 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022



Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
Continual self-training with bootstrapped remixing for speech enhancement
Oct 19, 2021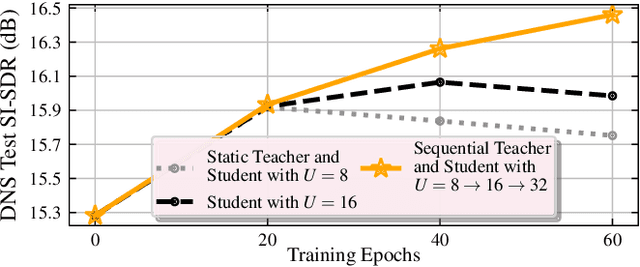
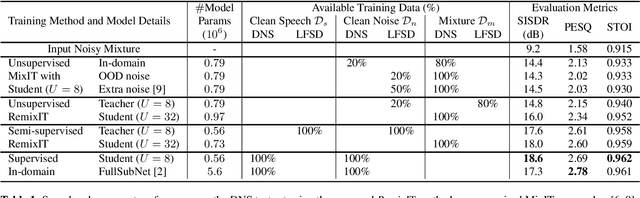
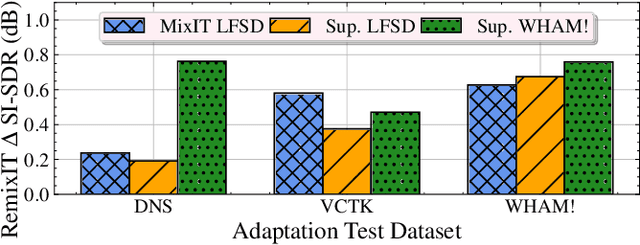
We propose RemixIT, a simple and novel self-supervised training method for speech enhancement. The proposed method is based on a continuously self-training scheme that overcomes limitations from previous studies including assumptions for the in-domain noise distribution and having access to clean target signals. Specifically, a separation teacher model is pre-trained on an out-of-domain dataset and is used to infer estimated target signals for a batch of in-domain mixtures. Next, we bootstrap the mixing process by generating artificial mixtures using permuted estimated clean and noise signals. Finally, the student model is trained using the permuted estimated sources as targets while we periodically update teacher's weights using the latest student model. Our experiments show that RemixIT outperforms several previous state-of-the-art self-supervised methods under multiple speech enhancement tasks. Additionally, RemixIT provides a seamless alternative for semi-supervised and unsupervised domain adaptation for speech enhancement tasks, while being general enough to be applied to any separation task and paired with any separation model.
DPLM: A Deep Perceptual Spatial-Audio Localization Metric
May 29, 2021



Subjective evaluations are critical for assessing the perceptual realism of sounds in audio-synthesis driven technologies like augmented and virtual reality. However, they are challenging to set up, fatiguing for users, and expensive. In this work, we tackle the problem of capturing the perceptual characteristics of localizing sounds. Specifically, we propose a framework for building a general purpose quality metric to assess spatial localization differences between two binaural recordings. We model localization similarity by utilizing activation-level distances from deep networks trained for direction of arrival (DOA) estimation. Our proposed metric (DPLM) outperforms baseline metrics on correlation with subjective ratings on a diverse set of datasets, even without the benefit of any human-labeled training data.
Accelerating Permutation Testing in Voxel-wise Analysis through Subspace Tracking: A new plugin for SnPM
Jul 24, 2017
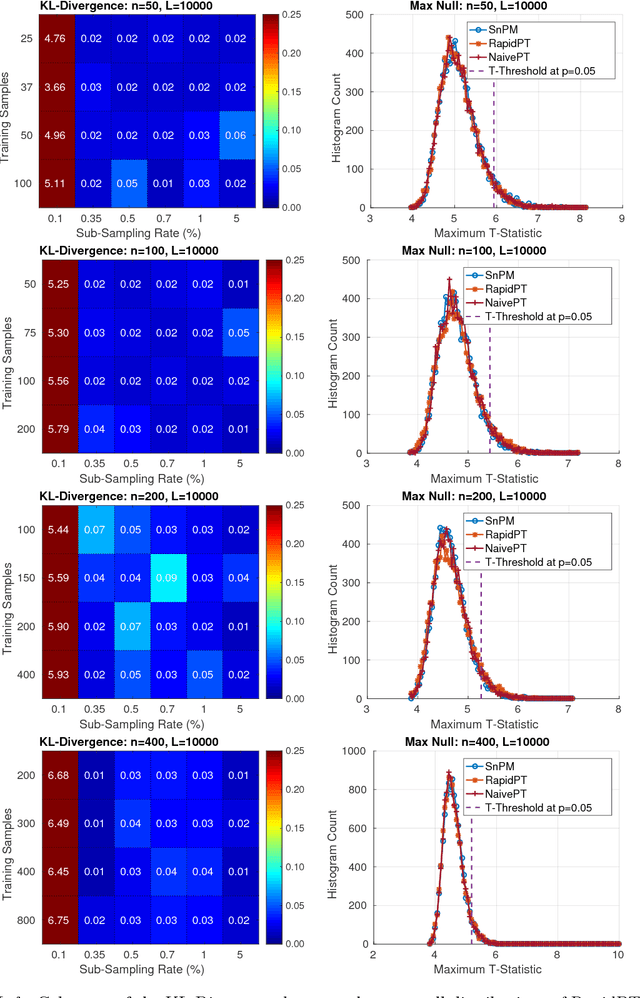

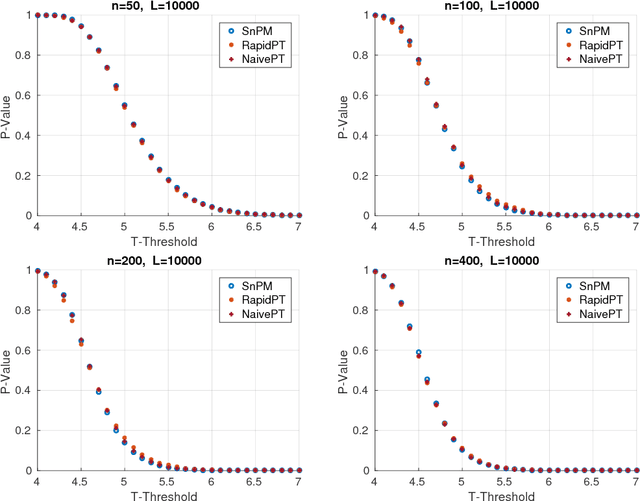
Permutation testing is a non-parametric method for obtaining the max null distribution used to compute corrected $p$-values that provide strong control of false positives. In neuroimaging, however, the computational burden of running such an algorithm can be significant. We find that by viewing the permutation testing procedure as the construction of a very large permutation testing matrix, $T$, one can exploit structural properties derived from the data and the test statistics to reduce the runtime under certain conditions. In particular, we see that $T$ is low-rank plus a low-variance residual. This makes $T$ a good candidate for low-rank matrix completion, where only a very small number of entries of $T$ ($\sim0.35\%$ of all entries in our experiments) have to be computed to obtain a good estimate. Based on this observation, we present RapidPT, an algorithm that efficiently recovers the max null distribution commonly obtained through regular permutation testing in voxel-wise analysis. We present an extensive validation on a synthetic dataset and four varying sized datasets against two baselines: Statistical NonParametric Mapping (SnPM13) and a standard permutation testing implementation (referred as NaivePT). We find that RapidPT achieves its best runtime performance on medium sized datasets ($50 \leq n \leq 200$), with speedups of 1.5x - 38x (vs. SnPM13) and 20x-1000x (vs. NaivePT). For larger datasets ($n \geq 200$) RapidPT outperforms NaivePT (6x - 200x) on all datasets, and provides large speedups over SnPM13 when more than 10000 permutations (2x - 15x) are needed. The implementation is a standalone toolbox and also integrated within SnPM13, able to leverage multi-core architectures when available.
The Incremental Multiresolution Matrix Factorization Algorithm
May 16, 2017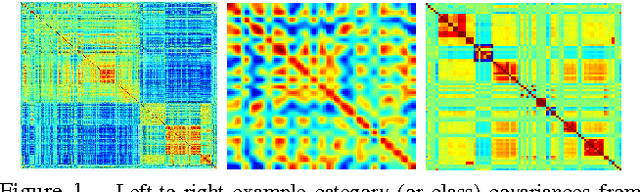


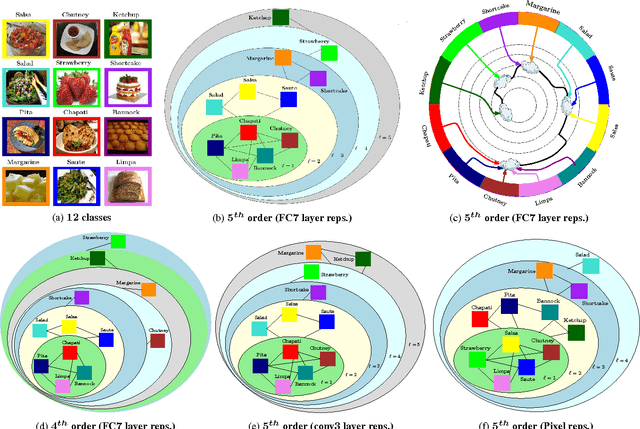
Multiresolution analysis and matrix factorization are foundational tools in computer vision. In this work, we study the interface between these two distinct topics and obtain techniques to uncover hierarchical block structure in symmetric matrices -- an important aspect in the success of many vision problems. Our new algorithm, the incremental multiresolution matrix factorization, uncovers such structure one feature at a time, and hence scales well to large matrices. We describe how this multiscale analysis goes much farther than what a direct global factorization of the data can identify. We evaluate the efficacy of the resulting factorizations for relative leveraging within regression tasks using medical imaging data. We also use the factorization on representations learned by popular deep networks, providing evidence of their ability to infer semantic relationships even when they are not explicitly trained to do so. We show that this algorithm can be used as an exploratory tool to improve the network architecture, and within numerous other settings in vision.
Convergence rates for pretraining and dropout: Guiding learning parameters using network structure
Feb 22, 2017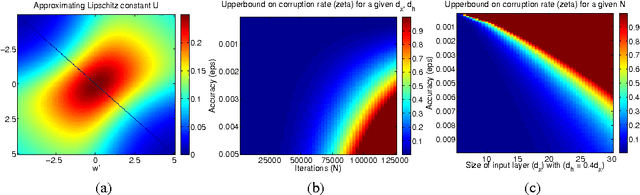



Unsupervised pretraining and dropout have been well studied, especially with respect to regularization and output consistency. However, our understanding about the explicit convergence rates of the parameter estimates, and their dependence on the learning (like denoising and dropout rate) and structural (like depth and layer lengths) aspects of the network is less mature. An interesting question in this context is to ask if the network structure could "guide" the choices of such learning parameters. In this work, we explore these gaps between network structure, the learning mechanisms and their interaction with parameter convergence rates. We present a way to address these issues based on the backpropagation convergence rates for general nonconvex objectives using first-order information. We then incorporate two learning mechanisms into this general framework -- denoising autoencoder and dropout, and subsequently derive the convergence rates of deep networks. Building upon these bounds, we provide insights into the choices of learning parameters and network sizes that achieve certain levels of convergence accuracy. The results derived here support existing empirical observations, and we also conduct a set of experiments to evaluate them.