 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
Sep 04, 2025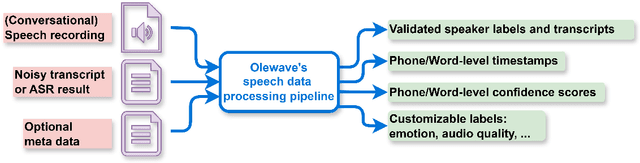
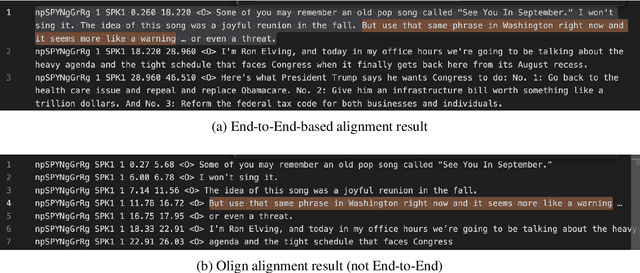
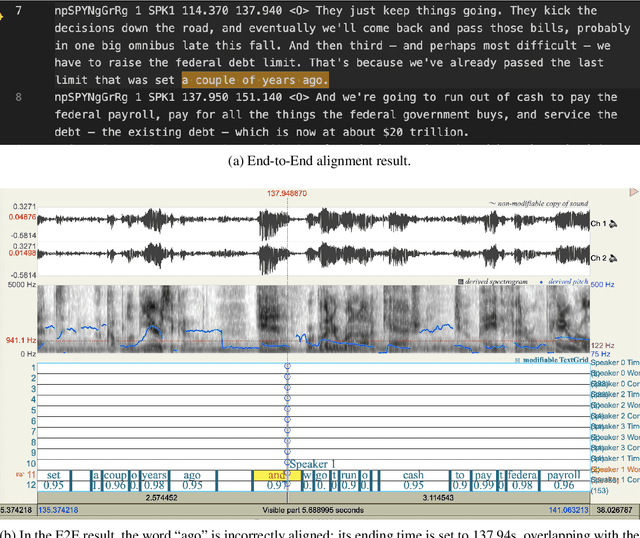
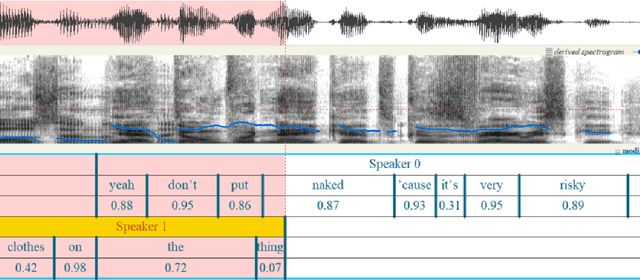
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.
Improving Resource-Efficient Speech Enhancement via Neural Differentiable DSP Vocoder Refinement
Aug 20, 2025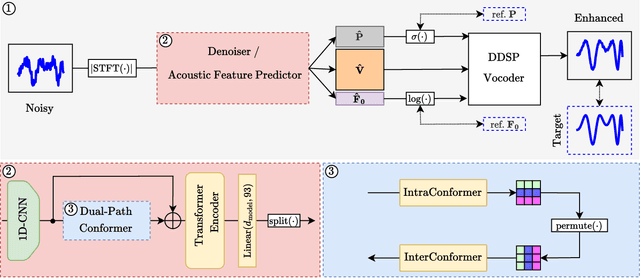
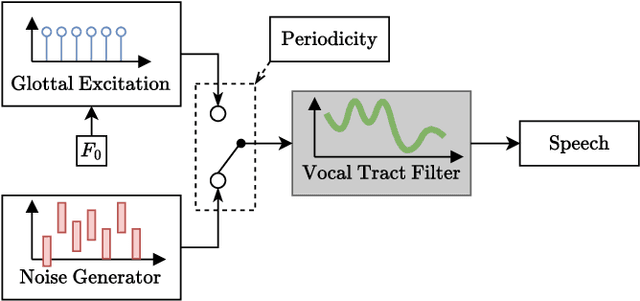
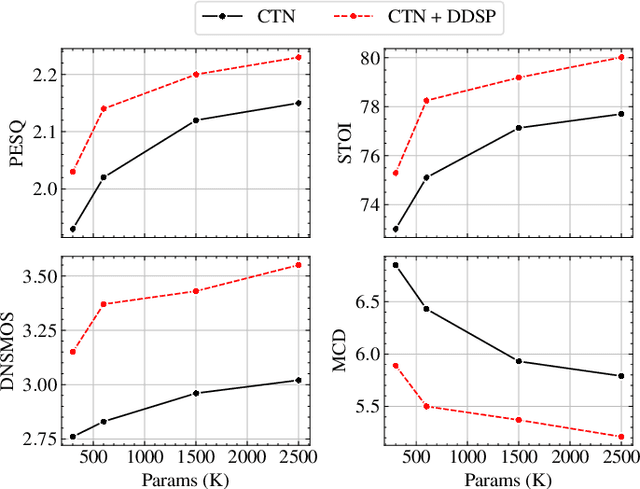
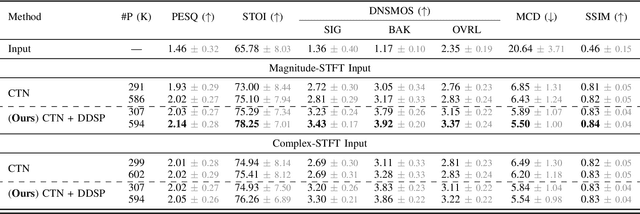
Deploying speech enhancement (SE) systems in wearable devices, such as smart glasses, is challenging due to the limited computational resources on the device. Although deep learning methods have achieved high-quality results, their computational cost limits their feasibility on embedded platforms. This work presents an efficient end-to-end SE framework that leverages a Differentiable Digital Signal Processing (DDSP) vocoder for high-quality speech synthesis. First, a compact neural network predicts enhanced acoustic features from noisy speech: spectral envelope, fundamental frequency (F0), and periodicity. These features are fed into the DDSP vocoder to synthesize the enhanced waveform. The system is trained end-to-end with STFT and adversarial losses, enabling direct optimization at the feature and waveform levels. Experimental results show that our method improves intelligibility and quality by 4% (STOI) and 19% (DNSMOS) over strong baselines without significantly increasing computation, making it well-suited for real-time applications.
Efficient Audiovisual Speech Processing via MUTUD: Multimodal Training and Unimodal Deployment
Jan 30, 2025



Building reliable speech systems often requires combining multiple modalities, like audio and visual cues. While such multimodal solutions frequently lead to improvements in performance and may even be critical in certain cases, they come with several constraints such as increased sensory requirements, computational cost, and modality synchronization, to mention a few. These challenges constrain the direct uses of these multimodal solutions in real-world applications. In this work, we develop approaches where the learning happens with all available modalities but the deployment or inference is done with just one or reduced modalities. To do so, we propose a Multimodal Training and Unimodal Deployment (MUTUD) framework which includes a Temporally Aligned Modality feature Estimation (TAME) module that can estimate information from missing modality using modalities present during inference. This innovative approach facilitates the integration of information across different modalities, enhancing the overall inference process by leveraging the strengths of each modality to compensate for the absence of certain modalities during inference. We apply MUTUD to various audiovisual speech tasks and show that it can reduce the performance gap between the multimodal and corresponding unimodal models to a considerable extent. MUTUD can achieve this while reducing the model size and compute compared to multimodal models, in some cases by almost 80%.
FoVNet: Configurable Field-of-View Speech Enhancement with Low Computation and Distortion for Smart Glasses
Aug 12, 2024


This paper presents a novel multi-channel speech enhancement approach, FoVNet, that enables highly efficient speech enhancement within a configurable field of view (FoV) of a smart-glasses user without needing specific target-talker(s) directions. It advances over prior works by enhancing all speakers within any given FoV, with a hybrid signal processing and deep learning approach designed with high computational efficiency. The neural network component is designed with ultra-low computation (about 50 MMACS). A multi-channel Wiener filter and a post-processing module are further used to improve perceptual quality. We evaluate our algorithm with a microphone array on smart glasses, providing a configurable, efficient solution for augmented hearing on energy-constrained devices. FoVNet excels in both computational efficiency and speech quality across multiple scenarios, making it a promising solution for smart glasses applications.
AV-CrossNet: an Audiovisual Complex Spectral Mapping Network for Speech Separation By Leveraging Narrow- and Cross-Band Modeling
Jun 17, 2024



Adding visual cues to audio-based speech separation can improve separation performance. This paper introduces AV-CrossNet, an audiovisual (AV) system for speech enhancement, target speaker extraction, and multi-talker speaker separation. AV-CrossNet is extended from the CrossNet architecture, which is a recently proposed network that performs complex spectral mapping for speech separation by leveraging global attention and positional encoding. To effectively utilize visual cues, the proposed system incorporates pre-extracted visual embeddings and employs a visual encoder comprising temporal convolutional layers. Audio and visual features are fused in an early fusion layer before feeding to AV-CrossNet blocks. We evaluate AV-CrossNet on multiple datasets, including LRS, VoxCeleb, and COG-MHEAR challenge. Evaluation results demonstrate that AV-CrossNet advances the state-of-the-art performance in all audiovisual tasks, even on untrained and mismatched datasets.
A Closer Look at Wav2Vec2 Embeddings for On-Device Single-Channel Speech Enhancement
Mar 03, 2024



Self-supervised learned models have been found to be very effective for certain speech tasks such as automatic speech recognition, speaker identification, keyword spotting and others. While the features are undeniably useful in speech recognition and associated tasks, their utility in speech enhancement systems is yet to be firmly established, and perhaps not properly understood. In this paper, we investigate the uses of SSL representations for single-channel speech enhancement in challenging conditions and find that they add very little value for the enhancement task. Our constraints are designed around on-device real-time speech enhancement -- model is causal, the compute footprint is small. Additionally, we focus on low SNR conditions where such models struggle to provide good enhancement. In order to systematically examine how SSL representations impact performance of such enhancement models, we propose a variety of techniques to utilize these embeddings which include different forms of knowledge-distillation and pre-training.
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Dec 11, 2023



Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
TorchAudio-Squim: Reference-less Speech Quality and Intelligibility measures in TorchAudio
Apr 04, 2023
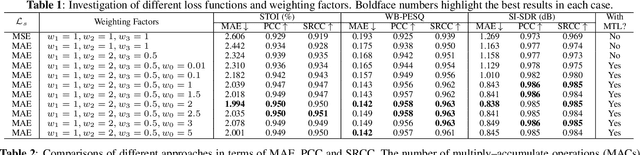
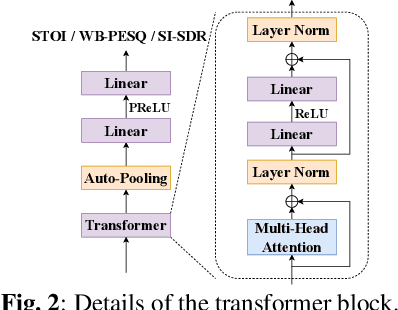
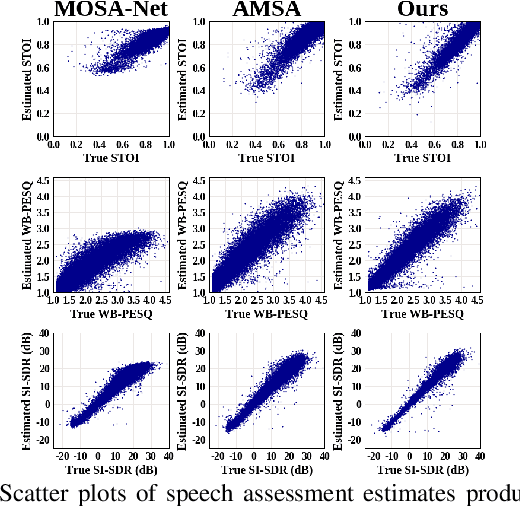
Measuring quality and intelligibility of a speech signal is usually a critical step in development of speech processing systems. To enable this, a variety of metrics to measure quality and intelligibility under different assumptions have been developed. Through this paper, we introduce tools and a set of models to estimate such known metrics using deep neural networks. These models are made available in the well-established TorchAudio library, the core audio and speech processing library within the PyTorch deep learning framework. We refer to it as TorchAudio-Squim, TorchAudio-Speech QUality and Intelligibility Measures. More specifically, in the current version of TorchAudio-squim, we establish and release models for estimating PESQ, STOI and SI-SDR among objective metrics and MOS among subjective metrics. We develop a novel approach for objective metric estimation and use a recently developed approach for subjective metric estimation. These models operate in a ``reference-less" manner, that is they do not require the corresponding clean speech as reference for speech assessment. Given the unavailability of clean speech and the effortful process of subjective evaluation in real-world situations, such easy-to-use tools would greatly benefit speech processing research and development.
Rethinking complex-valued deep neural networks for monaural speech enhancement
Jan 11, 2023



Despite multiple efforts made towards adopting complex-valued deep neural networks (DNNs), it remains an open question whether complex-valued DNNs are generally more effective than real-valued DNNs for monaural speech enhancement. This work is devoted to presenting a critical assessment by systematically examining complex-valued DNNs against their real-valued counterparts. Specifically, we investigate complex-valued DNN atomic units, including linear layers, convolutional layers, long short-term memory (LSTM), and gated linear units. By comparing complex- and real-valued versions of fundamental building blocks in the recently developed gated convolutional recurrent network (GCRN), we show how different mechanisms for basic blocks affect the performance. We also find that the use of complex-valued operations hinders the model capacity when the model size is small. In addition, we examine two recent complex-valued DNNs, i.e. deep complex convolutional recurrent network (DCCRN) and deep complex U-Net (DCUNET). Evaluation results show that both DNNs produce identical performance to their real-valued counterparts while requiring much more computation. Based on these comprehensive comparisons, we conclude that complex-valued DNNs do not provide a performance gain over their real-valued counterparts for monaural speech enhancement, and thus are less desirable due to their higher computational costs.
Leveraging Heteroscedastic Uncertainty in Learning Complex Spectral Mapping for Single-channel Speech Enhancement
Nov 16, 2022



Most speech enhancement (SE) models learn a point estimate, and do not make use of uncertainty estimation in the learning process. In this paper, we show that modeling heteroscedastic uncertainty by minimizing a multivariate Gaussian negative log-likelihood (NLL) improves SE performance at no extra cost. During training, our approach augments a model learning complex spectral mapping with a temporary submodel to predict the covariance of the enhancement error at each time-frequency bin. Due to unrestricted heteroscedastic uncertainty, the covariance introduces an undersampling effect, detrimental to SE performance. To mitigate undersampling, our approach inflates the uncertainty lower bound and weights each loss component with their uncertainty, effectively compensating severely undersampled components with more penalties. Our multivariate setting reveals common covariance assumptions such as scalar and diagonal matrices. By weakening these assumptions, we show that the NLL achieves superior performance compared to popular losses including the mean squared error (MSE), mean absolute error (MAE), and scale-invariant signal-to-distortion ratio (SI-SDR).