 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoSim: Egocentric World Simulator for Embodied Interaction Generation
Apr 01, 2026We introduce EgoSim, a closed-loop egocentric world simulator that generates spatially consistent interaction videos and persistently updates the underlying 3D scene state for continuous simulation. Existing egocentric simulators either lack explicit 3D grounding, causing structural drift under viewpoint changes, or treat the scene as static, failing to update world states across multi-stage interactions. EgoSim addresses both limitations by modeling 3D scenes as updatable world states. We generate embodiment interactions via a Geometry-action-aware Observation Simulation model, with spatial consistency from an Interaction-aware State Updating module. To overcome the critical data bottleneck posed by the difficulty in acquiring densely aligned scene-interaction training pairs, we design a scalable pipeline that extracts static point clouds, camera trajectories, and embodiment actions from in-the-wild large-scale monocular egocentric videos. We further introduce EgoCap, a capture system that enables low-cost real-world data collection with uncalibrated smartphones. Extensive experiments demonstrate that EgoSim significantly outperforms existing methods in terms of visual quality, spatial consistency, and generalization to complex scenes and in-the-wild dexterous interactions, while supporting cross-embodiment transfer to robotic manipulation. Codes and datasets will be open soon. The project page is at egosimulator.github.io.
PnP-U3D: Plug-and-Play 3D Framework Bridging Autoregression and Diffusion for Unified Understanding and Generation
Feb 03, 2026The rapid progress of large multimodal models has inspired efforts toward unified frameworks that couple understanding and generation. While such paradigms have shown remarkable success in 2D, extending them to 3D remains largely underexplored. Existing attempts to unify 3D tasks under a single autoregressive (AR) paradigm lead to significant performance degradation due to forced signal quantization and prohibitive training cost. Our key insight is that the essential challenge lies not in enforcing a unified autoregressive paradigm, but in enabling effective information interaction between generation and understanding while minimally compromising their inherent capabilities and leveraging pretrained models to reduce training cost. Guided by this perspective, we present the first unified framework for 3D understanding and generation that combines autoregression with diffusion. Specifically, we adopt an autoregressive next-token prediction paradigm for 3D understanding, and a continuous diffusion paradigm for 3D generation. A lightweight transformer bridges the feature space of large language models and the conditional space of 3D diffusion models, enabling effective cross-modal information exchange while preserving the priors learned by standalone models. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across diverse 3D understanding and generation benchmarks, while also excelling in 3D editing tasks. These results highlight the potential of unified AR+diffusion models as a promising direction for building more general-purpose 3D intelligence.
MesaTask: Towards Task-Driven Tabletop Scene Generation via 3D Spatial Reasoning
Sep 26, 2025
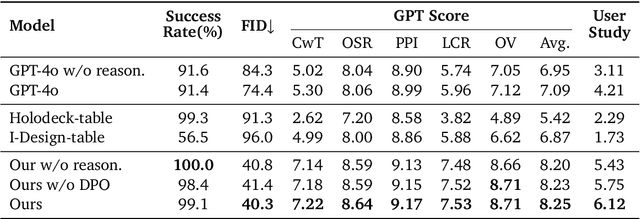
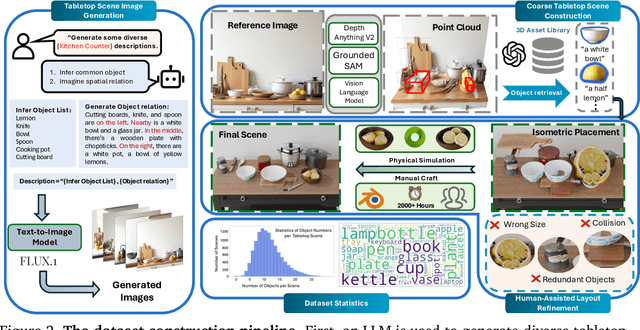
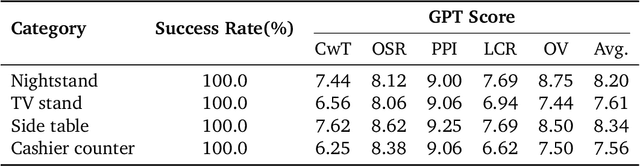
The ability of robots to interpret human instructions and execute manipulation tasks necessitates the availability of task-relevant tabletop scenes for training. However, traditional methods for creating these scenes rely on time-consuming manual layout design or purely randomized layouts, which are limited in terms of plausibility or alignment with the tasks. In this paper, we formulate a novel task, namely task-oriented tabletop scene generation, which poses significant challenges due to the substantial gap between high-level task instructions and the tabletop scenes. To support research on such a challenging task, we introduce MesaTask-10K, a large-scale dataset comprising approximately 10,700 synthetic tabletop scenes with manually crafted layouts that ensure realistic layouts and intricate inter-object relations. To bridge the gap between tasks and scenes, we propose a Spatial Reasoning Chain that decomposes the generation process into object inference, spatial interrelation reasoning, and scene graph construction for the final 3D layout. We present MesaTask, an LLM-based framework that utilizes this reasoning chain and is further enhanced with DPO algorithms to generate physically plausible tabletop scenes that align well with given task descriptions. Exhaustive experiments demonstrate the superior performance of MesaTask compared to baselines in generating task-conforming tabletop scenes with realistic layouts. Project page is at https://mesatask.github.io/
MeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds
Aug 20, 2025Reconstructing 3D objects into editable programs is pivotal for applications like reverse engineering and shape editing. However, existing methods often rely on limited domain-specific languages (DSLs) and small-scale datasets, restricting their ability to model complex geometries and structures. To address these challenges, we introduce MeshCoder, a novel framework that reconstructs complex 3D objects from point clouds into editable Blender Python scripts. We develop a comprehensive set of expressive Blender Python APIs capable of synthesizing intricate geometries. Leveraging these APIs, we construct a large-scale paired object-code dataset, where the code for each object is decomposed into distinct semantic parts. Subsequently, we train a multimodal large language model (LLM) that translates 3D point cloud into executable Blender Python scripts. Our approach not only achieves superior performance in shape-to-code reconstruction tasks but also facilitates intuitive geometric and topological editing through convenient code modifications. Furthermore, our code-based representation enhances the reasoning capabilities of LLMs in 3D shape understanding tasks. Together, these contributions establish MeshCoder as a powerful and flexible solution for programmatic 3D shape reconstruction and understanding.
AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
May 29, 2025We introduce AnySplat, a feed forward network for novel view synthesis from uncalibrated image collections. In contrast to traditional neural rendering pipelines that demand known camera poses and per scene optimization, or recent feed forward methods that buckle under the computational weight of dense views, our model predicts everything in one shot. A single forward pass yields a set of 3D Gaussian primitives encoding both scene geometry and appearance, and the corresponding camera intrinsics and extrinsics for each input image. This unified design scales effortlessly to casually captured, multi view datasets without any pose annotations. In extensive zero shot evaluations, AnySplat matches the quality of pose aware baselines in both sparse and dense view scenarios while surpassing existing pose free approaches. Moreover, it greatly reduce rendering latency compared to optimization based neural fields, bringing real time novel view synthesis within reach for unconstrained capture settings.Project page: https://city-super.github.io/anysplat/
Infinite Mobility: Scalable High-Fidelity Synthesis of Articulated Objects via Procedural Generation
Mar 17, 2025Large-scale articulated objects with high quality are desperately needed for multiple tasks related to embodied AI. Most existing methods for creating articulated objects are either data-driven or simulation based, which are limited by the scale and quality of the training data or the fidelity and heavy labour of the simulation. In this paper, we propose Infinite Mobility, a novel method for synthesizing high-fidelity articulated objects through procedural generation. User study and quantitative evaluation demonstrate that our method can produce results that excel current state-of-the-art methods and are comparable to human-annotated datasets in both physics property and mesh quality. Furthermore, we show that our synthetic data can be used as training data for generative models, enabling next-step scaling up. Code is available at https://github.com/Intern-Nexus/Infinite-Mobility
Boosting 3D Object Generation through PBR Materials
Nov 25, 2024Automatic 3D content creation has gained increasing attention recently, due to its potential in various applications such as video games, film industry, and AR/VR. Recent advancements in diffusion models and multimodal models have notably improved the quality and efficiency of 3D object generation given a single RGB image. However, 3D objects generated even by state-of-the-art methods are still unsatisfactory compared to human-created assets. Considering only textures instead of materials makes these methods encounter challenges in photo-realistic rendering, relighting, and flexible appearance editing. And they also suffer from severe misalignment between geometry and high-frequency texture details. In this work, we propose a novel approach to boost the quality of generated 3D objects from the perspective of Physics-Based Rendering (PBR) materials. By analyzing the components of PBR materials, we choose to consider albedo, roughness, metalness, and bump maps. For albedo and bump maps, we leverage Stable Diffusion fine-tuned on synthetic data to extract these values, with novel usages of these fine-tuned models to obtain 3D consistent albedo UV and bump UV for generated objects. In terms of roughness and metalness maps, we adopt a semi-automatic process to provide room for interactive adjustment, which we believe is more practical. Extensive experiments demonstrate that our model is generally beneficial for various state-of-the-art generation methods, significantly boosting the quality and realism of their generated 3D objects, with natural relighting effects and substantially improved geometry.
RoomTex: Texturing Compositional Indoor Scenes via Iterative Inpainting
Jun 04, 2024
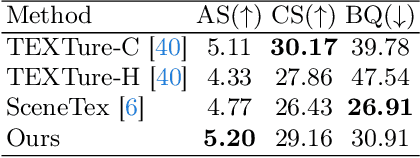
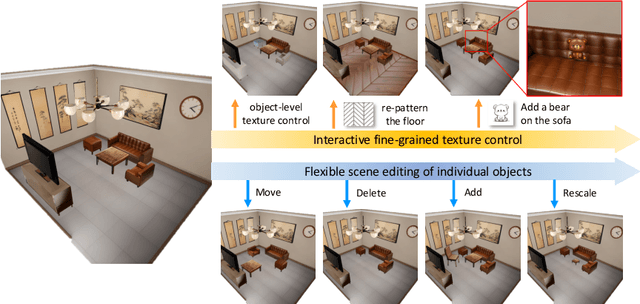
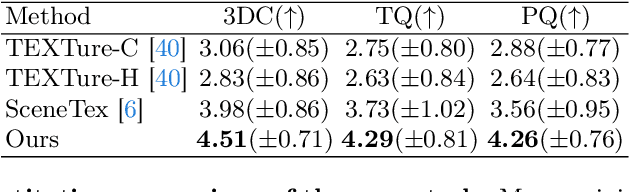
The advancement of diffusion models has pushed the boundary of text-to-3D object generation. While it is straightforward to composite objects into a scene with reasonable geometry, it is nontrivial to texture such a scene perfectly due to style inconsistency and occlusions between objects. To tackle these problems, we propose a coarse-to-fine 3D scene texturing framework, referred to as RoomTex, to generate high-fidelity and style-consistent textures for untextured compositional scene meshes. In the coarse stage, RoomTex first unwraps the scene mesh to a panoramic depth map and leverages ControlNet to generate a room panorama, which is regarded as the coarse reference to ensure the global texture consistency. In the fine stage, based on the panoramic image and perspective depth maps, RoomTex will refine and texture every single object in the room iteratively along a series of selected camera views, until this object is completely painted. Moreover, we propose to maintain superior alignment between RGB and depth spaces via subtle edge detection methods. Extensive experiments show our method is capable of generating high-quality and diverse room textures, and more importantly, supporting interactive fine-grained texture control and flexible scene editing thanks to our inpainting-based framework and compositional mesh input. Our project page is available at https://qwang666.github.io/RoomTex/.
TELA: Text to Layer-wise 3D Clothed Human Generation
Apr 25, 2024



This paper addresses the task of 3D clothed human generation from textural descriptions. Previous works usually encode the human body and clothes as a holistic model and generate the whole model in a single-stage optimization, which makes them struggle for clothing editing and meanwhile lose fine-grained control over the whole generation process. To solve this, we propose a layer-wise clothed human representation combined with a progressive optimization strategy, which produces clothing-disentangled 3D human models while providing control capacity for the generation process. The basic idea is progressively generating a minimal-clothed human body and layer-wise clothes. During clothing generation, a novel stratified compositional rendering method is proposed to fuse multi-layer human models, and a new loss function is utilized to help decouple the clothing model from the human body. The proposed method achieves high-quality disentanglement, which thereby provides an effective way for 3D garment generation. Extensive experiments demonstrate that our approach achieves state-of-the-art 3D clothed human generation while also supporting cloth editing applications such as virtual try-on. Project page: http://jtdong.com/tela_layer/
GetMesh: A Controllable Model for High-quality Mesh Generation and Manipulation
Mar 18, 2024
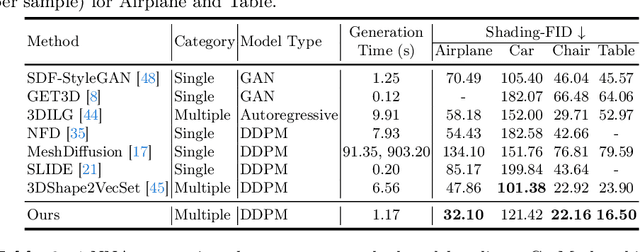
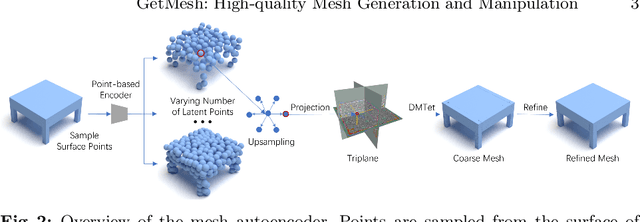
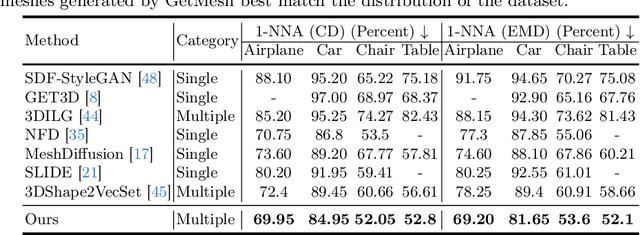
Mesh is a fundamental representation of 3D assets in various industrial applications, and is widely supported by professional softwares. However, due to its irregular structure, mesh creation and manipulation is often time-consuming and labor-intensive. In this paper, we propose a highly controllable generative model, GetMesh, for mesh generation and manipulation across different categories. By taking a varying number of points as the latent representation, and re-organizing them as triplane representation, GetMesh generates meshes with rich and sharp details, outperforming both single-category and multi-category counterparts. Moreover, it also enables fine-grained control over the generation process that previous mesh generative models cannot achieve, where changing global/local mesh topologies, adding/removing mesh parts, and combining mesh parts across categories can be intuitively, efficiently, and robustly accomplished by adjusting the number, positions or features of latent points. Project page is https://getmesh.github.io.