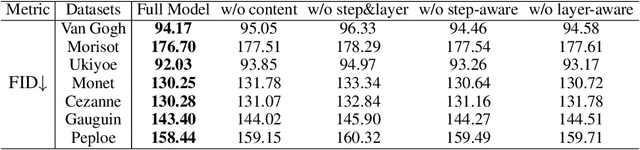
Artistic style transfer aims to transfer the learned artistic style onto an arbitrary content image, generating artistic stylized images. Existing generative adversarial network-based methods fail to generate highly realistic stylized images and always introduce obvious artifacts and disharmonious patterns. Recently, large-scale pre-trained diffusion models opened up a new way for generating highly realistic artistic stylized images. However, diffusion model-based methods generally fail to preserve the content structure of input content images well, introducing some undesired content structure and style patterns. To address the above problems, we propose a novel pre-trained diffusion-based artistic style transfer method, called LSAST, which can generate highly realistic artistic stylized images while preserving the content structure of input content images well, without bringing obvious artifacts and disharmonious style patterns. Specifically, we introduce a Step-aware and Layer-aware Prompt Space, a set of learnable prompts, which can learn the style information from the collection of artworks and dynamically adjusts the input images' content structure and style pattern. To train our prompt space, we propose a novel inversion method, called Step-ware and Layer-aware Prompt Inversion, which allows the prompt space to learn the style information of the artworks collection. In addition, we inject a pre-trained conditional branch of ControlNet into our LSAST, which further improved our framework's ability to maintain content structure. Extensive experiments demonstrate that our proposed method can generate more highly realistic artistic stylized images than the state-of-the-art artistic style transfer methods.
Rethinking Diffusion Model for Multi-Contrast MRI Super-Resolution
Apr 07, 2024Recently, diffusion models (DM) have been applied in magnetic resonance imaging (MRI) super-resolution (SR) reconstruction, exhibiting impressive performance, especially with regard to detailed reconstruction. However, the current DM-based SR reconstruction methods still face the following issues: (1) They require a large number of iterations to reconstruct the final image, which is inefficient and consumes a significant amount of computational resources. (2) The results reconstructed by these methods are often misaligned with the real high-resolution images, leading to remarkable distortion in the reconstructed MR images. To address the aforementioned issues, we propose an efficient diffusion model for multi-contrast MRI SR, named as DiffMSR. Specifically, we apply DM in a highly compact low-dimensional latent space to generate prior knowledge with high-frequency detail information. The highly compact latent space ensures that DM requires only a few simple iterations to produce accurate prior knowledge. In addition, we design the Prior-Guide Large Window Transformer (PLWformer) as the decoder for DM, which can extend the receptive field while fully utilizing the prior knowledge generated by DM to ensure that the reconstructed MR image remains undistorted. Extensive experiments on public and clinical datasets demonstrate that our DiffMSR outperforms state-of-the-art methods.
Attack Deterministic Conditional Image Generative Models for Diverse and Controllable Generation
Mar 13, 2024Existing generative adversarial network (GAN) based conditional image generative models typically produce fixed output for the same conditional input, which is unreasonable for highly subjective tasks, such as large-mask image inpainting or style transfer. On the other hand, GAN-based diverse image generative methods require retraining/fine-tuning the network or designing complex noise injection functions, which is computationally expensive, task-specific, or struggle to generate high-quality results. Given that many deterministic conditional image generative models have been able to produce high-quality yet fixed results, we raise an intriguing question: is it possible for pre-trained deterministic conditional image generative models to generate diverse results without changing network structures or parameters? To answer this question, we re-examine the conditional image generation tasks from the perspective of adversarial attack and propose a simple and efficient plug-in projected gradient descent (PGD) like method for diverse and controllable image generation. The key idea is attacking the pre-trained deterministic generative models by adding a micro perturbation to the input condition. In this way, diverse results can be generated without any adjustment of network structures or fine-tuning of the pre-trained models. In addition, we can also control the diverse results to be generated by specifying the attack direction according to a reference text or image. Our work opens the door to applying adversarial attack to low-level vision tasks, and experiments on various conditional image generation tasks demonstrate the effectiveness and superiority of the proposed method.
PNeSM: Arbitrary 3D Scene Stylization via Prompt-Based Neural Style Mapping
Mar 13, 20243D scene stylization refers to transform the appearance of a 3D scene to match a given style image, ensuring that images rendered from different viewpoints exhibit the same style as the given style image, while maintaining the 3D consistency of the stylized scene. Several existing methods have obtained impressive results in stylizing 3D scenes. However, the models proposed by these methods need to be re-trained when applied to a new scene. In other words, their models are coupled with a specific scene and cannot adapt to arbitrary other scenes. To address this issue, we propose a novel 3D scene stylization framework to transfer an arbitrary style to an arbitrary scene, without any style-related or scene-related re-training. Concretely, we first map the appearance of the 3D scene into a 2D style pattern space, which realizes complete disentanglement of the geometry and appearance of the 3D scene and makes our model be generalized to arbitrary 3D scenes. Then we stylize the appearance of the 3D scene in the 2D style pattern space via a prompt-based 2D stylization algorithm. Experimental results demonstrate that our proposed framework is superior to SOTA methods in both visual quality and generalization.
3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos
Mar 05, 2024Constructing photo-realistic Free-Viewpoint Videos (FVVs) of dynamic scenes from multi-view videos remains a challenging endeavor. Despite the remarkable advancements achieved by current neural rendering techniques, these methods generally require complete video sequences for offline training and are not capable of real-time rendering. To address these constraints, we introduce 3DGStream, a method designed for efficient FVV streaming of real-world dynamic scenes. Our method achieves fast on-the-fly per-frame reconstruction within 12 seconds and real-time rendering at 200 FPS. Specifically, we utilize 3D Gaussians (3DGs) to represent the scene. Instead of the na\"ive approach of directly optimizing 3DGs per-frame, we employ a compact Neural Transformation Cache (NTC) to model the translations and rotations of 3DGs, markedly reducing the training time and storage required for each FVV frame. Furthermore, we propose an adaptive 3DG addition strategy to handle emerging objects in dynamic scenes. Experiments demonstrate that 3DGStream achieves competitive performance in terms of rendering speed, image quality, training time, and model storage when compared with state-of-the-art methods.