 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Video Deblurring with Wavelet-Aware Dynamic Transformer and Diffusion Model
Paper and Code
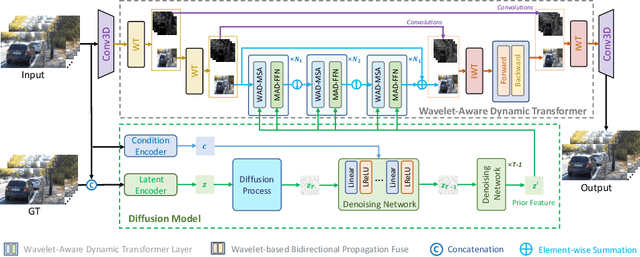
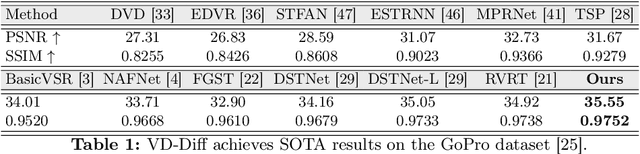
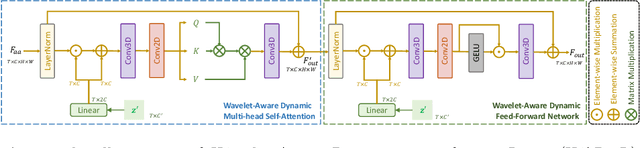
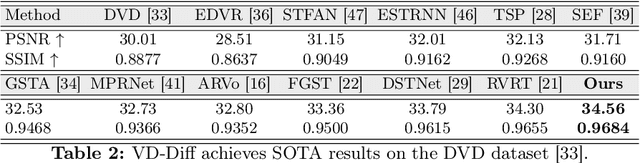
Current video deblurring methods have limitations in recovering high-frequency information since the regression losses are conservative with high-frequency details. Since Diffusion Models (DMs) have strong capabilities in generating high-frequency details, we consider introducing DMs into the video deblurring task. However, we found that directly applying DMs to the video deblurring task has the following problems: (1) DMs require many iteration steps to generate videos from Gaussian noise, which consumes many computational resources. (2) DMs are easily misled by the blurry artifacts in the video, resulting in irrational content and distortion of the deblurred video. To address the above issues, we propose a novel video deblurring framework VD-Diff that integrates the diffusion model into the Wavelet-Aware Dynamic Transformer (WADT). Specifically, we perform the diffusion model in a highly compact latent space to generate prior features containing high-frequency information that conforms to the ground truth distribution. We design the WADT to preserve and recover the low-frequency information in the video while utilizing the high-frequency information generated by the diffusion model. Extensive experiments show that our proposed VD-Diff outperforms SOTA methods on GoPro, DVD, BSD, and Real-World Video datasets.