 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Nov 14, 2025
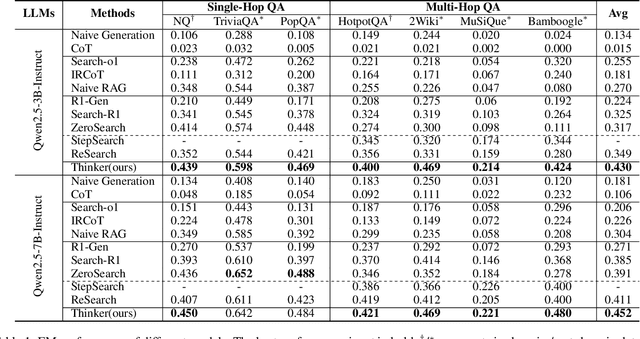
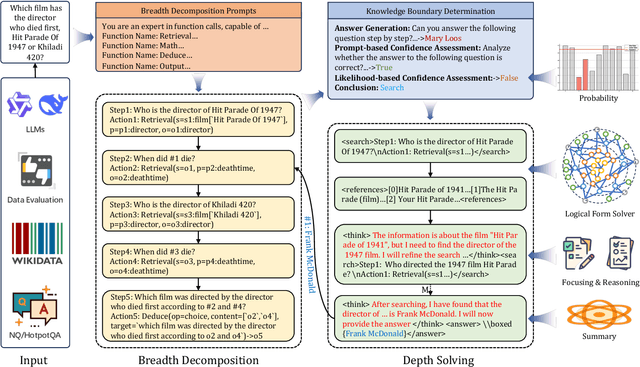
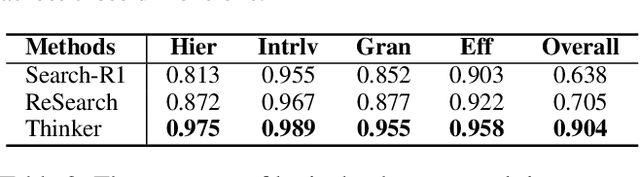
Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
Enhancing WiFi CSI Fingerprinting: A Deep Auxiliary Learning Approach
Oct 26, 2025Radio frequency (RF) fingerprinting techniques provide a promising supplement to cryptography-based approaches but rely on dedicated equipment to capture in-phase and quadrature (IQ) samples, hindering their wide adoption. Recent advances advocate easily obtainable channel state information (CSI) by commercial WiFi devices for lightweight RF fingerprinting, while falling short in addressing the challenges of coarse granularity of CSI measurements in an open-world setting. In this paper, we propose CSI2Q, a novel CSI fingerprinting system that achieves comparable performance to IQ-based approaches. Instead of extracting fingerprints directly from raw CSI measurements, CSI2Q first transforms frequency-domain CSI measurements into time-domain signals that share the same feature space with IQ samples. Then, we employ a deep auxiliary learning strategy to transfer useful knowledge from an IQ fingerprinting model to the CSI counterpart. Finally, the trained CSI model is combined with an OpenMax function to estimate the likelihood of unknown ones. We evaluate CSI2Q on one synthetic CSI dataset involving 85 devices and two real CSI datasets, including 10 and 25 WiFi routers, respectively. Our system achieves accuracy increases of at least 16% on the synthetic CSI dataset, 20% on the in-lab CSI dataset, and 17% on the in-the-wild CSI dataset.
Rethinking Video Deblurring with Wavelet-Aware Dynamic Transformer and Diffusion Model
Aug 24, 2024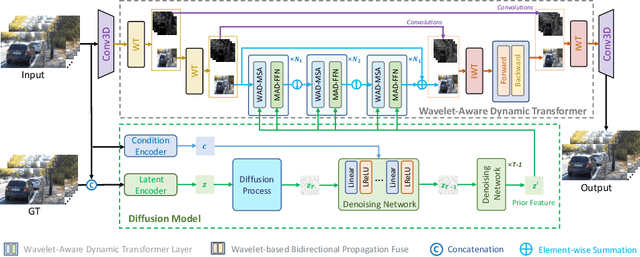
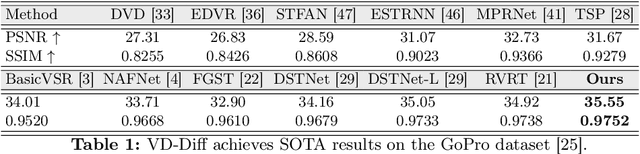
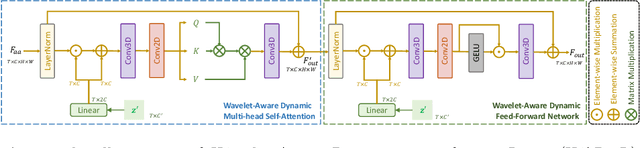
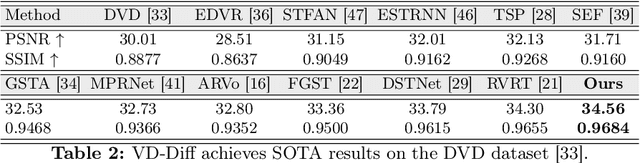
Current video deblurring methods have limitations in recovering high-frequency information since the regression losses are conservative with high-frequency details. Since Diffusion Models (DMs) have strong capabilities in generating high-frequency details, we consider introducing DMs into the video deblurring task. However, we found that directly applying DMs to the video deblurring task has the following problems: (1) DMs require many iteration steps to generate videos from Gaussian noise, which consumes many computational resources. (2) DMs are easily misled by the blurry artifacts in the video, resulting in irrational content and distortion of the deblurred video. To address the above issues, we propose a novel video deblurring framework VD-Diff that integrates the diffusion model into the Wavelet-Aware Dynamic Transformer (WADT). Specifically, we perform the diffusion model in a highly compact latent space to generate prior features containing high-frequency information that conforms to the ground truth distribution. We design the WADT to preserve and recover the low-frequency information in the video while utilizing the high-frequency information generated by the diffusion model. Extensive experiments show that our proposed VD-Diff outperforms SOTA methods on GoPro, DVD, BSD, and Real-World Video datasets.
Towards Highly Realistic Artistic Style Transfer via Stable Diffusion with Step-aware and Layer-aware Prompt
Apr 17, 2024
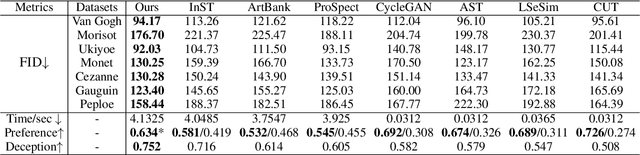
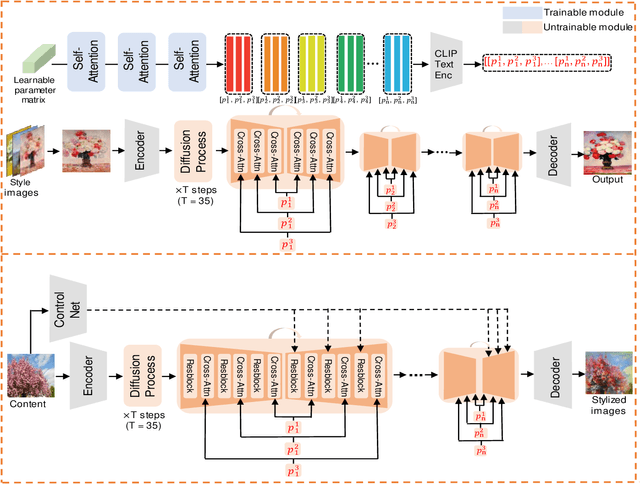
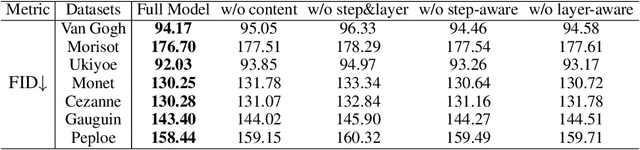
Artistic style transfer aims to transfer the learned artistic style onto an arbitrary content image, generating artistic stylized images. Existing generative adversarial network-based methods fail to generate highly realistic stylized images and always introduce obvious artifacts and disharmonious patterns. Recently, large-scale pre-trained diffusion models opened up a new way for generating highly realistic artistic stylized images. However, diffusion model-based methods generally fail to preserve the content structure of input content images well, introducing some undesired content structure and style patterns. To address the above problems, we propose a novel pre-trained diffusion-based artistic style transfer method, called LSAST, which can generate highly realistic artistic stylized images while preserving the content structure of input content images well, without bringing obvious artifacts and disharmonious style patterns. Specifically, we introduce a Step-aware and Layer-aware Prompt Space, a set of learnable prompts, which can learn the style information from the collection of artworks and dynamically adjusts the input images' content structure and style pattern. To train our prompt space, we propose a novel inversion method, called Step-ware and Layer-aware Prompt Inversion, which allows the prompt space to learn the style information of the artworks collection. In addition, we inject a pre-trained conditional branch of ControlNet into our LSAST, which further improved our framework's ability to maintain content structure. Extensive experiments demonstrate that our proposed method can generate more highly realistic artistic stylized images than the state-of-the-art artistic style transfer methods.
AntDT: A Self-Adaptive Distributed Training Framework for Leader and Straggler Nodes
Apr 15, 2024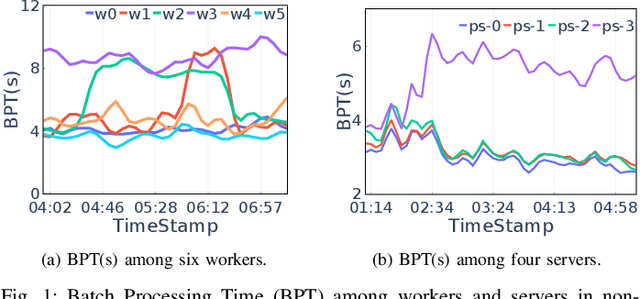
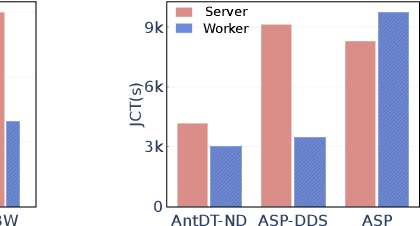
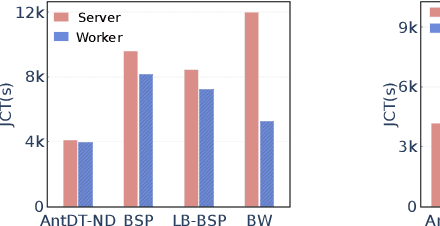
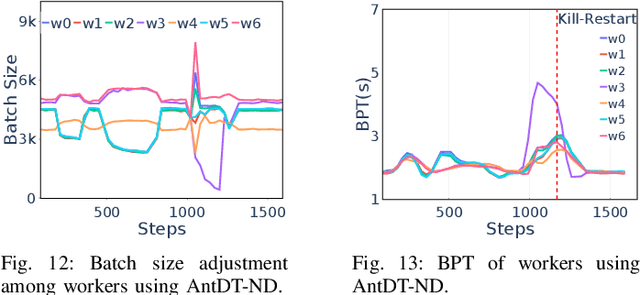
Many distributed training techniques like Parameter Server and AllReduce have been proposed to take advantage of the increasingly large data and rich features. However, stragglers frequently occur in distributed training due to resource contention and hardware heterogeneity, which significantly hampers the training efficiency. Previous works only address part of the stragglers and could not adaptively solve various stragglers in practice. Additionally, it is challenging to use a systematic framework to address all stragglers because different stragglers require diverse data allocation and fault-tolerance mechanisms. Therefore, this paper proposes a unified distributed training framework called AntDT (Ant Distributed Training Framework) to adaptively solve the straggler problems. Firstly, the framework consists of four components, including the Stateful Dynamic Data Sharding service, Monitor, Controller, and Agent. These components work collaboratively to efficiently distribute workloads and provide a range of pre-defined straggler mitigation methods with fault tolerance, thereby hiding messy details of data allocation and fault handling. Secondly, the framework provides a high degree of flexibility, allowing for the customization of straggler mitigation solutions based on the specific circumstances of the cluster. Leveraging this flexibility, we introduce two straggler mitigation solutions, namely AntDT-ND for non-dedicated clusters and AntDT-DD for dedicated clusters, as practical examples to resolve various types of stragglers at Ant Group. Justified by our comprehensive experiments and industrial deployment statistics, AntDT outperforms other SOTA methods more than 3x in terms of training efficiency. Additionally, in Alipay's homepage recommendation scenario, using AntDT reduces the training duration of the ranking model from 27.8 hours to just 5.4 hours.
InferTurbo: A Scalable System for Boosting Full-graph Inference of Graph Neural Network over Huge Graphs
Jul 01, 2023GNN inference is a non-trivial task, especially in industrial scenarios with giant graphs, given three main challenges, i.e., scalability tailored for full-graph inference on huge graphs, inconsistency caused by stochastic acceleration strategies (e.g., sampling), and the serious redundant computation issue. To address the above challenges, we propose a scalable system named InferTurbo to boost the GNN inference tasks in industrial scenarios. Inspired by the philosophy of ``think-like-a-vertex", a GAS-like (Gather-Apply-Scatter) schema is proposed to describe the computation paradigm and data flow of GNN inference. The computation of GNNs is expressed in an iteration manner, in which a vertex would gather messages via in-edges and update its state information by forwarding an associated layer of GNNs with those messages and then send the updated information to other vertexes via out-edges. Following the schema, the proposed InferTurbo can be built with alternative backends (e.g., batch processing system or graph computing system). Moreover, InferTurbo introduces several strategies like shadow-nodes and partial-gather to handle nodes with large degrees for better load balancing. With InferTurbo, GNN inference can be hierarchically conducted over the full graph without sampling and redundant computation. Experimental results demonstrate that our system is robust and efficient for inference tasks over graphs containing some hub nodes with many adjacent edges. Meanwhile, the system gains a remarkable performance compared with the traditional inference pipeline, and it can finish a GNN inference task over a graph with tens of billions of nodes and hundreds of billions of edges within 2 hours.
SCMA Codebook Design Based on Uniquely Decomposable Constellation Groups
Mar 06, 2021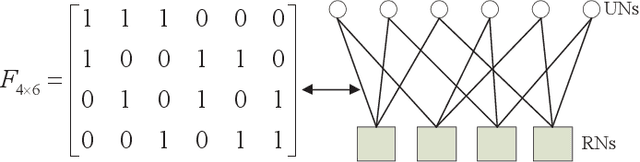
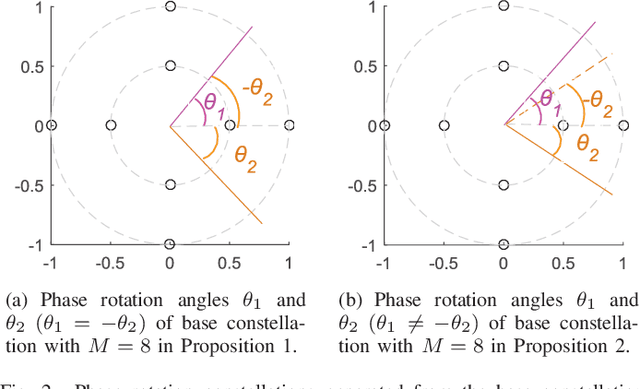
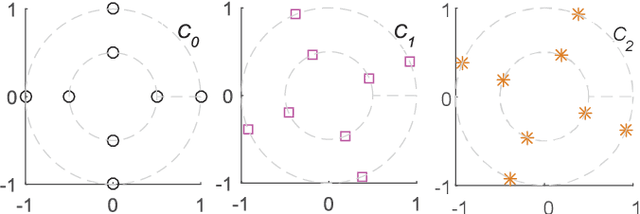
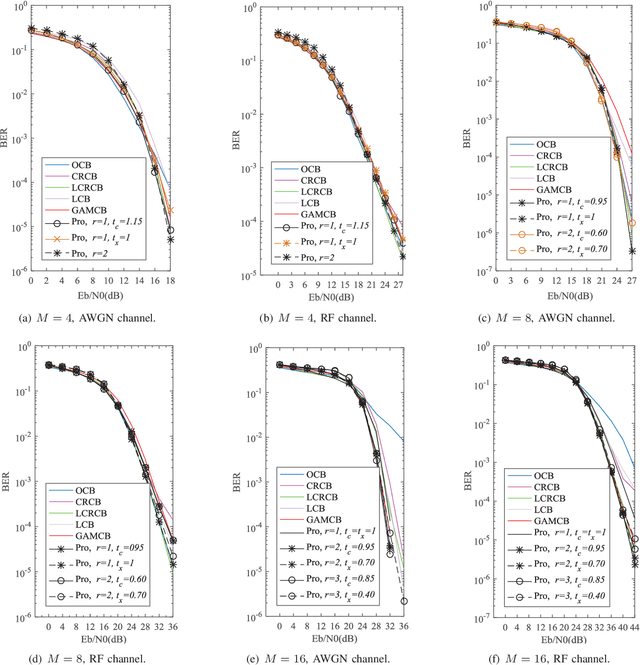
Sparse code multiple access (SCMA), which helps improve spectrum efficiency (SE) and enhance connectivity, has been proposed as a non-orthogonal multiple access (NOMA) scheme for 5G systems. In SCMA, codebook design determines system overload ratio and detection performance at a receiver. In this paper, an SCMA codebook design approach is proposed based on uniquely decomposable constellation group (UDCG). We show that there are $N+1 (N \geq 1)$ constellations in the proposed UDCG, each of which has $M (M \geq 2)$ constellation points. These constellations are allocated to users sharing the same resource. Combining the constellations allocated on multiple resources of each user, we can obtain UDCG-based codebook sets. Bit error ratio (BER) performance will be discussed in terms of coding gain maximization with superimposed constellations and UDCG-based codebooks. Simulation results demonstrate that the superimposed constellation of each resource has large minimum Euclidean distance (MED) and meets uniquely decodable constraint. Thus, BER performance of the proposed codebook design approach outperforms that of the existing codebook design schemes in both uncoded and coded SCMA systems, especially for large-size codebooks.
DSSLP: A Distributed Framework for Semi-supervised Link Prediction
Mar 10, 2020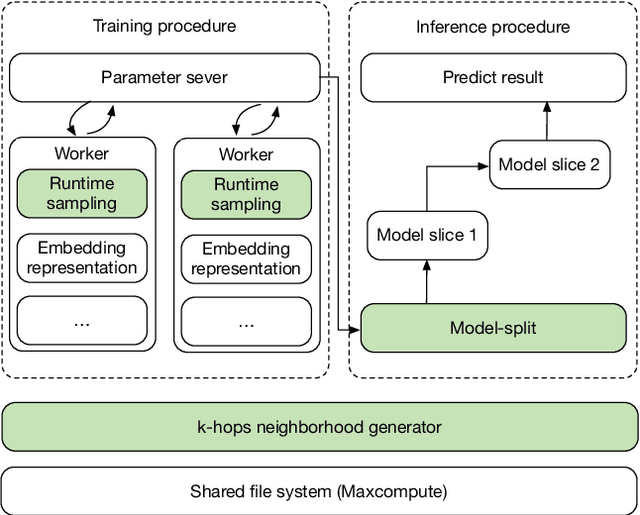
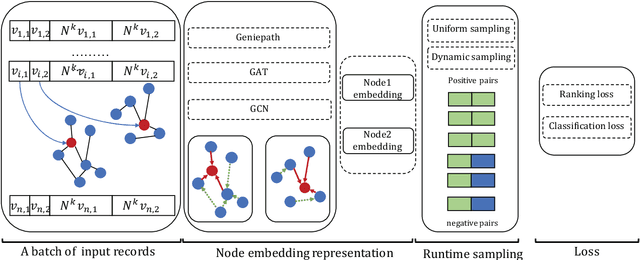
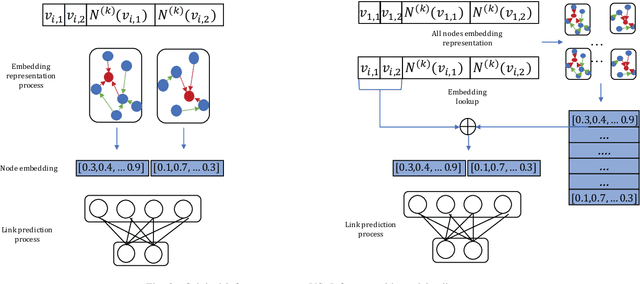
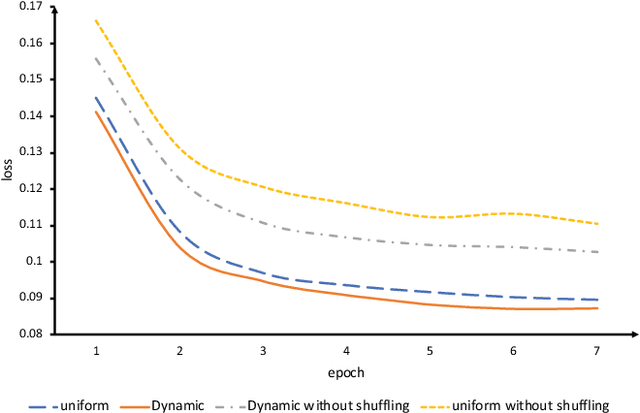
Link prediction is widely used in a variety of industrial applications, such as merchant recommendation, fraudulent transaction detection, and so on. However, it's a great challenge to train and deploy a link prediction model on industrial-scale graphs with billions of nodes and edges. In this work, we present a scalable and distributed framework for semi-supervised link prediction problem (named DSSLP), which is able to handle industrial-scale graphs. Instead of training model on the whole graph, DSSLP is proposed to train on the \emph{$k$-hops neighborhood} of nodes in a mini-batch setting, which helps reduce the scale of the input graph and distribute the training procedure. In order to generate negative examples effectively, DSSLP contains a distributed batched runtime sampling module. It implements uniform and dynamic sampling approaches, and is able to adaptively construct positive and negative examples to guide the training process. Moreover, DSSLP proposes a model-split strategy to accelerate the speed of inference process of the link prediction task. Experimental results demonstrate that the effectiveness and efficiency of DSSLP in serval public datasets as well as real-world datasets of industrial-scale graphs.