 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinauralFlow: A Causal and Streamable Approach for High-Quality Binaural Speech Synthesis with Flow Matching Models
May 28, 2025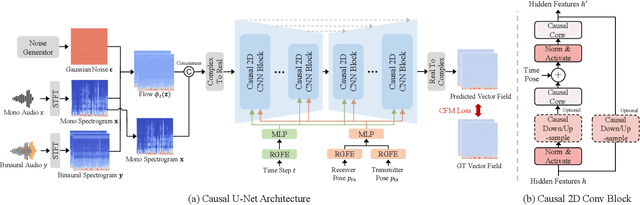
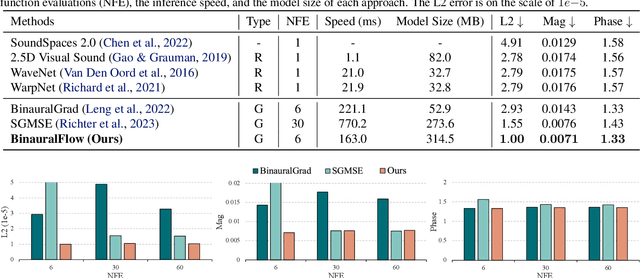
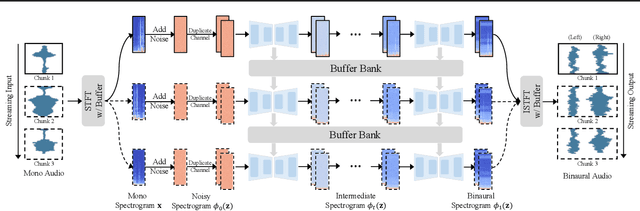
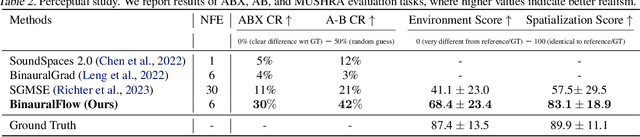
Binaural rendering aims to synthesize binaural audio that mimics natural hearing based on a mono audio and the locations of the speaker and listener. Although many methods have been proposed to solve this problem, they struggle with rendering quality and streamable inference. Synthesizing high-quality binaural audio that is indistinguishable from real-world recordings requires precise modeling of binaural cues, room reverb, and ambient sounds. Additionally, real-world applications demand streaming inference. To address these challenges, we propose a flow matching based streaming binaural speech synthesis framework called BinauralFlow. We consider binaural rendering to be a generation problem rather than a regression problem and design a conditional flow matching model to render high-quality audio. Moreover, we design a causal U-Net architecture that estimates the current audio frame solely based on past information to tailor generative models for streaming inference. Finally, we introduce a continuous inference pipeline incorporating streaming STFT/ISTFT operations, a buffer bank, a midpoint solver, and an early skip schedule to improve rendering continuity and speed. Quantitative and qualitative evaluations demonstrate the superiority of our method over SOTA approaches. A perceptual study further reveals that our model is nearly indistinguishable from real-world recordings, with a $42\%$ confusion rate.
SoundVista: Novel-View Ambient Sound Synthesis via Visual-Acoustic Binding
Apr 08, 2025



We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
Modeling and Driving Human Body Soundfields through Acoustic Primitives
Jul 18, 2024While rendering and animation of photorealistic 3D human body models have matured and reached an impressive quality over the past years, modeling the spatial audio associated with such full body models has been largely ignored so far. In this work, we present a framework that allows for high-quality spatial audio generation, capable of rendering the full 3D soundfield generated by a human body, including speech, footsteps, hand-body interactions, and others. Given a basic audio-visual representation of the body in form of 3D body pose and audio from a head-mounted microphone, we demonstrate that we can render the full acoustic scene at any point in 3D space efficiently and accurately. To enable near-field and realtime rendering of sound, we borrow the idea of volumetric primitives from graphical neural rendering and transfer them into the acoustic domain. Our acoustic primitives result in an order of magnitude smaller soundfield representations and overcome deficiencies in near-field rendering compared to previous approaches.
Sounding Bodies: Modeling 3D Spatial Sound of Humans Using Body Pose and Audio
Nov 01, 2023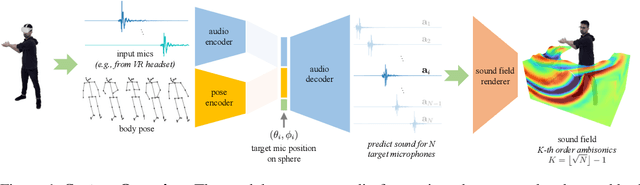

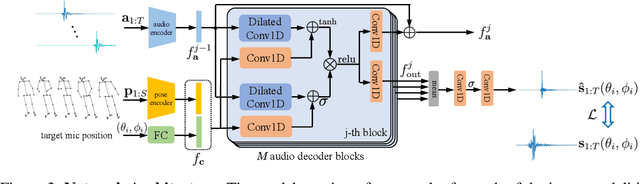
While 3D human body modeling has received much attention in computer vision, modeling the acoustic equivalent, i.e. modeling 3D spatial audio produced by body motion and speech, has fallen short in the community. To close this gap, we present a model that can generate accurate 3D spatial audio for full human bodies. The system consumes, as input, audio signals from headset microphones and body pose, and produces, as output, a 3D sound field surrounding the transmitter's body, from which spatial audio can be rendered at any arbitrary position in the 3D space. We collect a first-of-its-kind multimodal dataset of human bodies, recorded with multiple cameras and a spherical array of 345 microphones. In an empirical evaluation, we demonstrate that our model can produce accurate body-induced sound fields when trained with a suitable loss. Dataset and code are available online.
Reconstructing the Dynamic Directivity of Unconstrained Speech
Sep 09, 2022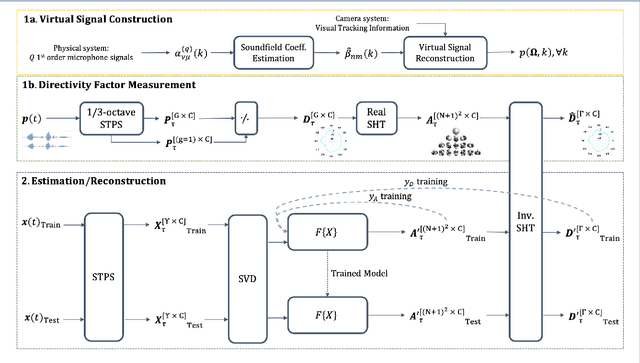
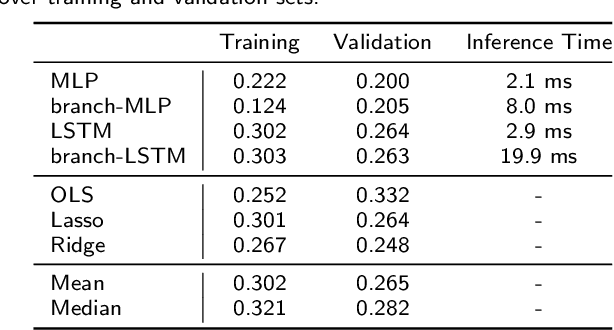

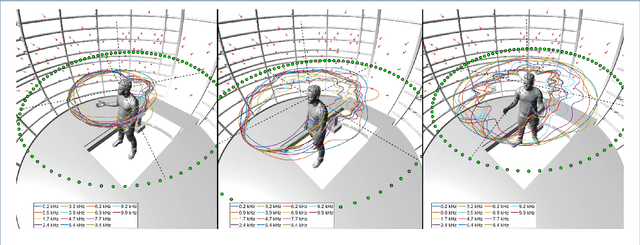
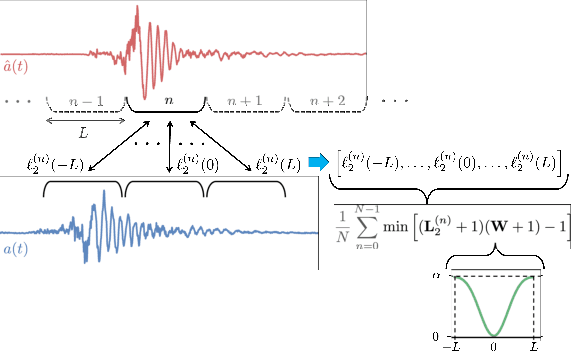
An accurate model of natural speech directivity is an important step toward achieving realistic vocal presence within a virtual communication setting. In this article, we propose a method to estimate and reconstruct the spatial energy distribution pattern of natural, unconstrained speech. We detail our method in two stages. Using recordings of speech captured by a real, static microphone array, we create a virtual array that tracks with the movement of the speaker over time. We use this egocentric virtual array to measure and encode the high-resolution directivity pattern of the speech signal as it dynamically evolves with natural speech and movement. Utilizing this encoded directivity representation, we train a machine learning model that leverages to estimate the full, dynamic directivity pattern when given a limited set of speech signals, as would be the case when speech is recorded using the microphones on a head-mounted display (HMD). We examine a variety of model architectures and training paradigms, and discuss the utility and practicality of each implementation. Our results demonstrate that neural networks can be used to regress from limited speech information to an accurate, dynamic estimation of the full directivity pattern.
End-to-End Binaural Speech Synthesis
Jul 08, 2022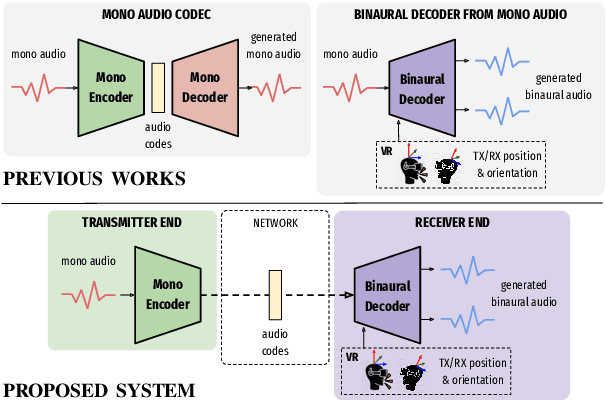
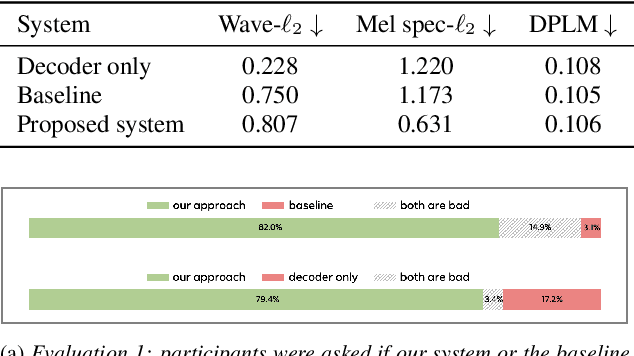
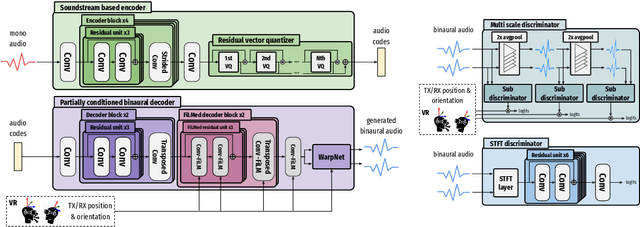

In this work, we present an end-to-end binaural speech synthesis system that combines a low-bitrate audio codec with a powerful binaural decoder that is capable of accurate speech binauralization while faithfully reconstructing environmental factors like ambient noise or reverb. The network is a modified vector-quantized variational autoencoder, trained with several carefully designed objectives, including an adversarial loss. We evaluate the proposed system on an internal binaural dataset with objective metrics and a perceptual study. Results show that the proposed approach matches the ground truth data more closely than previous methods. In particular, we demonstrate the capability of the adversarial loss in capturing environment effects needed to create an authentic auditory scene.
Implicit Neural Spatial Filtering for Multichannel Source Separation in the Waveform Domain
Jun 30, 2022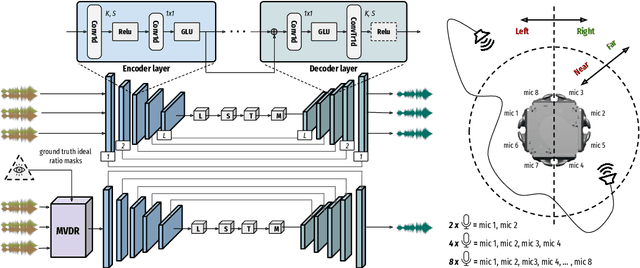
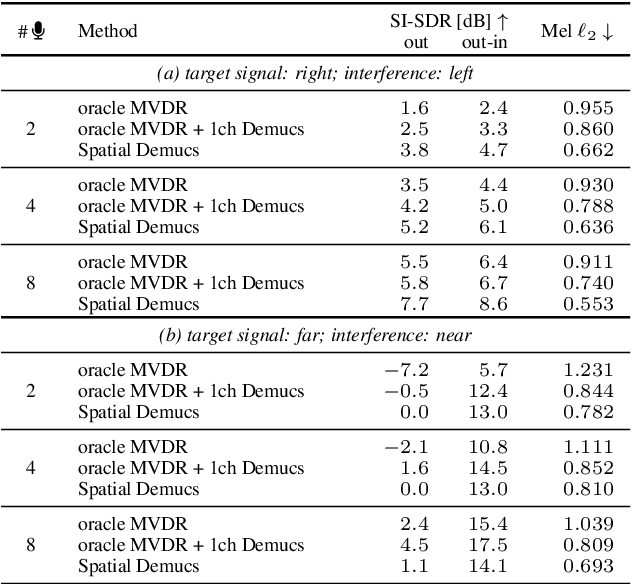
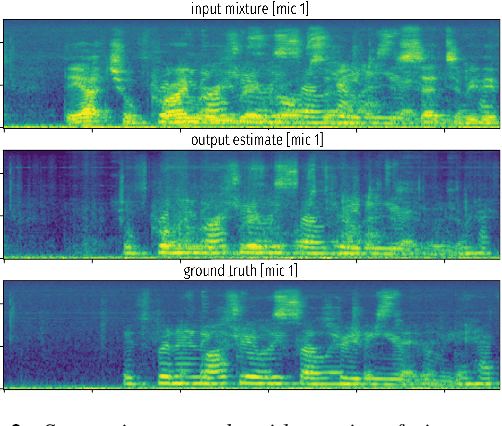
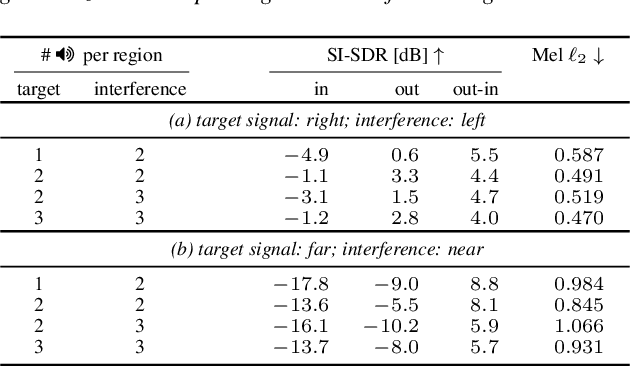
We present a single-stage casual waveform-to-waveform multichannel model that can separate moving sound sources based on their broad spatial locations in a dynamic acoustic scene. We divide the scene into two spatial regions containing, respectively, the target and the interfering sound sources. The model is trained end-to-end and performs spatial processing implicitly, without any components based on traditional processing or use of hand-crafted spatial features. We evaluate the proposed model on a real-world dataset and show that the model matches the performance of an oracle beamformer followed by a state-of-the-art single-channel enhancement network.
Audio-Visual Speech Codecs: Rethinking Audio-Visual Speech Enhancement by Re-Synthesis
Mar 31, 2022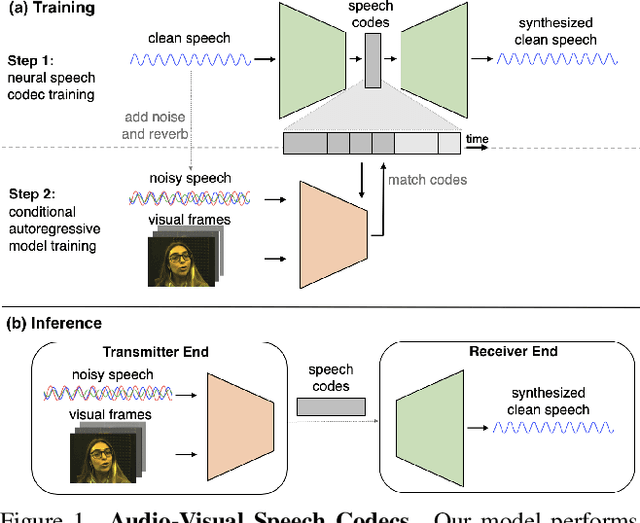
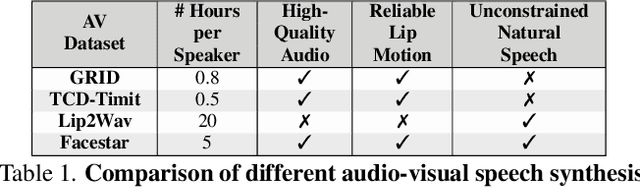
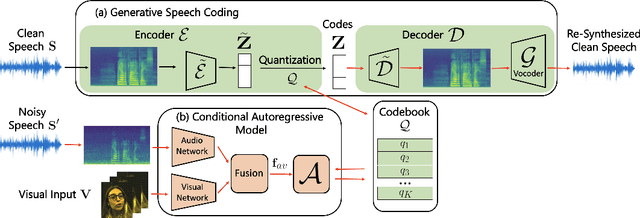

Since facial actions such as lip movements contain significant information about speech content, it is not surprising that audio-visual speech enhancement methods are more accurate than their audio-only counterparts. Yet, state-of-the-art approaches still struggle to generate clean, realistic speech without noise artifacts and unnatural distortions in challenging acoustic environments. In this paper, we propose a novel audio-visual speech enhancement framework for high-fidelity telecommunications in AR/VR. Our approach leverages audio-visual speech cues to generate the codes of a neural speech codec, enabling efficient synthesis of clean, realistic speech from noisy signals. Given the importance of speaker-specific cues in speech, we focus on developing personalized models that work well for individual speakers. We demonstrate the efficacy of our approach on a new audio-visual speech dataset collected in an unconstrained, large vocabulary setting, as well as existing audio-visual datasets, outperforming speech enhancement baselines on both quantitative metrics and human evaluation studies. Please see the supplemental video for qualitative results at https://github.com/facebookresearch/facestar/releases/download/paper_materials/video.mp4.