 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaIP: Dynamic Image Prompt Adapter for Scalable Zero-shot Personalized Text-to-Image Generation
Dec 10, 2025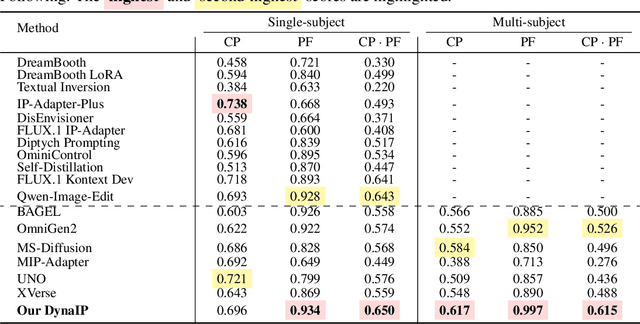

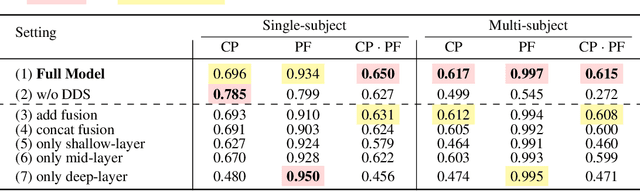
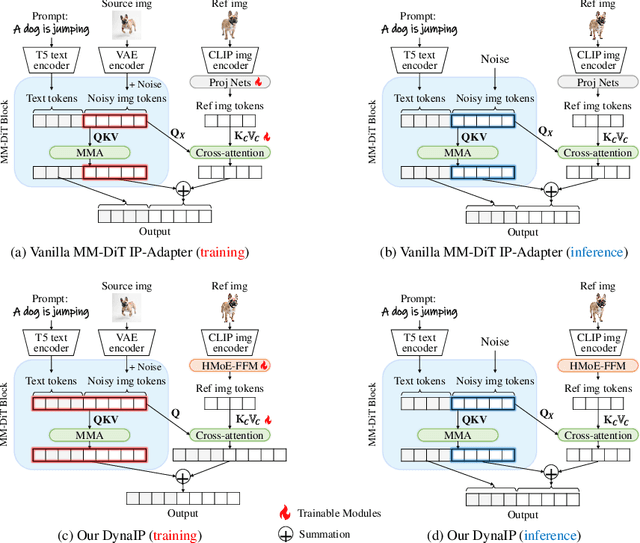
Personalized Text-to-Image (PT2I) generation aims to produce customized images based on reference images. A prominent interest pertains to the integration of an image prompt adapter to facilitate zero-shot PT2I without test-time fine-tuning. However, current methods grapple with three fundamental challenges: 1. the elusive equilibrium between Concept Preservation (CP) and Prompt Following (PF), 2. the difficulty in retaining fine-grained concept details in reference images, and 3. the restricted scalability to extend to multi-subject personalization. To tackle these challenges, we present Dynamic Image Prompt Adapter (DynaIP), a cutting-edge plugin to enhance the fine-grained concept fidelity, CP-PF balance, and subject scalability of SOTA T2I multimodal diffusion transformers (MM-DiT) for PT2I generation. Our key finding is that MM-DiT inherently exhibit decoupling learning behavior when injecting reference image features into its dual branches via cross attentions. Based on this, we design an innovative Dynamic Decoupling Strategy that removes the interference of concept-agnostic information during inference, significantly enhancing the CP-PF balance and further bolstering the scalability of multi-subject compositions. Moreover, we identify the visual encoder as a key factor affecting fine-grained CP and reveal that the hierarchical features of commonly used CLIP can capture visual information at diverse granularity levels. Therefore, we introduce a novel Hierarchical Mixture-of-Experts Feature Fusion Module to fully leverage the hierarchical features of CLIP, remarkably elevating the fine-grained concept fidelity while also providing flexible control of visual granularity. Extensive experiments across single- and multi-subject PT2I tasks verify that our DynaIP outperforms existing approaches, marking a notable advancement in the field of PT2l generation.
MultiCrafter: High-Fidelity Multi-Subject Generation via Spatially Disentangled Attention and Identity-Aware Reinforcement Learning
Sep 26, 2025Multi-subject image generation aims to synthesize user-provided subjects in a single image while preserving subject fidelity, ensuring prompt consistency, and aligning with human aesthetic preferences. However, existing methods, particularly those built on the In-Context-Learning paradigm, are limited by their reliance on simple reconstruction-based objectives, leading to both severe attribute leakage that compromises subject fidelity and failing to align with nuanced human preferences. To address this, we propose MultiCrafter, a framework that ensures high-fidelity, preference-aligned generation. First, we find that the root cause of attribute leakage is a significant entanglement of attention between different subjects during the generation process. Therefore, we introduce explicit positional supervision to explicitly separate attention regions for each subject, effectively mitigating attribute leakage. To enable the model to accurately plan the attention region of different subjects in diverse scenarios, we employ a Mixture-of-Experts architecture to enhance the model's capacity, allowing different experts to focus on different scenarios. Finally, we design a novel online reinforcement learning framework to align the model with human preferences, featuring a scoring mechanism to accurately assess multi-subject fidelity and a more stable training strategy tailored for the MoE architecture. Experiments validate that our framework significantly improves subject fidelity while aligning with human preferences better.
SCSA: A Plug-and-Play Semantic Continuous-Sparse Attention for Arbitrary Semantic Style Transfer
Mar 06, 2025Attention-based arbitrary style transfer methods, including CNN-based, Transformer-based, and Diffusion-based, have flourished and produced high-quality stylized images. However, they perform poorly on the content and style images with the same semantics, i.e., the style of the corresponding semantic region of the generated stylized image is inconsistent with that of the style image. We argue that the root cause lies in their failure to consider the relationship between local regions and semantic regions. To address this issue, we propose a plug-and-play semantic continuous-sparse attention, dubbed SCSA, for arbitrary semantic style transfer -- each query point considers certain key points in the corresponding semantic region. Specifically, semantic continuous attention ensures each query point fully attends to all the continuous key points in the same semantic region that reflect the overall style characteristics of that region; Semantic sparse attention allows each query point to focus on the most similar sparse key point in the same semantic region that exhibits the specific stylistic texture of that region. By combining the two modules, the resulting SCSA aligns the overall style of the corresponding semantic regions while transferring the vivid textures of these regions. Qualitative and quantitative results prove that SCSA enables attention-based arbitrary style transfer methods to produce high-quality semantic stylized images.
PNeSM: Arbitrary 3D Scene Stylization via Prompt-Based Neural Style Mapping
Mar 13, 20243D scene stylization refers to transform the appearance of a 3D scene to match a given style image, ensuring that images rendered from different viewpoints exhibit the same style as the given style image, while maintaining the 3D consistency of the stylized scene. Several existing methods have obtained impressive results in stylizing 3D scenes. However, the models proposed by these methods need to be re-trained when applied to a new scene. In other words, their models are coupled with a specific scene and cannot adapt to arbitrary other scenes. To address this issue, we propose a novel 3D scene stylization framework to transfer an arbitrary style to an arbitrary scene, without any style-related or scene-related re-training. Concretely, we first map the appearance of the 3D scene into a 2D style pattern space, which realizes complete disentanglement of the geometry and appearance of the 3D scene and makes our model be generalized to arbitrary 3D scenes. Then we stylize the appearance of the 3D scene in the 2D style pattern space via a prompt-based 2D stylization algorithm. Experimental results demonstrate that our proposed framework is superior to SOTA methods in both visual quality and generalization.
Attack Deterministic Conditional Image Generative Models for Diverse and Controllable Generation
Mar 13, 2024Existing generative adversarial network (GAN) based conditional image generative models typically produce fixed output for the same conditional input, which is unreasonable for highly subjective tasks, such as large-mask image inpainting or style transfer. On the other hand, GAN-based diverse image generative methods require retraining/fine-tuning the network or designing complex noise injection functions, which is computationally expensive, task-specific, or struggle to generate high-quality results. Given that many deterministic conditional image generative models have been able to produce high-quality yet fixed results, we raise an intriguing question: is it possible for pre-trained deterministic conditional image generative models to generate diverse results without changing network structures or parameters? To answer this question, we re-examine the conditional image generation tasks from the perspective of adversarial attack and propose a simple and efficient plug-in projected gradient descent (PGD) like method for diverse and controllable image generation. The key idea is attacking the pre-trained deterministic generative models by adding a micro perturbation to the input condition. In this way, diverse results can be generated without any adjustment of network structures or fine-tuning of the pre-trained models. In addition, we can also control the diverse results to be generated by specifying the attack direction according to a reference text or image. Our work opens the door to applying adversarial attack to low-level vision tasks, and experiments on various conditional image generation tasks demonstrate the effectiveness and superiority of the proposed method.
StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models
Aug 15, 2023
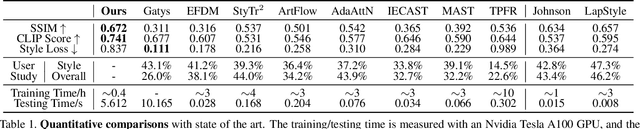


Content and style (C-S) disentanglement is a fundamental problem and critical challenge of style transfer. Existing approaches based on explicit definitions (e.g., Gram matrix) or implicit learning (e.g., GANs) are neither interpretable nor easy to control, resulting in entangled representations and less satisfying results. In this paper, we propose a new C-S disentangled framework for style transfer without using previous assumptions. The key insight is to explicitly extract the content information and implicitly learn the complementary style information, yielding interpretable and controllable C-S disentanglement and style transfer. A simple yet effective CLIP-based style disentanglement loss coordinated with a style reconstruction prior is introduced to disentangle C-S in the CLIP image space. By further leveraging the powerful style removal and generative ability of diffusion models, our framework achieves superior results than state of the art and flexible C-S disentanglement and trade-off control. Our work provides new insights into the C-S disentanglement in style transfer and demonstrates the potential of diffusion models for learning well-disentangled C-S characteristics.
Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning
Mar 23, 2023



This paper presents a new adversarial training framework for image inpainting with segmentation confusion adversarial training (SCAT) and contrastive learning. SCAT plays an adversarial game between an inpainting generator and a segmentation network, which provides pixel-level local training signals and can adapt to images with free-form holes. By combining SCAT with standard global adversarial training, the new adversarial training framework exhibits the following three advantages simultaneously: (1) the global consistency of the repaired image, (2) the local fine texture details of the repaired image, and (3) the flexibility of handling images with free-form holes. Moreover, we propose the textural and semantic contrastive learning losses to stabilize and improve our inpainting model's training by exploiting the feature representation space of the discriminator, in which the inpainting images are pulled closer to the ground truth images but pushed farther from the corrupted images. The proposed contrastive losses better guide the repaired images to move from the corrupted image data points to the real image data points in the feature representation space, resulting in more realistic completed images. We conduct extensive experiments on two benchmark datasets, demonstrating our model's effectiveness and superiority both qualitatively and quantitatively.
MicroAST: Towards Super-Fast Ultra-Resolution Arbitrary Style Transfer
Nov 28, 2022
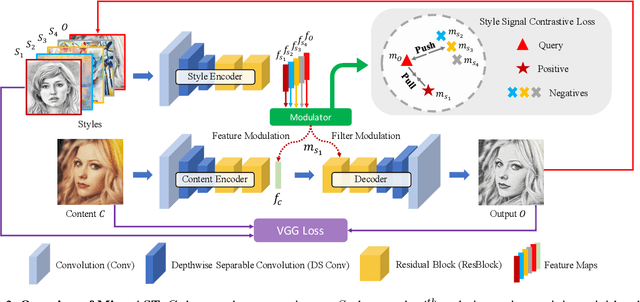
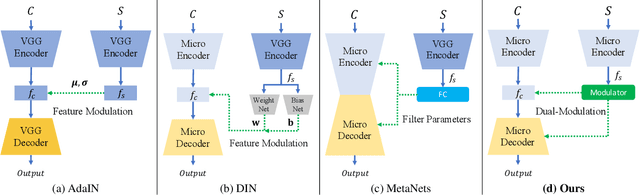
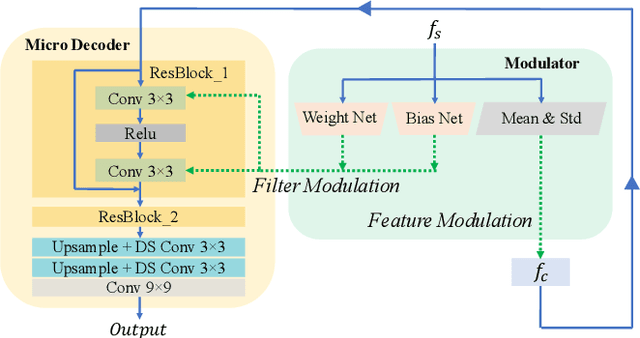
Arbitrary style transfer (AST) transfers arbitrary artistic styles onto content images. Despite the recent rapid progress, existing AST methods are either incapable or too slow to run at ultra-resolutions (e.g., 4K) with limited resources, which heavily hinders their further applications. In this paper, we tackle this dilemma by learning a straightforward and lightweight model, dubbed MicroAST. The key insight is to completely abandon the use of cumbersome pre-trained Deep Convolutional Neural Networks (e.g., VGG) at inference. Instead, we design two micro encoders (content and style encoders) and one micro decoder for style transfer. The content encoder aims at extracting the main structure of the content image. The style encoder, coupled with a modulator, encodes the style image into learnable dual-modulation signals that modulate both intermediate features and convolutional filters of the decoder, thus injecting more sophisticated and flexible style signals to guide the stylizations. In addition, to boost the ability of the style encoder to extract more distinct and representative style signals, we also introduce a new style signal contrastive loss in our model. Compared to the state of the art, our MicroAST not only produces visually superior results but also is 5-73 times smaller and 6-18 times faster, for the first time enabling super-fast (about 0.5 seconds) AST at 4K ultra-resolutions. Code is available at https://github.com/EndyWon/MicroAST.
AesUST: Towards Aesthetic-Enhanced Universal Style Transfer
Aug 27, 2022

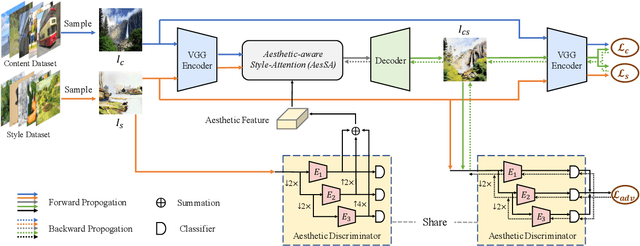
Recent studies have shown remarkable success in universal style transfer which transfers arbitrary visual styles to content images. However, existing approaches suffer from the aesthetic-unrealistic problem that introduces disharmonious patterns and evident artifacts, making the results easy to spot from real paintings. To address this limitation, we propose AesUST, a novel Aesthetic-enhanced Universal Style Transfer approach that can generate aesthetically more realistic and pleasing results for arbitrary styles. Specifically, our approach introduces an aesthetic discriminator to learn the universal human-delightful aesthetic features from a large corpus of artist-created paintings. Then, the aesthetic features are incorporated to enhance the style transfer process via a novel Aesthetic-aware Style-Attention (AesSA) module. Such an AesSA module enables our AesUST to efficiently and flexibly integrate the style patterns according to the global aesthetic channel distribution of the style image and the local semantic spatial distribution of the content image. Moreover, we also develop a new two-stage transfer training strategy with two aesthetic regularizations to train our model more effectively, further improving stylization performance. Extensive experiments and user studies demonstrate that our approach synthesizes aesthetically more harmonious and realistic results than state of the art, greatly narrowing the disparity with real artist-created paintings. Our code is available at https://github.com/EndyWon/AesUST.
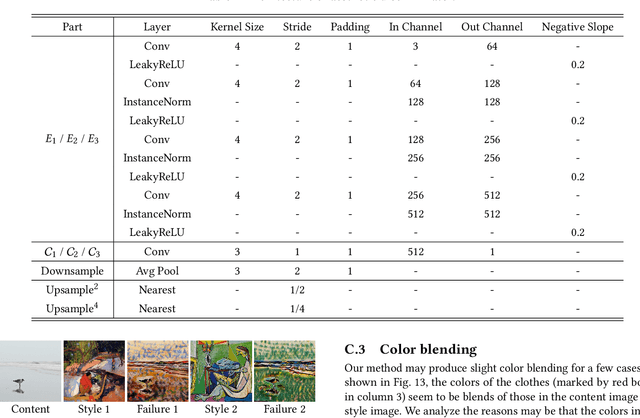
Texture Reformer: Towards Fast and Universal Interactive Texture Transfer
Dec 06, 2021
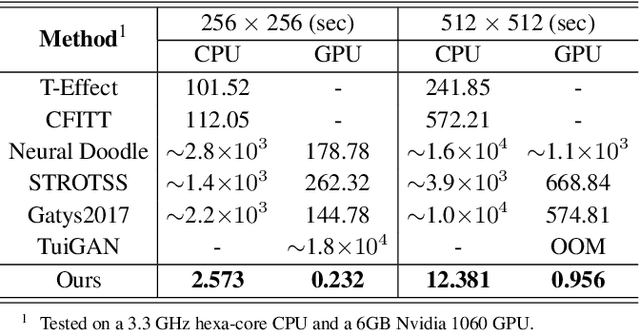
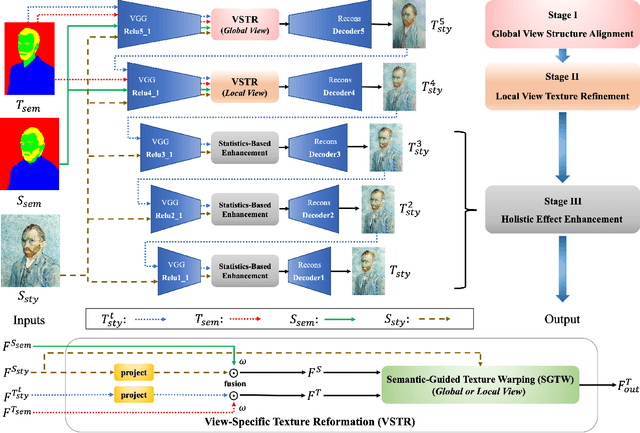

In this paper, we present the texture reformer, a fast and universal neural-based framework for interactive texture transfer with user-specified guidance. The challenges lie in three aspects: 1) the diversity of tasks, 2) the simplicity of guidance maps, and 3) the execution efficiency. To address these challenges, our key idea is to use a novel feed-forward multi-view and multi-stage synthesis procedure consisting of I) a global view structure alignment stage, II) a local view texture refinement stage, and III) a holistic effect enhancement stage to synthesize high-quality results with coherent structures and fine texture details in a coarse-to-fine fashion. In addition, we also introduce a novel learning-free view-specific texture reformation (VSTR) operation with a new semantic map guidance strategy to achieve more accurate semantic-guided and structure-preserved texture transfer. The experimental results on a variety of application scenarios demonstrate the effectiveness and superiority of our framework. And compared with the state-of-the-art interactive texture transfer algorithms, it not only achieves higher quality results but, more remarkably, also is 2-5 orders of magnitude faster. Code is available at https://github.com/EndyWon/Texture-Reformer.