 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining
Feb 05, 2026Graphical User Interface (GUI) agent is pivotal to advancing intelligent human-computer interaction paradigms. Constructing powerful GUI agents necessitates the large-scale annotation of high-quality user-behavior trajectory data (i.e., intent-trajectory pairs) for training. However, manual annotation methods and current GUI agent data mining approaches typically face three critical challenges: high construction cost, poor data quality, and low data richness. To address these issues, we propose M$^2$-Miner, the first low-cost and automated mobile GUI agent data-mining framework based on Monte Carlo Tree Search (MCTS). For better data mining efficiency and quality, we present a collaborative multi-agent framework, comprising InferAgent, OrchestraAgent, and JudgeAgent for guidance, acceleration, and evaluation. To further enhance the efficiency of mining and enrich intent diversity, we design an intent recycling strategy to extract extra valuable interaction trajectories. Additionally, a progressive model-in-the-loop training strategy is introduced to improve the success rate of data mining. Extensive experiments have demonstrated that the GUI agent fine-tuned using our mined data achieves state-of-the-art performance on several commonly used mobile GUI benchmarks. Our work will be released to facilitate the community research.
SparkUI-Parser: Enhancing GUI Perception with Robust Grounding and Parsing
Sep 05, 2025The existing Multimodal Large Language Models (MLLMs) for GUI perception have made great progress. However, the following challenges still exist in prior methods: 1) They model discrete coordinates based on text autoregressive mechanism, which results in lower grounding accuracy and slower inference speed. 2) They can only locate predefined sets of elements and are not capable of parsing the entire interface, which hampers the broad application and support for downstream tasks. To address the above issues, we propose SparkUI-Parser, a novel end-to-end framework where higher localization precision and fine-grained parsing capability of the entire interface are simultaneously achieved. Specifically, instead of using probability-based discrete modeling, we perform continuous modeling of coordinates based on a pre-trained Multimodal Large Language Model (MLLM) with an additional token router and coordinate decoder. This effectively mitigates the limitations inherent in the discrete output characteristics and the token-by-token generation process of MLLMs, consequently boosting both the accuracy and the inference speed. To further enhance robustness, a rejection mechanism based on a modified Hungarian matching algorithm is introduced, which empowers the model to identify and reject non-existent elements, thereby reducing false positives. Moreover, we present ScreenParse, a rigorously constructed benchmark to systematically assess structural perception capabilities of GUI models across diverse scenarios. Extensive experiments demonstrate that our approach consistently outperforms SOTA methods on ScreenSpot, ScreenSpot-v2, CAGUI-Grounding and ScreenParse benchmarks. The resources are available at https://github.com/antgroup/SparkUI-Parser.
Rethinking Video Deblurring with Wavelet-Aware Dynamic Transformer and Diffusion Model
Aug 24, 2024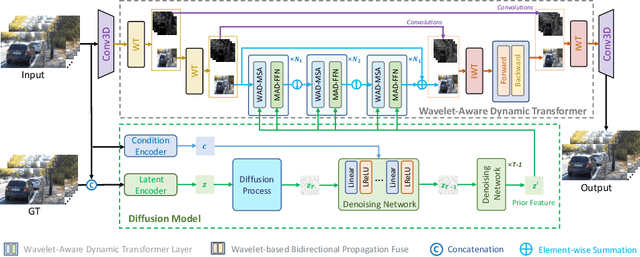
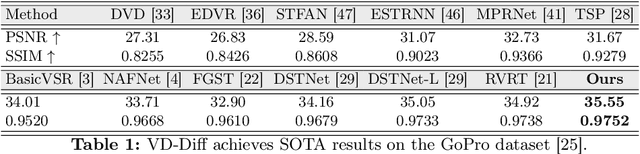
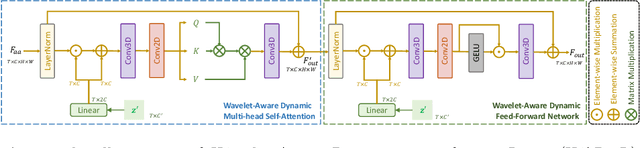
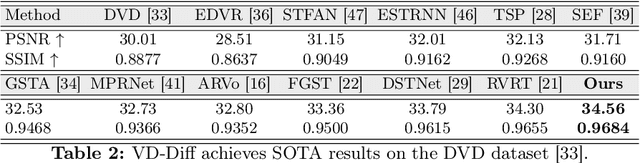
Current video deblurring methods have limitations in recovering high-frequency information since the regression losses are conservative with high-frequency details. Since Diffusion Models (DMs) have strong capabilities in generating high-frequency details, we consider introducing DMs into the video deblurring task. However, we found that directly applying DMs to the video deblurring task has the following problems: (1) DMs require many iteration steps to generate videos from Gaussian noise, which consumes many computational resources. (2) DMs are easily misled by the blurry artifacts in the video, resulting in irrational content and distortion of the deblurred video. To address the above issues, we propose a novel video deblurring framework VD-Diff that integrates the diffusion model into the Wavelet-Aware Dynamic Transformer (WADT). Specifically, we perform the diffusion model in a highly compact latent space to generate prior features containing high-frequency information that conforms to the ground truth distribution. We design the WADT to preserve and recover the low-frequency information in the video while utilizing the high-frequency information generated by the diffusion model. Extensive experiments show that our proposed VD-Diff outperforms SOTA methods on GoPro, DVD, BSD, and Real-World Video datasets.
Rethinking Diffusion Model for Multi-Contrast MRI Super-Resolution
Apr 07, 2024Recently, diffusion models (DM) have been applied in magnetic resonance imaging (MRI) super-resolution (SR) reconstruction, exhibiting impressive performance, especially with regard to detailed reconstruction. However, the current DM-based SR reconstruction methods still face the following issues: (1) They require a large number of iterations to reconstruct the final image, which is inefficient and consumes a significant amount of computational resources. (2) The results reconstructed by these methods are often misaligned with the real high-resolution images, leading to remarkable distortion in the reconstructed MR images. To address the aforementioned issues, we propose an efficient diffusion model for multi-contrast MRI SR, named as DiffMSR. Specifically, we apply DM in a highly compact low-dimensional latent space to generate prior knowledge with high-frequency detail information. The highly compact latent space ensures that DM requires only a few simple iterations to produce accurate prior knowledge. In addition, we design the Prior-Guide Large Window Transformer (PLWformer) as the decoder for DM, which can extend the receptive field while fully utilizing the prior knowledge generated by DM to ensure that the reconstructed MR image remains undistorted. Extensive experiments on public and clinical datasets demonstrate that our DiffMSR outperforms state-of-the-art methods.