 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Binaural Speech Synthesis
Jul 08, 2022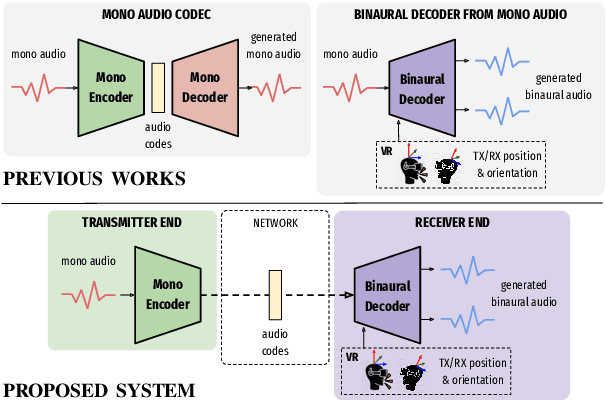
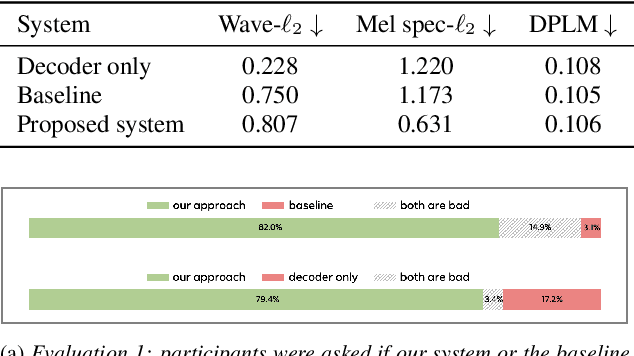
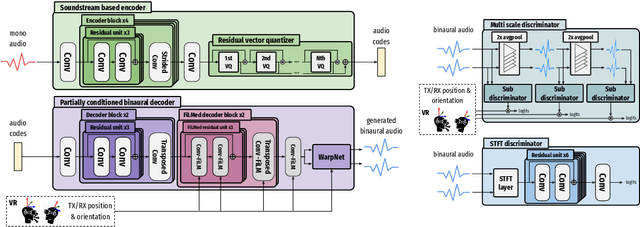

In this work, we present an end-to-end binaural speech synthesis system that combines a low-bitrate audio codec with a powerful binaural decoder that is capable of accurate speech binauralization while faithfully reconstructing environmental factors like ambient noise or reverb. The network is a modified vector-quantized variational autoencoder, trained with several carefully designed objectives, including an adversarial loss. We evaluate the proposed system on an internal binaural dataset with objective metrics and a perceptual study. Results show that the proposed approach matches the ground truth data more closely than previous methods. In particular, we demonstrate the capability of the adversarial loss in capturing environment effects needed to create an authentic auditory scene.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022



Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
DPLM: A Deep Perceptual Spatial-Audio Localization Metric
May 29, 2021



Subjective evaluations are critical for assessing the perceptual realism of sounds in audio-synthesis driven technologies like augmented and virtual reality. However, they are challenging to set up, fatiguing for users, and expensive. In this work, we tackle the problem of capturing the perceptual characteristics of localizing sounds. Specifically, we propose a framework for building a general purpose quality metric to assess spatial localization differences between two binaural recordings. We model localization similarity by utilizing activation-level distances from deep networks trained for direction of arrival (DOA) estimation. Our proposed metric (DPLM) outperforms baseline metrics on correlation with subjective ratings on a diverse set of datasets, even without the benefit of any human-labeled training data.