 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferTurbo: A Scalable System for Boosting Full-graph Inference of Graph Neural Network over Huge Graphs
Jul 01, 2023GNN inference is a non-trivial task, especially in industrial scenarios with giant graphs, given three main challenges, i.e., scalability tailored for full-graph inference on huge graphs, inconsistency caused by stochastic acceleration strategies (e.g., sampling), and the serious redundant computation issue. To address the above challenges, we propose a scalable system named InferTurbo to boost the GNN inference tasks in industrial scenarios. Inspired by the philosophy of ``think-like-a-vertex", a GAS-like (Gather-Apply-Scatter) schema is proposed to describe the computation paradigm and data flow of GNN inference. The computation of GNNs is expressed in an iteration manner, in which a vertex would gather messages via in-edges and update its state information by forwarding an associated layer of GNNs with those messages and then send the updated information to other vertexes via out-edges. Following the schema, the proposed InferTurbo can be built with alternative backends (e.g., batch processing system or graph computing system). Moreover, InferTurbo introduces several strategies like shadow-nodes and partial-gather to handle nodes with large degrees for better load balancing. With InferTurbo, GNN inference can be hierarchically conducted over the full graph without sampling and redundant computation. Experimental results demonstrate that our system is robust and efficient for inference tasks over graphs containing some hub nodes with many adjacent edges. Meanwhile, the system gains a remarkable performance compared with the traditional inference pipeline, and it can finish a GNN inference task over a graph with tens of billions of nodes and hundreds of billions of edges within 2 hours.
DSSLP: A Distributed Framework for Semi-supervised Link Prediction
Mar 10, 2020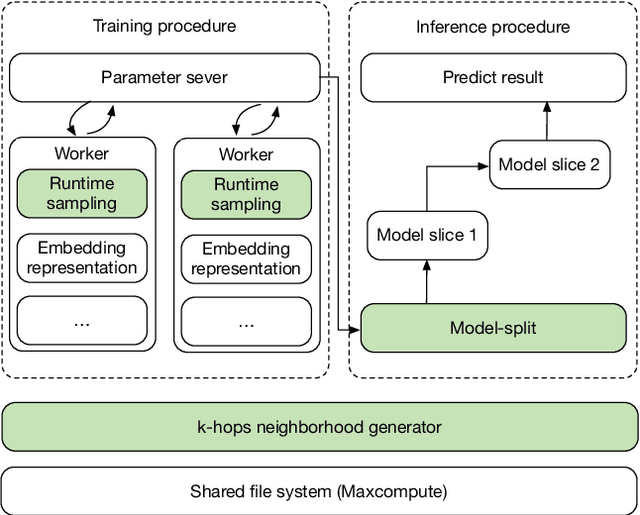
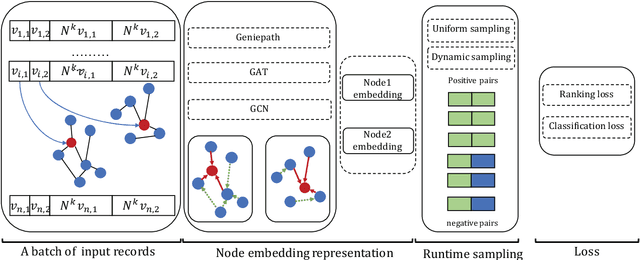
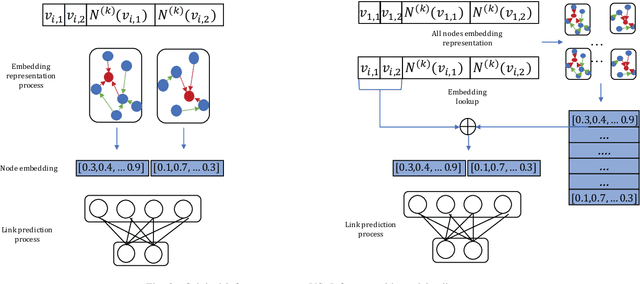
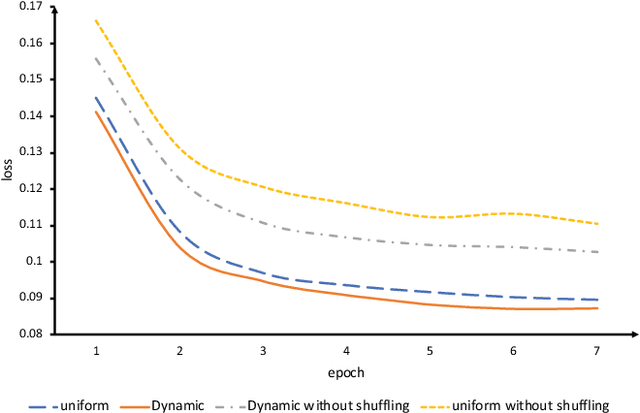
Link prediction is widely used in a variety of industrial applications, such as merchant recommendation, fraudulent transaction detection, and so on. However, it's a great challenge to train and deploy a link prediction model on industrial-scale graphs with billions of nodes and edges. In this work, we present a scalable and distributed framework for semi-supervised link prediction problem (named DSSLP), which is able to handle industrial-scale graphs. Instead of training model on the whole graph, DSSLP is proposed to train on the \emph{$k$-hops neighborhood} of nodes in a mini-batch setting, which helps reduce the scale of the input graph and distribute the training procedure. In order to generate negative examples effectively, DSSLP contains a distributed batched runtime sampling module. It implements uniform and dynamic sampling approaches, and is able to adaptively construct positive and negative examples to guide the training process. Moreover, DSSLP proposes a model-split strategy to accelerate the speed of inference process of the link prediction task. Experimental results demonstrate that the effectiveness and efficiency of DSSLP in serval public datasets as well as real-world datasets of industrial-scale graphs.