 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-CrossNet: an Audiovisual Complex Spectral Mapping Network for Speech Separation By Leveraging Narrow- and Cross-Band Modeling
Jun 17, 2024



Adding visual cues to audio-based speech separation can improve separation performance. This paper introduces AV-CrossNet, an audiovisual (AV) system for speech enhancement, target speaker extraction, and multi-talker speaker separation. AV-CrossNet is extended from the CrossNet architecture, which is a recently proposed network that performs complex spectral mapping for speech separation by leveraging global attention and positional encoding. To effectively utilize visual cues, the proposed system incorporates pre-extracted visual embeddings and employs a visual encoder comprising temporal convolutional layers. Audio and visual features are fused in an early fusion layer before feeding to AV-CrossNet blocks. We evaluate AV-CrossNet on multiple datasets, including LRS, VoxCeleb, and COG-MHEAR challenge. Evaluation results demonstrate that AV-CrossNet advances the state-of-the-art performance in all audiovisual tasks, even on untrained and mismatched datasets.
CrossNet: Leveraging Global, Cross-Band, Narrow-Band, and Positional Encoding for Single- and Multi-Channel Speaker Separation
Mar 06, 2024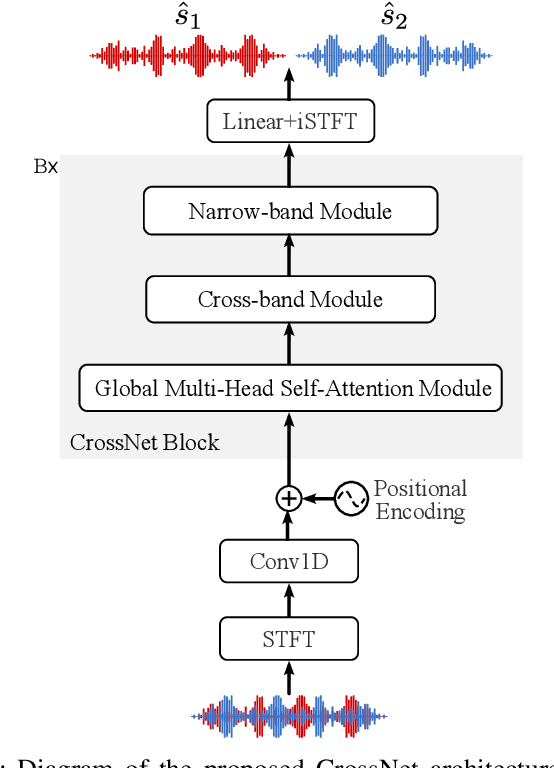
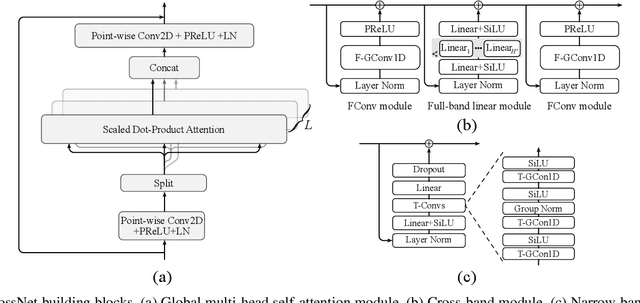
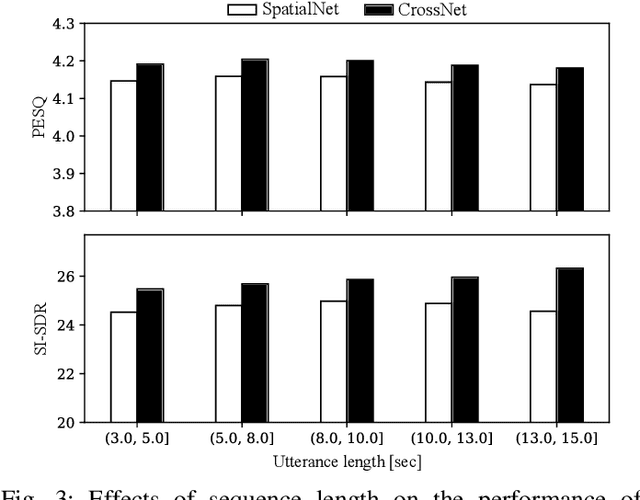
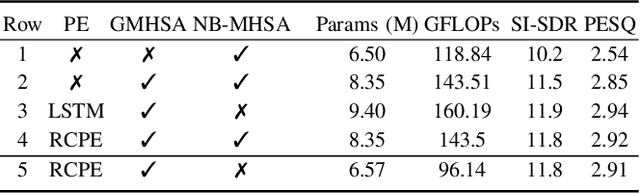
We introduce CrossNet, a complex spectral mapping approach to speaker separation and enhancement in reverberant and noisy conditions. The proposed architecture comprises an encoder layer, a global multi-head self-attention module, a cross-band module, a narrow-band module, and an output layer. CrossNet captures global, cross-band, and narrow-band correlations in the time-frequency domain. To address performance degradation in long utterances, we introduce a random chunk positional encoding. Experimental results on multiple datasets demonstrate the effectiveness and robustness of CrossNet, achieving state-of-the-art performance in tasks including reverberant and noisy-reverberant speaker separation. Furthermore, CrossNet exhibits faster and more stable training in comparison to recent baselines. Additionally, CrossNet's high performance extends to multi-microphone conditions, demonstrating its versatility in various acoustic scenarios.