 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNimbus: A Unified Embodied Synthetic Data Generation Framework
Jan 29, 2026Scaling data volume and diversity is critical for generalizing embodied intelligence. While synthetic data generation offers a scalable alternative to expensive physical data acquisition, existing pipelines remain fragmented and task-specific. This isolation leads to significant engineering inefficiency and system instability, failing to support the sustained, high-throughput data generation required for foundation model training. To address these challenges, we present Nimbus, a unified synthetic data generation framework designed to integrate heterogeneous navigation and manipulation pipelines. Nimbus introduces a modular four-layer architecture featuring a decoupled execution model that separates trajectory planning, rendering, and storage into asynchronous stages. By implementing dynamic pipeline scheduling, global load balancing, distributed fault tolerance, and backend-specific rendering optimizations, the system maximizes resource utilization across CPU, GPU, and I/O resources. Our evaluation demonstrates that Nimbus achieves a 2-3X improvement in end-to-end throughput compared to unoptimized baselines and ensuring robust, long-term operation in large-scale distributed environments. This framework serves as the production backbone for the InternData suite, enabling seamless cross-domain data synthesis.
LandMarkSystem Technical Report
Mar 27, 20253D reconstruction is vital for applications in autonomous driving, virtual reality, augmented reality, and the metaverse. Recent advancements such as Neural Radiance Fields(NeRF) and 3D Gaussian Splatting (3DGS) have transformed the field, yet traditional deep learning frameworks struggle to meet the increasing demands for scene quality and scale. This paper introduces LandMarkSystem, a novel computing framework designed to enhance multi-scale scene reconstruction and rendering. By leveraging a componentized model adaptation layer, LandMarkSystem supports various NeRF and 3DGS structures while optimizing computational efficiency through distributed parallel computing and model parameter offloading. Our system addresses the limitations of existing frameworks, providing dedicated operators for complex 3D sparse computations, thus facilitating efficient training and rapid inference over extensive scenes. Key contributions include a modular architecture, a dynamic loading strategy for limited resources, and proven capabilities across multiple representative algorithms.This comprehensive solution aims to advance the efficiency and effectiveness of 3D reconstruction tasks.To facilitate further research and collaboration, the source code and documentation for the LandMarkSystem project are publicly available in an open-source repository, accessing the repository at: https://github.com/InternLandMark/LandMarkSystem.
GS-Cache: A GS-Cache Inference Framework for Large-scale Gaussian Splatting Models
Feb 20, 2025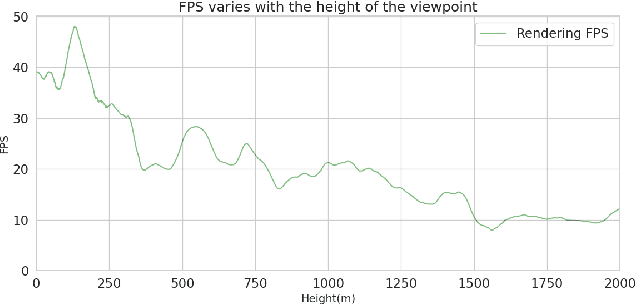
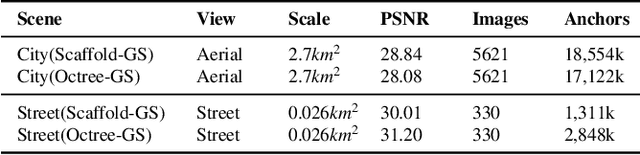
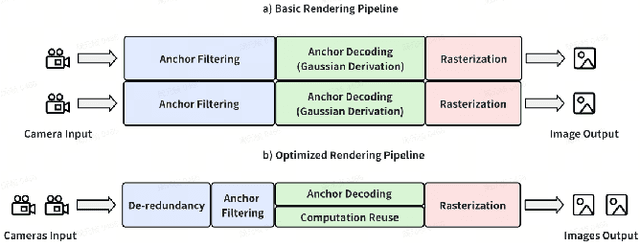
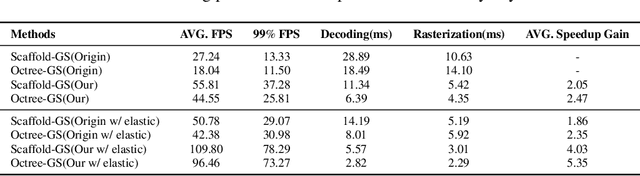
Rendering large-scale 3D Gaussian Splatting (3DGS) model faces significant challenges in achieving real-time, high-fidelity performance on consumer-grade devices. Fully realizing the potential of 3DGS in applications such as virtual reality (VR) requires addressing critical system-level challenges to support real-time, immersive experiences. We propose GS-Cache, an end-to-end framework that seamlessly integrates 3DGS's advanced representation with a highly optimized rendering system. GS-Cache introduces a cache-centric pipeline to eliminate redundant computations, an efficiency-aware scheduler for elastic multi-GPU rendering, and optimized CUDA kernels to overcome computational bottlenecks. This synergy between 3DGS and system design enables GS-Cache to achieve up to 5.35x performance improvement, 35% latency reduction, and 42% lower GPU memory usage, supporting 2K binocular rendering at over 120 FPS with high visual quality. By bridging the gap between 3DGS's representation power and the demands of VR systems, GS-Cache establishes a scalable and efficient framework for real-time neural rendering in immersive environments.
InferTurbo: A Scalable System for Boosting Full-graph Inference of Graph Neural Network over Huge Graphs
Jul 01, 2023GNN inference is a non-trivial task, especially in industrial scenarios with giant graphs, given three main challenges, i.e., scalability tailored for full-graph inference on huge graphs, inconsistency caused by stochastic acceleration strategies (e.g., sampling), and the serious redundant computation issue. To address the above challenges, we propose a scalable system named InferTurbo to boost the GNN inference tasks in industrial scenarios. Inspired by the philosophy of ``think-like-a-vertex", a GAS-like (Gather-Apply-Scatter) schema is proposed to describe the computation paradigm and data flow of GNN inference. The computation of GNNs is expressed in an iteration manner, in which a vertex would gather messages via in-edges and update its state information by forwarding an associated layer of GNNs with those messages and then send the updated information to other vertexes via out-edges. Following the schema, the proposed InferTurbo can be built with alternative backends (e.g., batch processing system or graph computing system). Moreover, InferTurbo introduces several strategies like shadow-nodes and partial-gather to handle nodes with large degrees for better load balancing. With InferTurbo, GNN inference can be hierarchically conducted over the full graph without sampling and redundant computation. Experimental results demonstrate that our system is robust and efficient for inference tasks over graphs containing some hub nodes with many adjacent edges. Meanwhile, the system gains a remarkable performance compared with the traditional inference pipeline, and it can finish a GNN inference task over a graph with tens of billions of nodes and hundreds of billions of edges within 2 hours.