 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNimbus: A Unified Embodied Synthetic Data Generation Framework
Jan 29, 2026Scaling data volume and diversity is critical for generalizing embodied intelligence. While synthetic data generation offers a scalable alternative to expensive physical data acquisition, existing pipelines remain fragmented and task-specific. This isolation leads to significant engineering inefficiency and system instability, failing to support the sustained, high-throughput data generation required for foundation model training. To address these challenges, we present Nimbus, a unified synthetic data generation framework designed to integrate heterogeneous navigation and manipulation pipelines. Nimbus introduces a modular four-layer architecture featuring a decoupled execution model that separates trajectory planning, rendering, and storage into asynchronous stages. By implementing dynamic pipeline scheduling, global load balancing, distributed fault tolerance, and backend-specific rendering optimizations, the system maximizes resource utilization across CPU, GPU, and I/O resources. Our evaluation demonstrates that Nimbus achieves a 2-3X improvement in end-to-end throughput compared to unoptimized baselines and ensuring robust, long-term operation in large-scale distributed environments. This framework serves as the production backbone for the InternData suite, enabling seamless cross-domain data synthesis.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
LandMarkSystem Technical Report
Mar 27, 20253D reconstruction is vital for applications in autonomous driving, virtual reality, augmented reality, and the metaverse. Recent advancements such as Neural Radiance Fields(NeRF) and 3D Gaussian Splatting (3DGS) have transformed the field, yet traditional deep learning frameworks struggle to meet the increasing demands for scene quality and scale. This paper introduces LandMarkSystem, a novel computing framework designed to enhance multi-scale scene reconstruction and rendering. By leveraging a componentized model adaptation layer, LandMarkSystem supports various NeRF and 3DGS structures while optimizing computational efficiency through distributed parallel computing and model parameter offloading. Our system addresses the limitations of existing frameworks, providing dedicated operators for complex 3D sparse computations, thus facilitating efficient training and rapid inference over extensive scenes. Key contributions include a modular architecture, a dynamic loading strategy for limited resources, and proven capabilities across multiple representative algorithms.This comprehensive solution aims to advance the efficiency and effectiveness of 3D reconstruction tasks.To facilitate further research and collaboration, the source code and documentation for the LandMarkSystem project are publicly available in an open-source repository, accessing the repository at: https://github.com/InternLandMark/LandMarkSystem.
Infinite Mobility: Scalable High-Fidelity Synthesis of Articulated Objects via Procedural Generation
Mar 17, 2025Large-scale articulated objects with high quality are desperately needed for multiple tasks related to embodied AI. Most existing methods for creating articulated objects are either data-driven or simulation based, which are limited by the scale and quality of the training data or the fidelity and heavy labour of the simulation. In this paper, we propose Infinite Mobility, a novel method for synthesizing high-fidelity articulated objects through procedural generation. User study and quantitative evaluation demonstrate that our method can produce results that excel current state-of-the-art methods and are comparable to human-annotated datasets in both physics property and mesh quality. Furthermore, we show that our synthetic data can be used as training data for generative models, enabling next-step scaling up. Code is available at https://github.com/Intern-Nexus/Infinite-Mobility
GS-Cache: A GS-Cache Inference Framework for Large-scale Gaussian Splatting Models
Feb 20, 2025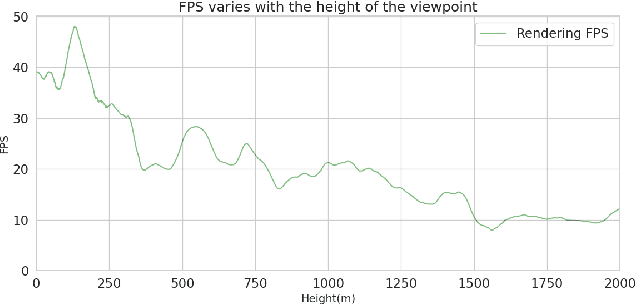
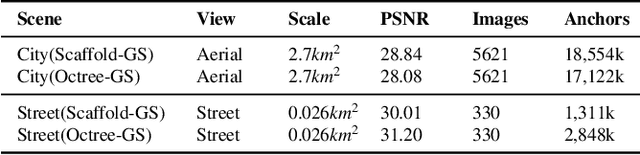
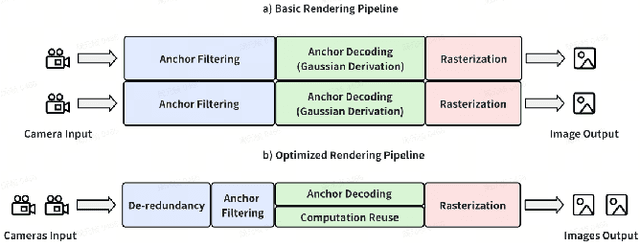
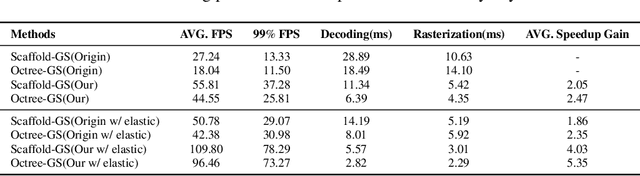
Rendering large-scale 3D Gaussian Splatting (3DGS) model faces significant challenges in achieving real-time, high-fidelity performance on consumer-grade devices. Fully realizing the potential of 3DGS in applications such as virtual reality (VR) requires addressing critical system-level challenges to support real-time, immersive experiences. We propose GS-Cache, an end-to-end framework that seamlessly integrates 3DGS's advanced representation with a highly optimized rendering system. GS-Cache introduces a cache-centric pipeline to eliminate redundant computations, an efficiency-aware scheduler for elastic multi-GPU rendering, and optimized CUDA kernels to overcome computational bottlenecks. This synergy between 3DGS and system design enables GS-Cache to achieve up to 5.35x performance improvement, 35% latency reduction, and 42% lower GPU memory usage, supporting 2K binocular rendering at over 120 FPS with high visual quality. By bridging the gap between 3DGS's representation power and the demands of VR systems, GS-Cache establishes a scalable and efficient framework for real-time neural rendering in immersive environments.