 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining
Feb 05, 2026Graphical User Interface (GUI) agent is pivotal to advancing intelligent human-computer interaction paradigms. Constructing powerful GUI agents necessitates the large-scale annotation of high-quality user-behavior trajectory data (i.e., intent-trajectory pairs) for training. However, manual annotation methods and current GUI agent data mining approaches typically face three critical challenges: high construction cost, poor data quality, and low data richness. To address these issues, we propose M$^2$-Miner, the first low-cost and automated mobile GUI agent data-mining framework based on Monte Carlo Tree Search (MCTS). For better data mining efficiency and quality, we present a collaborative multi-agent framework, comprising InferAgent, OrchestraAgent, and JudgeAgent for guidance, acceleration, and evaluation. To further enhance the efficiency of mining and enrich intent diversity, we design an intent recycling strategy to extract extra valuable interaction trajectories. Additionally, a progressive model-in-the-loop training strategy is introduced to improve the success rate of data mining. Extensive experiments have demonstrated that the GUI agent fine-tuned using our mined data achieves state-of-the-art performance on several commonly used mobile GUI benchmarks. Our work will be released to facilitate the community research.
DynaIP: Dynamic Image Prompt Adapter for Scalable Zero-shot Personalized Text-to-Image Generation
Dec 10, 2025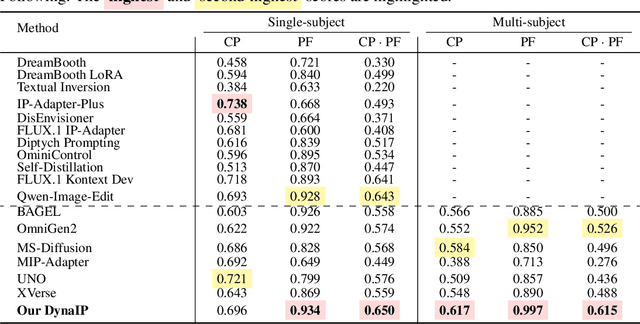

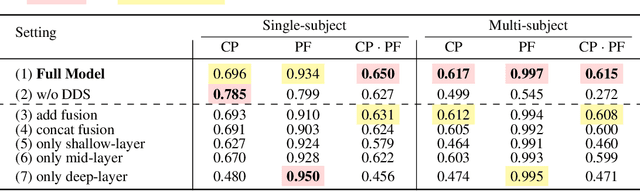
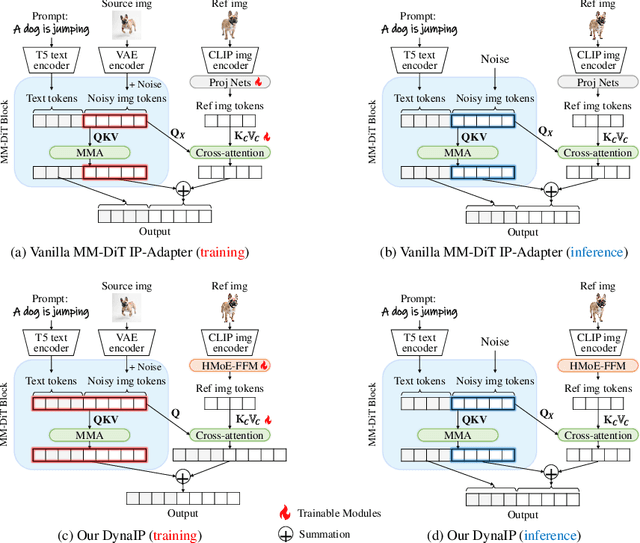
Personalized Text-to-Image (PT2I) generation aims to produce customized images based on reference images. A prominent interest pertains to the integration of an image prompt adapter to facilitate zero-shot PT2I without test-time fine-tuning. However, current methods grapple with three fundamental challenges: 1. the elusive equilibrium between Concept Preservation (CP) and Prompt Following (PF), 2. the difficulty in retaining fine-grained concept details in reference images, and 3. the restricted scalability to extend to multi-subject personalization. To tackle these challenges, we present Dynamic Image Prompt Adapter (DynaIP), a cutting-edge plugin to enhance the fine-grained concept fidelity, CP-PF balance, and subject scalability of SOTA T2I multimodal diffusion transformers (MM-DiT) for PT2I generation. Our key finding is that MM-DiT inherently exhibit decoupling learning behavior when injecting reference image features into its dual branches via cross attentions. Based on this, we design an innovative Dynamic Decoupling Strategy that removes the interference of concept-agnostic information during inference, significantly enhancing the CP-PF balance and further bolstering the scalability of multi-subject compositions. Moreover, we identify the visual encoder as a key factor affecting fine-grained CP and reveal that the hierarchical features of commonly used CLIP can capture visual information at diverse granularity levels. Therefore, we introduce a novel Hierarchical Mixture-of-Experts Feature Fusion Module to fully leverage the hierarchical features of CLIP, remarkably elevating the fine-grained concept fidelity while also providing flexible control of visual granularity. Extensive experiments across single- and multi-subject PT2I tasks verify that our DynaIP outperforms existing approaches, marking a notable advancement in the field of PT2l generation.
SparkUI-Parser: Enhancing GUI Perception with Robust Grounding and Parsing
Sep 05, 2025The existing Multimodal Large Language Models (MLLMs) for GUI perception have made great progress. However, the following challenges still exist in prior methods: 1) They model discrete coordinates based on text autoregressive mechanism, which results in lower grounding accuracy and slower inference speed. 2) They can only locate predefined sets of elements and are not capable of parsing the entire interface, which hampers the broad application and support for downstream tasks. To address the above issues, we propose SparkUI-Parser, a novel end-to-end framework where higher localization precision and fine-grained parsing capability of the entire interface are simultaneously achieved. Specifically, instead of using probability-based discrete modeling, we perform continuous modeling of coordinates based on a pre-trained Multimodal Large Language Model (MLLM) with an additional token router and coordinate decoder. This effectively mitigates the limitations inherent in the discrete output characteristics and the token-by-token generation process of MLLMs, consequently boosting both the accuracy and the inference speed. To further enhance robustness, a rejection mechanism based on a modified Hungarian matching algorithm is introduced, which empowers the model to identify and reject non-existent elements, thereby reducing false positives. Moreover, we present ScreenParse, a rigorously constructed benchmark to systematically assess structural perception capabilities of GUI models across diverse scenarios. Extensive experiments demonstrate that our approach consistently outperforms SOTA methods on ScreenSpot, ScreenSpot-v2, CAGUI-Grounding and ScreenParse benchmarks. The resources are available at https://github.com/antgroup/SparkUI-Parser.
PNeSM: Arbitrary 3D Scene Stylization via Prompt-Based Neural Style Mapping
Mar 13, 20243D scene stylization refers to transform the appearance of a 3D scene to match a given style image, ensuring that images rendered from different viewpoints exhibit the same style as the given style image, while maintaining the 3D consistency of the stylized scene. Several existing methods have obtained impressive results in stylizing 3D scenes. However, the models proposed by these methods need to be re-trained when applied to a new scene. In other words, their models are coupled with a specific scene and cannot adapt to arbitrary other scenes. To address this issue, we propose a novel 3D scene stylization framework to transfer an arbitrary style to an arbitrary scene, without any style-related or scene-related re-training. Concretely, we first map the appearance of the 3D scene into a 2D style pattern space, which realizes complete disentanglement of the geometry and appearance of the 3D scene and makes our model be generalized to arbitrary 3D scenes. Then we stylize the appearance of the 3D scene in the 2D style pattern space via a prompt-based 2D stylization algorithm. Experimental results demonstrate that our proposed framework is superior to SOTA methods in both visual quality and generalization.
Attack Deterministic Conditional Image Generative Models for Diverse and Controllable Generation
Mar 13, 2024Existing generative adversarial network (GAN) based conditional image generative models typically produce fixed output for the same conditional input, which is unreasonable for highly subjective tasks, such as large-mask image inpainting or style transfer. On the other hand, GAN-based diverse image generative methods require retraining/fine-tuning the network or designing complex noise injection functions, which is computationally expensive, task-specific, or struggle to generate high-quality results. Given that many deterministic conditional image generative models have been able to produce high-quality yet fixed results, we raise an intriguing question: is it possible for pre-trained deterministic conditional image generative models to generate diverse results without changing network structures or parameters? To answer this question, we re-examine the conditional image generation tasks from the perspective of adversarial attack and propose a simple and efficient plug-in projected gradient descent (PGD) like method for diverse and controllable image generation. The key idea is attacking the pre-trained deterministic generative models by adding a micro perturbation to the input condition. In this way, diverse results can be generated without any adjustment of network structures or fine-tuning of the pre-trained models. In addition, we can also control the diverse results to be generated by specifying the attack direction according to a reference text or image. Our work opens the door to applying adversarial attack to low-level vision tasks, and experiments on various conditional image generation tasks demonstrate the effectiveness and superiority of the proposed method.