 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchAudio-Squim: Reference-less Speech Quality and Intelligibility measures in TorchAudio
Paper and Code
Apr 04, 2023
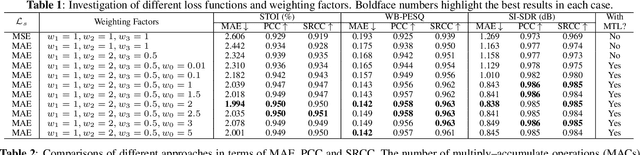
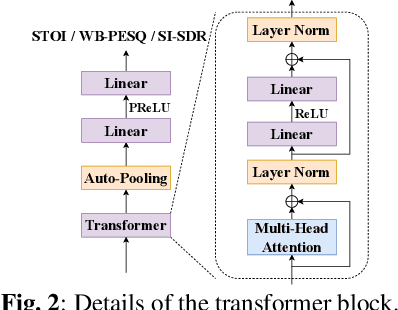
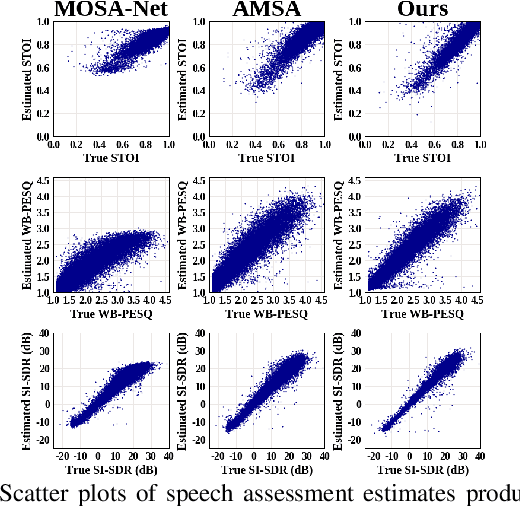
Measuring quality and intelligibility of a speech signal is usually a critical step in development of speech processing systems. To enable this, a variety of metrics to measure quality and intelligibility under different assumptions have been developed. Through this paper, we introduce tools and a set of models to estimate such known metrics using deep neural networks. These models are made available in the well-established TorchAudio library, the core audio and speech processing library within the PyTorch deep learning framework. We refer to it as TorchAudio-Squim, TorchAudio-Speech QUality and Intelligibility Measures. More specifically, in the current version of TorchAudio-squim, we establish and release models for estimating PESQ, STOI and SI-SDR among objective metrics and MOS among subjective metrics. We develop a novel approach for objective metric estimation and use a recently developed approach for subjective metric estimation. These models operate in a ``reference-less" manner, that is they do not require the corresponding clean speech as reference for speech assessment. Given the unavailability of clean speech and the effortful process of subjective evaluation in real-world situations, such easy-to-use tools would greatly benefit speech processing research and development.