 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-CrossNet: an Audiovisual Complex Spectral Mapping Network for Speech Separation By Leveraging Narrow- and Cross-Band Modeling
Jun 17, 2024



Adding visual cues to audio-based speech separation can improve separation performance. This paper introduces AV-CrossNet, an audiovisual (AV) system for speech enhancement, target speaker extraction, and multi-talker speaker separation. AV-CrossNet is extended from the CrossNet architecture, which is a recently proposed network that performs complex spectral mapping for speech separation by leveraging global attention and positional encoding. To effectively utilize visual cues, the proposed system incorporates pre-extracted visual embeddings and employs a visual encoder comprising temporal convolutional layers. Audio and visual features are fused in an early fusion layer before feeding to AV-CrossNet blocks. We evaluate AV-CrossNet on multiple datasets, including LRS, VoxCeleb, and COG-MHEAR challenge. Evaluation results demonstrate that AV-CrossNet advances the state-of-the-art performance in all audiovisual tasks, even on untrained and mismatched datasets.
Towards Decoupling Frontend Enhancement and Backend Recognition in Monaural Robust ASR
Mar 11, 2024It has been shown that the intelligibility of noisy speech can be improved by speech enhancement (SE) algorithms. However, monaural SE has not been established as an effective frontend for automatic speech recognition (ASR) in noisy conditions compared to an ASR model trained on noisy speech directly. The divide between SE and ASR impedes the progress of robust ASR systems, especially as SE has made major advances in recent years. This paper focuses on eliminating this divide with an ARN (attentive recurrent network) time-domain and a CrossNet time-frequency domain enhancement models. The proposed systems fully decouple frontend enhancement and backend ASR trained only on clean speech. Results on the WSJ, CHiME-2, LibriSpeech, and CHiME-4 corpora demonstrate that ARN and CrossNet enhanced speech both translate to improved ASR results in noisy and reverberant environments, and generalize well to real acoustic scenarios. The proposed system outperforms the baselines trained on corrupted speech directly. Furthermore, it cuts the previous best word error rate (WER) on CHiME-2 by $28.4\%$ relatively with a $5.57\%$ WER, and achieves $3.32/4.44\%$ WER on single-channel CHiME-4 simulated/real test data without training on CHiME-4.
CrossNet: Leveraging Global, Cross-Band, Narrow-Band, and Positional Encoding for Single- and Multi-Channel Speaker Separation
Mar 06, 2024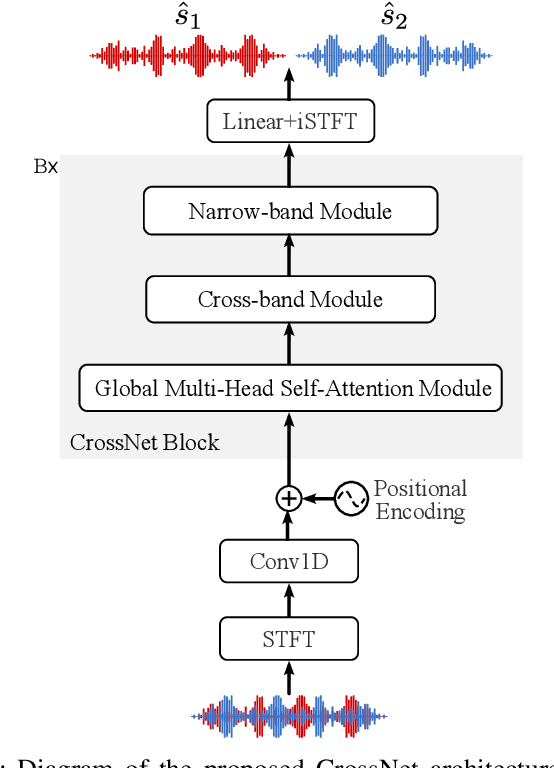
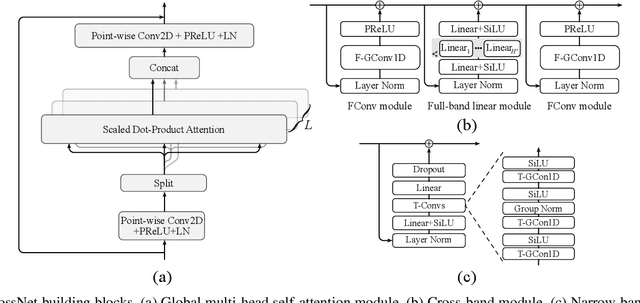
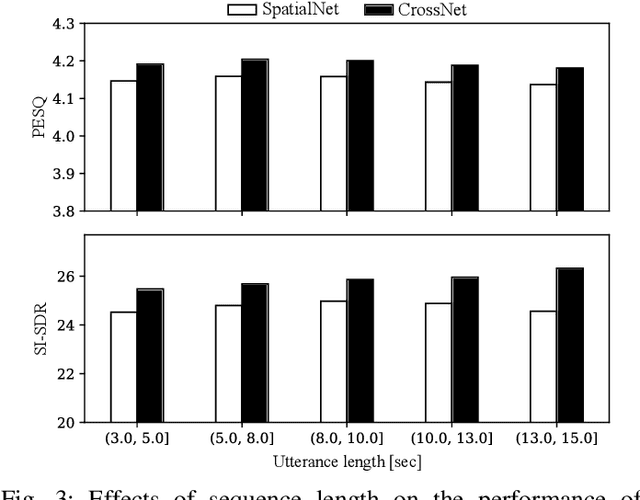
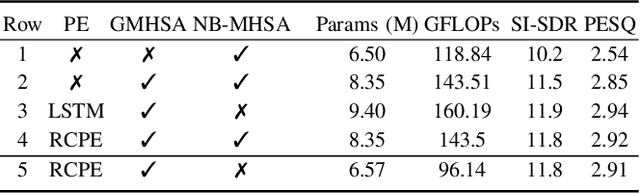
We introduce CrossNet, a complex spectral mapping approach to speaker separation and enhancement in reverberant and noisy conditions. The proposed architecture comprises an encoder layer, a global multi-head self-attention module, a cross-band module, a narrow-band module, and an output layer. CrossNet captures global, cross-band, and narrow-band correlations in the time-frequency domain. To address performance degradation in long utterances, we introduce a random chunk positional encoding. Experimental results on multiple datasets demonstrate the effectiveness and robustness of CrossNet, achieving state-of-the-art performance in tasks including reverberant and noisy-reverberant speaker separation. Furthermore, CrossNet exhibits faster and more stable training in comparison to recent baselines. Additionally, CrossNet's high performance extends to multi-microphone conditions, demonstrating its versatility in various acoustic scenarios.
Combined Generative and Predictive Modeling for Speech Super-resolution
Jan 25, 2024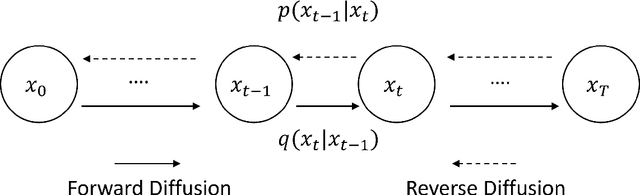
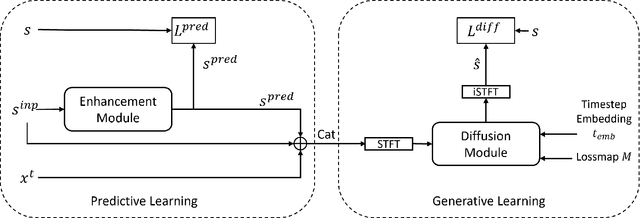
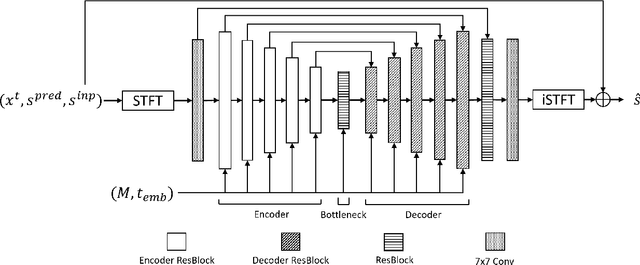
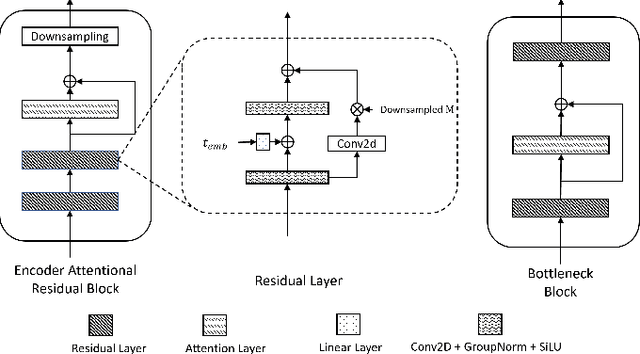
Speech super-resolution (SR) is the task that restores high-resolution speech from low-resolution input. Existing models employ simulated data and constrained experimental settings, which limit generalization to real-world SR. Predictive models are known to perform well in fixed experimental settings, but can introduce artifacts in adverse conditions. On the other hand, generative models learn the distribution of target data and have a better capacity to perform well on unseen conditions. In this study, we propose a novel two-stage approach that combines the strengths of predictive and generative models. Specifically, we employ a diffusion-based model that is conditioned on the output of a predictive model. Our experiments demonstrate that the model significantly outperforms single-stage counterparts and existing strong baselines on benchmark SR datasets. Furthermore, we introduce a repainting technique during the inference of the diffusion process, enabling the proposed model to regenerate high-frequency components even in mismatched conditions. An additional contribution is the collection of and evaluation on real SR recordings, using the same microphone at different native sampling rates. We make this dataset freely accessible, to accelerate progress towards real-world speech super-resolution.
Leveraging Laryngograph Data for Robust Voicing Detection in Speech
Dec 05, 2023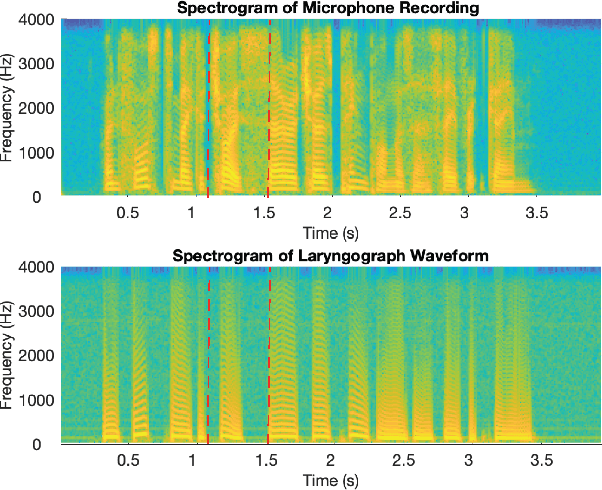
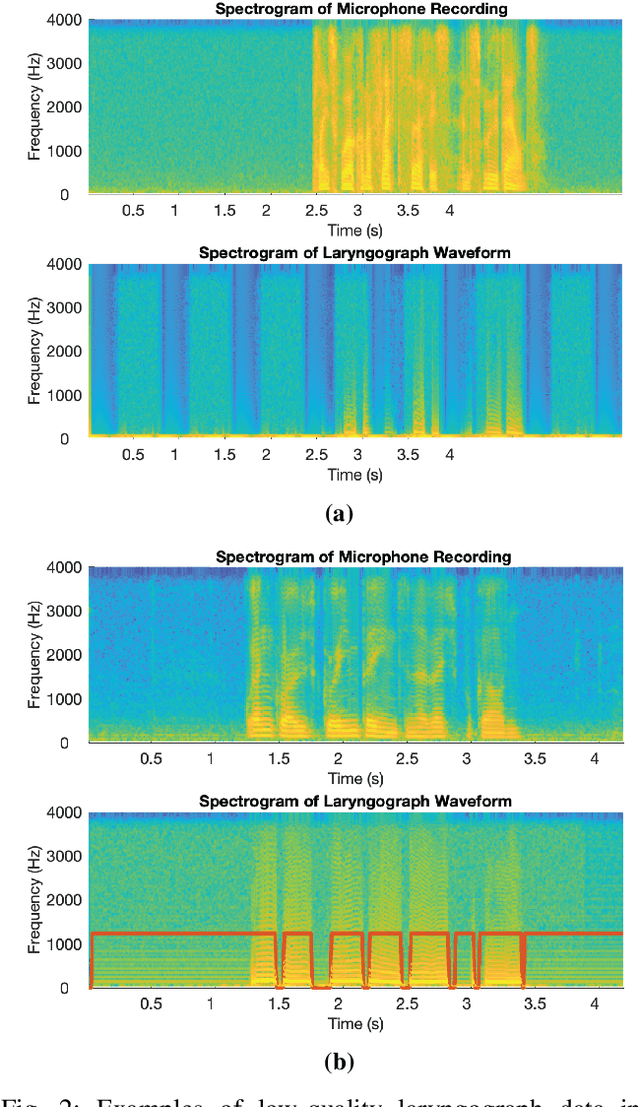
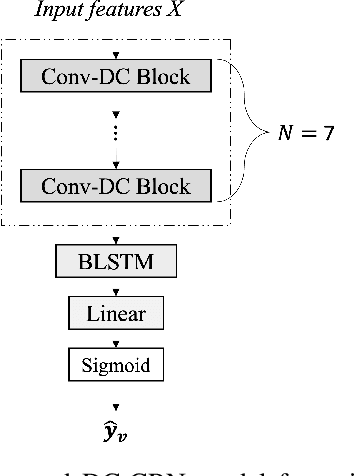
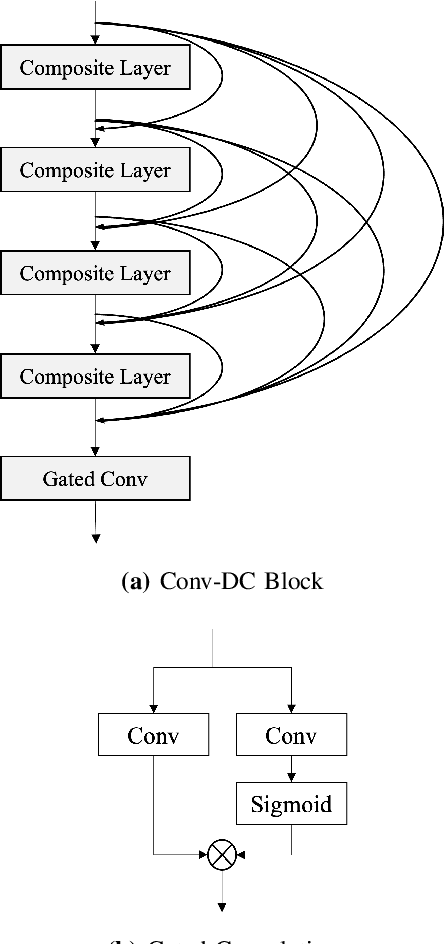
Accurately detecting voiced intervals in speech signals is a critical step in pitch tracking and has numerous applications. While conventional signal processing methods and deep learning algorithms have been proposed for this task, their need to fine-tune threshold parameters for different datasets and limited generalization restrict their utility in real-world applications. To address these challenges, this study proposes a supervised voicing detection model that leverages recorded laryngograph data. The model is based on a densely-connected convolutional recurrent neural network (DC-CRN), and trained on data with reference voicing decisions extracted from laryngograph data sets. Pretraining is also investigated to improve the generalization ability of the model. The proposed model produces robust voicing detection results, outperforming other strong baseline methods, and generalizes well to unseen datasets. The source code of the proposed model with pretraining is provided along with the list of used laryngograph datasets to facilitate further research in this area.
Multi-channel Conversational Speaker Separation via Neural Diarization
Nov 15, 2023



When dealing with overlapped speech, the performance of automatic speech recognition (ASR) systems substantially degrades as they are designed for single-talker speech. To enhance ASR performance in conversational or meeting environments, continuous speaker separation (CSS) is commonly employed. However, CSS requires a short separation window to avoid many speakers inside the window and sequential grouping of discontinuous speech segments. To address these limitations, we introduce a new multi-channel framework called "speaker separation via neural diarization" (SSND) for meeting environments. Our approach utilizes an end-to-end diarization system to identify the speech activity of each individual speaker. By leveraging estimated speaker boundaries, we generate a sequence of embeddings, which in turn facilitate the assignment of speakers to the outputs of a multi-talker separation model. SSND addresses the permutation ambiguity issue of talker-independent speaker separation during the diarization phase through location-based training, rather than during the separation process. This unique approach allows multiple non-overlapped speakers to be assigned to the same output stream, making it possible to efficiently process long segments-a task impossible with CSS. Additionally, SSND is naturally suitable for speaker-attributed ASR. We evaluate our proposed diarization and separation methods on the open LibriCSS dataset, advancing state-of-the-art diarization and ASR results by a large margin.
NeuralKalman: A Learnable Kalman Filter for Acoustic Echo Cancellation
Feb 03, 2023



The Kalman filter is widely used for addressing acoustic echo cancellation (AEC) problems due to their robustness to double-talk and fast convergence. However, the inability to model nonlinearity and the need to tune control parameters cast limitations on such adaptive filtering algorithms. In this paper, we integrate the frequency domain Kalman filter (FDKF) and deep neural networks (DNNs) into a hybrid method, called NeuralKalman, to leverage the advantages of deep learning and adaptive filtering algorithms. Specifically, we employ a DNN to estimate nonlinearly distorted far-end signals, a transition factor, and the nonlinear transition function in the state equation of the FDKF algorithm. Experimental results show that the proposed NeuralKalman improves the performance of FDKF significantly and outperforms strong baseline methods.
Multi-resolution location-based training for multi-channel continuous speech separation
Jan 16, 2023

The performance of automatic speech recognition (ASR) systems severely degrades when multi-talker speech overlap occurs. In meeting environments, speech separation is typically performed to improve the robustness of ASR systems. Recently, location-based training (LBT) was proposed as a new training criterion for multi-channel talker-independent speaker separation. Assuming fixed array geometry, LBT outperforms widely-used permutation-invariant training in fully overlapped utterances and matched reverberant conditions. This paper extends LBT to conversational multi-channel speaker separation. We introduce multi-resolution LBT to estimate the complex spectrograms from low to high time and frequency resolutions. With multi-resolution LBT, convolutional kernels are assigned consistently based on speaker locations in physical space. Evaluation results show that multi-resolution LBT consistently outperforms other competitive methods on the recorded LibriCSS corpus.
Time-Domain Speech Enhancement for Robust Automatic Speech Recognition
Oct 27, 2022



It has been shown that the intelligibility of noisy speech can be improved by speech enhancement algorithms. However, speech enhancement has not been established as an effective front-end for robust automatic speech recognition (ASR) in comparison with an ASR model trained on noisy speech directly. The divide between speech enhancement and ASR impedes the progress of robust ASR systems especially as speech enhancement has made big strides in recent years. In this work, we focus on eliminating such divide with an ARN (attentive recurrent network) based time-domain enhancement model. The proposed system fully decouples speech enhancement and an acoustic model trained only on clean speech. Results on the CHiME-2 corpus show that ARN enhanced speech translates to improved ASR results. The proposed system achieves $6.28\%$ average word error rate, outperforming the previous best by $19.3\%$.
VoiceFixer: A Unified Framework for High-Fidelity Speech Restoration
Apr 17, 2022
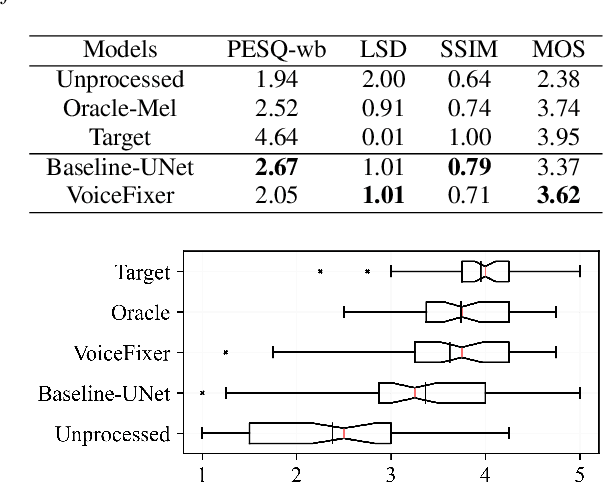
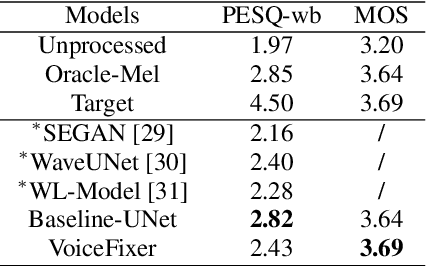
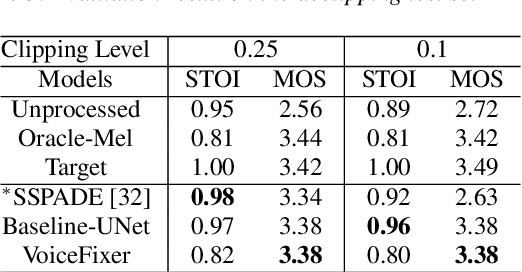
Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on a single type of distortion, such as speech denoising or dereverberation. However, speech signals can be degraded by several different distortions simultaneously in the real world. It is thus important to extend speech restoration models to deal with multiple distortions. In this paper, we introduce VoiceFixer, a unified framework for high-fidelity speech restoration. VoiceFixer restores speech from multiple distortions (e.g., noise, reverberation, and clipping) and can expand degraded speech (e.g., noisy speech) with a low bandwidth to 44.1 kHz full-bandwidth high-fidelity speech. We design VoiceFixer based on (1) an analysis stage that predicts intermediate-level features from the degraded speech, and (2) a synthesis stage that generates waveform using a neural vocoder. Both objective and subjective evaluations show that VoiceFixer is effective on severely degraded speech, such as real-world historical speech recordings. Samples of VoiceFixer are available at https://haoheliu.github.io/voicefixer.