 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORN: Co-Trained Full-Reference And No-Reference Audio Metrics
Oct 13, 2023


Perceptual evaluation constitutes a crucial aspect of various audio-processing tasks. Full reference (FR) or similarity-based metrics rely on high-quality reference recordings, to which lower-quality or corrupted versions of the recording may be compared for evaluation. In contrast, no-reference (NR) metrics evaluate a recording without relying on a reference. Both the FR and NR approaches exhibit advantages and drawbacks relative to each other. In this paper, we present a novel framework called CORN that amalgamates these dual approaches, concurrently training both FR and NR models together. After training, the models can be applied independently. We evaluate CORN by predicting several common objective metrics and across two different architectures. The NR model trained using CORN has access to a reference recording during training, and thus, as one would expect, it consistently outperforms baseline NR models trained independently. Perhaps even more remarkable is that the CORN FR model also outperforms its baseline counterpart, even though it relies on the same training data and the same model architecture. Thus, a single training regime produces two independently useful models, each outperforming independently trained models.
TorchAudio-Squim: Reference-less Speech Quality and Intelligibility measures in TorchAudio
Apr 04, 2023
Measuring quality and intelligibility of a speech signal is usually a critical step in development of speech processing systems. To enable this, a variety of metrics to measure quality and intelligibility under different assumptions have been developed. Through this paper, we introduce tools and a set of models to estimate such known metrics using deep neural networks. These models are made available in the well-established TorchAudio library, the core audio and speech processing library within the PyTorch deep learning framework. We refer to it as TorchAudio-Squim, TorchAudio-Speech QUality and Intelligibility Measures. More specifically, in the current version of TorchAudio-squim, we establish and release models for estimating PESQ, STOI and SI-SDR among objective metrics and MOS among subjective metrics. We develop a novel approach for objective metric estimation and use a recently developed approach for subjective metric estimation. These models operate in a ``reference-less" manner, that is they do not require the corresponding clean speech as reference for speech assessment. Given the unavailability of clean speech and the effortful process of subjective evaluation in real-world situations, such easy-to-use tools would greatly benefit speech processing research and development.
Audio Similarity is Unreliable as a Proxy for Audio Quality
Jun 27, 2022



Many audio processing tasks require perceptual assessment. However, the time and expense of obtaining ``gold standard'' human judgments limit the availability of such data. Most applications incorporate full reference or other similarity-based metrics (e.g. PESQ) that depend on a clean reference. Researchers have relied on such metrics to evaluate and compare various proposed methods, often concluding that small, measured differences imply one is more effective than another. This paper demonstrates several practical scenarios where similarity metrics fail to agree with human perception, because they: (1) vary with clean references; (2) rely on attributes that humans factor out when considering quality, and (3) are sensitive to imperceptible signal level differences. In those scenarios, we show that no-reference metrics do not suffer from such shortcomings and correlate better with human perception. We conclude therefore that similarity serves as an unreliable proxy for audio quality.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022



Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
Speech Quality Assessment through MOS using Non-Matching References
Jun 24, 2022



Human judgments obtained through Mean Opinion Scores (MOS) are the most reliable way to assess the quality of speech signals. However, several recent attempts to automatically estimate MOS using deep learning approaches lack robustness and generalization capabilities, limiting their use in real-world applications. In this work, we present a novel framework, NORESQA-MOS, for estimating the MOS of a speech signal. Unlike prior works, our approach uses non-matching references as a form of conditioning to ground the MOS estimation by neural networks. We show that NORESQA-MOS provides better generalization and more robust MOS estimation than previous state-of-the-art methods such as DNSMOS and NISQA, even though we use a smaller training set. Moreover, we also show that our generic framework can be combined with other learning methods such as self-supervised learning and can further supplement the benefits from these methods.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022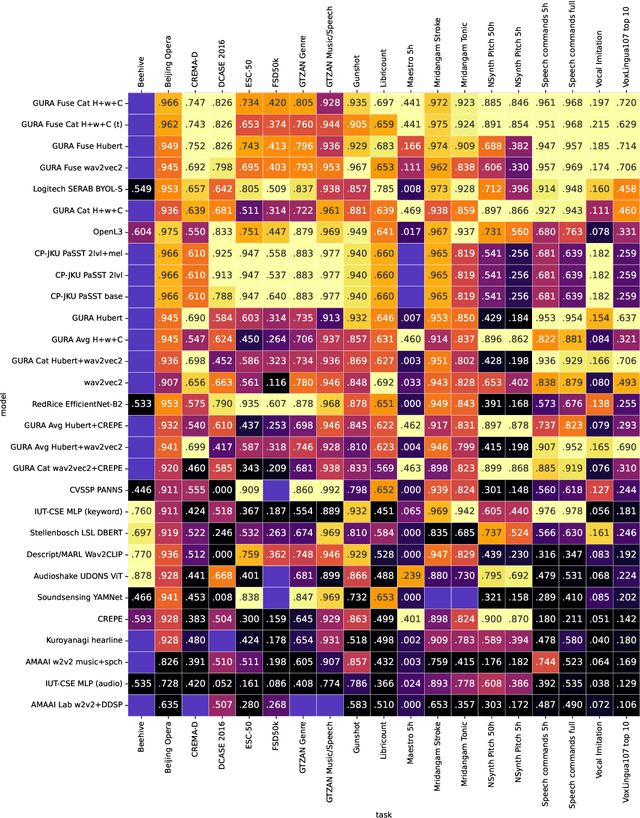
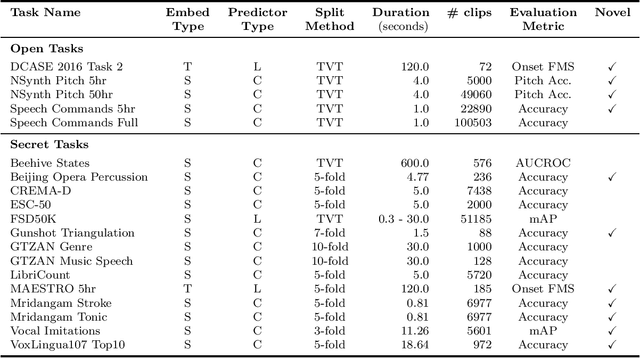

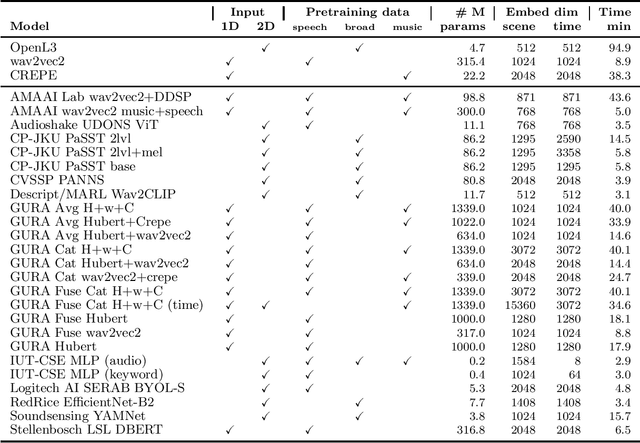
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
NORESQA -- A Framework for Speech Quality Assessment using Non-Matching References
Sep 16, 2021



The perceptual task of speech quality assessment (SQA) is a challenging task for machines to do. Objective SQA methods that rely on the availability of the corresponding clean reference have been the primary go-to approaches for SQA. Clearly, these methods fail in real-world scenarios where the ground truth clean references are not available. In recent years, non-intrusive methods that train neural networks to predict ratings or scores have attracted much attention, but they suffer from several shortcomings such as lack of robustness, reliance on labeled data for training and so on. In this work, we propose a new direction for speech quality assessment. Inspired by human's innate ability to compare and assess the quality of speech signals even when they have non-matching contents, we propose a novel framework that predicts a subjective relative quality score for the given speech signal with respect to any provided reference without using any subjective data. We show that neural networks trained using our framework produce scores that correlate well with subjective mean opinion scores (MOS) and are also competitive to methods such as DNSMOS, which explicitly relies on MOS from humans for training networks. Moreover, our method also provides a natural way to embed quality-related information in neural networks, which we show is helpful for downstream tasks such as speech enhancement.
DPLM: A Deep Perceptual Spatial-Audio Localization Metric
May 29, 2021



Subjective evaluations are critical for assessing the perceptual realism of sounds in audio-synthesis driven technologies like augmented and virtual reality. However, they are challenging to set up, fatiguing for users, and expensive. In this work, we tackle the problem of capturing the perceptual characteristics of localizing sounds. Specifically, we propose a framework for building a general purpose quality metric to assess spatial localization differences between two binaural recordings. We model localization similarity by utilizing activation-level distances from deep networks trained for direction of arrival (DOA) estimation. Our proposed metric (DPLM) outperforms baseline metrics on correlation with subjective ratings on a diverse set of datasets, even without the benefit of any human-labeled training data.
CDPAM: Contrastive learning for perceptual audio similarity
Feb 09, 2021



Many speech processing methods based on deep learning require an automatic and differentiable audio metric for the loss function. The DPAM approach of Manocha et al. learns a full-reference metric trained directly on human judgments, and thus correlates well with human perception. However, it requires a large number of human annotations and does not generalize well outside the range of perturbations on which it was trained. This paper introduces CDPAM, a metric that builds on and advances DPAM. The primary improvement is to combine contrastive learning and multi-dimensional representations to build robust models from limited data. In addition, we collect human judgments on triplet comparisons to improve generalization to a broader range of audio perturbations. CDPAM correlates well with human responses across nine varied datasets. We also show that adding this metric to existing speech synthesis and enhancement methods yields significant improvement, as measured by objective and subjective tests.
Tumor Classification and Segmentation of MR Brain Images
Oct 31, 2017


The diagnosis and segmentation of tumors using any medical diagnostic tool can be challenging due to the varying nature of this pathology. Magnetic Reso- nance Imaging (MRI) is an established diagnostic tool for various diseases and disorders and plays a major role in clinical neuro-diagnosis. Supplementing this technique with automated classification and segmentation tools is gaining importance, to reduce errors and time needed to make a conclusive diagnosis. In this paper a simple three-step algorithm is proposed; (1) identification of patients that present with tumors, (2) automatic selection of abnormal slices of the patients, and (3) segmentation and detection of the tumor. Features were extracted by using discrete wavelet transform on the normalized images and classified by support vector machine (for step (1)) and random forest (for step (2)). The 400 subjects were divided in a 3:1 ratio between training and test with no overlap. This study is novel in terms of use of data, as it employed the entire T2 weighted slices as a single image for classification and a unique combination of contralateral approach with patch thresholding for segmentation, which does not require a training set or a template as is used by most segmentation studies. Using the proposed method, the tumors were segmented accurately with a classification accuracy of 95% with 100% specificity and 90% sensitivity.