 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Video Deblurring with Wavelet-Aware Dynamic Transformer and Diffusion Model
Aug 24, 2024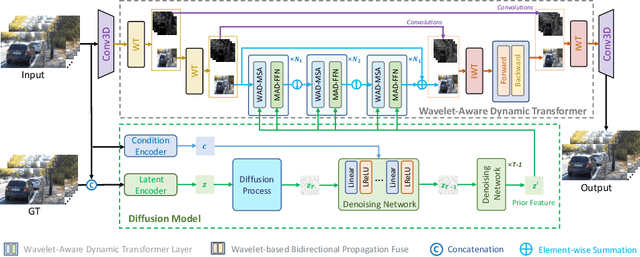
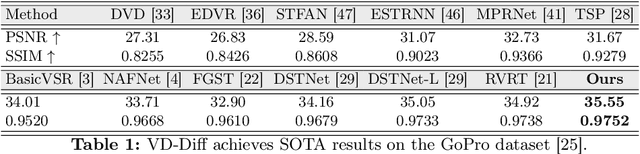
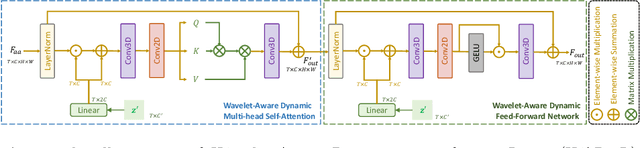
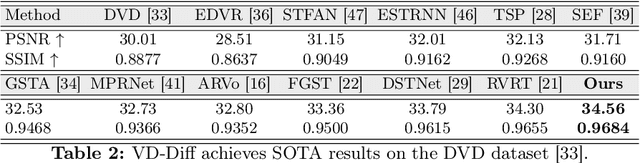
Current video deblurring methods have limitations in recovering high-frequency information since the regression losses are conservative with high-frequency details. Since Diffusion Models (DMs) have strong capabilities in generating high-frequency details, we consider introducing DMs into the video deblurring task. However, we found that directly applying DMs to the video deblurring task has the following problems: (1) DMs require many iteration steps to generate videos from Gaussian noise, which consumes many computational resources. (2) DMs are easily misled by the blurry artifacts in the video, resulting in irrational content and distortion of the deblurred video. To address the above issues, we propose a novel video deblurring framework VD-Diff that integrates the diffusion model into the Wavelet-Aware Dynamic Transformer (WADT). Specifically, we perform the diffusion model in a highly compact latent space to generate prior features containing high-frequency information that conforms to the ground truth distribution. We design the WADT to preserve and recover the low-frequency information in the video while utilizing the high-frequency information generated by the diffusion model. Extensive experiments show that our proposed VD-Diff outperforms SOTA methods on GoPro, DVD, BSD, and Real-World Video datasets.
Rethink Arbitrary Style Transfer with Transformer and Contrastive Learning
Apr 21, 2024



Arbitrary style transfer holds widespread attention in research and boasts numerous practical applications. The existing methods, which either employ cross-attention to incorporate deep style attributes into content attributes or use adaptive normalization to adjust content features, fail to generate high-quality stylized images. In this paper, we introduce an innovative technique to improve the quality of stylized images. Firstly, we propose Style Consistency Instance Normalization (SCIN), a method to refine the alignment between content and style features. In addition, we have developed an Instance-based Contrastive Learning (ICL) approach designed to understand the relationships among various styles, thereby enhancing the quality of the resulting stylized images. Recognizing that VGG networks are more adept at extracting classification features and need to be better suited for capturing style features, we have also introduced the Perception Encoder (PE) to capture style features. Extensive experiments demonstrate that our proposed method generates high-quality stylized images and effectively prevents artifacts compared with the existing state-of-the-art methods.
ArtBank: Artistic Style Transfer with Pre-trained Diffusion Model and Implicit Style Prompt Bank
Dec 11, 2023



Artistic style transfer aims to repaint the content image with the learned artistic style. Existing artistic style transfer methods can be divided into two categories: small model-based approaches and pre-trained large-scale model-based approaches. Small model-based approaches can preserve the content strucuture, but fail to produce highly realistic stylized images and introduce artifacts and disharmonious patterns; Pre-trained large-scale model-based approaches can generate highly realistic stylized images but struggle with preserving the content structure. To address the above issues, we propose ArtBank, a novel artistic style transfer framework, to generate highly realistic stylized images while preserving the content structure of the content images. Specifically, to sufficiently dig out the knowledge embedded in pre-trained large-scale models, an Implicit Style Prompt Bank (ISPB), a set of trainable parameter matrices, is designed to learn and store knowledge from the collection of artworks and behave as a visual prompt to guide pre-trained large-scale models to generate highly realistic stylized images while preserving content structure. Besides, to accelerate training the above ISPB, we propose a novel Spatial-Statistical-based self-Attention Module (SSAM). The qualitative and quantitative experiments demonstrate the superiority of our proposed method over state-of-the-art artistic style transfer methods.