 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^2$Voice: Style-Aware Autoregressive Modeling with Enhanced Conditioning for Singing Style Conversion
Jan 20, 2026We present S$^2$Voice, the winning system of the Singing Voice Conversion Challenge (SVCC) 2025 for both the in-domain and zero-shot singing style conversion tracks. Built on the strong two-stage Vevo baseline, S$^2$Voice advances style control and robustness through several contributions. First, we integrate style embeddings into the autoregressive large language model (AR LLM) via a FiLM-style layer-norm conditioning and a style-aware cross-attention for enhanced fine-grained style modeling. Second, we introduce a global speaker embedding into the flow-matching transformer to improve timbre similarity. Third, we curate a large, high-quality singing corpus via an automated pipeline for web harvesting, vocal separation, and transcript refinement. Finally, we employ a multi-stage training strategy combining supervised fine-tuning (SFT) and direct preference optimization (DPO). Subjective listening tests confirm our system's superior performance: leading in style similarity and singer similarity for Task 1, and across naturalness, style similarity, and singer similarity for Task 2. Ablation studies demonstrate the effectiveness of our contributions in enhancing style fidelity, timbre preservation, and generalization. Audio samples are available~\footnote{https://honee-w.github.io/SVC-Challenge-Demo/}.
UniFlow: Unifying Speech Front-End Tasks via Continuous Generative Modeling
Aug 11, 2025Generative modeling has recently achieved remarkable success across image, video, and audio domains, demonstrating powerful capabilities for unified representation learning. Yet speech front-end tasks such as speech enhancement (SE), target speaker extraction (TSE), acoustic echo cancellation (AEC), and language-queried source separation (LASS) remain largely tackled by disparate, task-specific solutions. This fragmentation leads to redundant engineering effort, inconsistent performance, and limited extensibility. To address this gap, we introduce UniFlow, a unified framework that employs continuous generative modeling to tackle diverse speech front-end tasks in a shared latent space. Specifically, UniFlow utilizes a waveform variational autoencoder (VAE) to learn a compact latent representation of raw audio, coupled with a Diffusion Transformer (DiT) that predicts latent updates. To differentiate the speech processing task during the training, learnable condition embeddings indexed by a task ID are employed to enable maximal parameter sharing while preserving task-specific adaptability. To balance model performance and computational efficiency, we investigate and compare three generative objectives: denoising diffusion, flow matching, and mean flow within the latent domain. We validate UniFlow on multiple public benchmarks, demonstrating consistent gains over state-of-the-art baselines. UniFlow's unified latent formulation and conditional design make it readily extensible to new tasks, providing an integrated foundation for building and scaling generative speech processing pipelines. To foster future research, we will open-source our codebase.
RaD-Net 2: A causal two-stage repairing and denoising speech enhancement network with knowledge distillation and complex axial self-attention
Jun 11, 2024



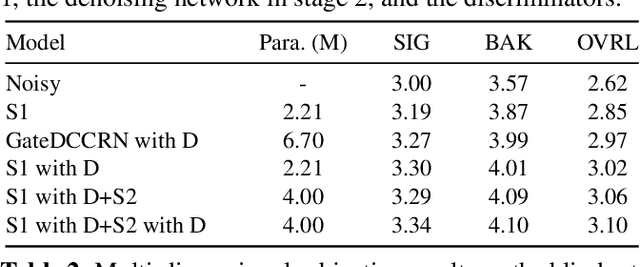
In real-time speech communication systems, speech signals are often degraded by multiple distortions. Recently, a two-stage Repair-and-Denoising network (RaD-Net) was proposed with superior speech quality improvement in the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. However, failure to use future information and constraint receptive field of convolution layers limit the system's performance. To mitigate these problems, we extend RaD-Net to its upgraded version, RaD-Net 2. Specifically, a causality-based knowledge distillation is introduced in the first stage to use future information in a causal way. We use the non-causal repairing network as the teacher to improve the performance of the causal repairing network. In addition, in the second stage, complex axial self-attention is applied in the denoising network's complex feature encoder/decoder. Experimental results on the ICASSP 2024 SSI Challenge blind test set show that RaD-Net 2 brings 0.10 OVRL DNSMOS improvement compared to RaD-Net.
BS-PLCNet 2: Two-stage Band-split Packet Loss Concealment Network with Intra-model Knowledge Distillation
Jun 10, 2024



Audio packet loss is an inevitable problem in real-time speech communication. A band-split packet loss concealment network (BS-PLCNet) targeting full-band signals was recently proposed. Although it performs superiorly in the ICASSP 2024 PLC Challenge, BS-PLCNet is a large model with high computational complexity of 8.95G FLOPS. This paper presents its updated version, BS-PLCNet 2, to reduce computational complexity and improve performance further. Specifically, to compensate for the missing future information, in the wide-band module, we design a dual-path encoder structure (with non-causal and causal path) and leverage an intra-model knowledge distillation strategy to distill the future information from the non-causal teacher to the casual student. Moreover, we introduce a lightweight post-processing module after packet loss restoration to recover speech distortions and remove residual noise in the audio signal. With only 40% of original parameters in BS-PLCNet, BS-PLCNet 2 brings 0.18 PLCMOS improvement on the ICASSP 2024 PLC challenge blind set, achieving state-of-the-art performance on this dataset.
RaD-Net: A Repairing and Denoising Network for Speech Signal Improvement
Jan 09, 2024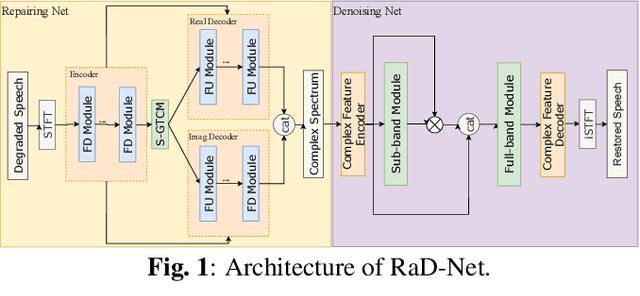
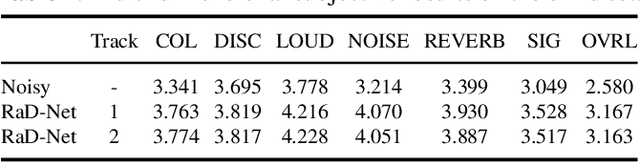
This paper introduces our repairing and denoising network (RaD-Net) for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. We extend our previous framework based on a two-stage network and propose an upgraded model. Specifically, we replace the repairing network with COM-Net from TEA-PSE. In addition, multi-resolution discriminators and multi-band discriminators are adopted in the training stage. Finally, we use a three-step training strategy to optimize our model. We submit two models with different sets of parameters to meet the RTF requirement of the two tracks. According to the official results, the proposed systems rank 2nd in track 1 and 3rd in track 2.
BS-PLCNet: Band-split Packet Loss Concealment Network with Multi-task Learning Framework and Multi-discriminators
Jan 08, 2024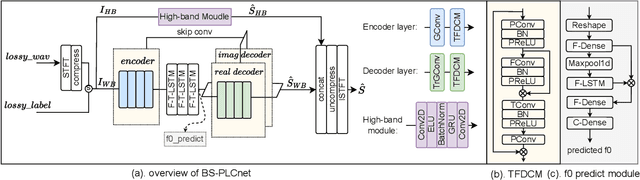

Packet loss is a common and unavoidable problem in voice over internet phone (VoIP) systems. To deal with the problem, we propose a band-split packet loss concealment network (BS-PLCNet). Specifically, we split the full-band signal into wide-band (0-8kHz) and high-band (8-24kHz). The wide-band signals are processed by a gated convolutional recurrent network (GCRN), while the high-band counterpart is processed by a simple GRU network. To ensure high speech quality and automatic speech recognition (ASR) compatibility, multi-task learning (MTL) framework including fundamental frequency (f0) prediction, linguistic awareness, and multi-discriminators are used. The proposed approach tied for 1st place in the ICASSP 2024 PLC Challenge.
Language-universal phonetic encoder for low-resource speech recognition
May 19, 2023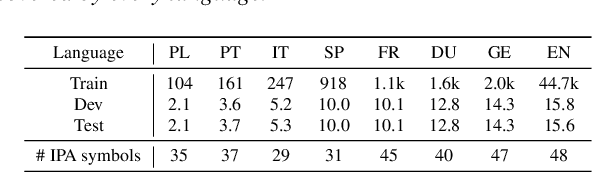
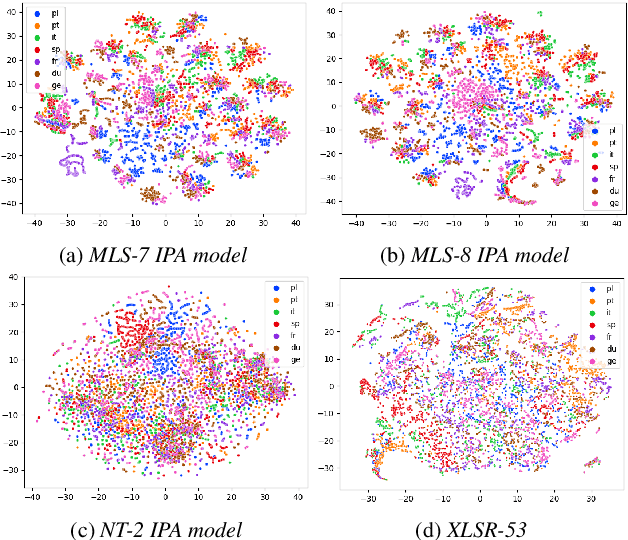

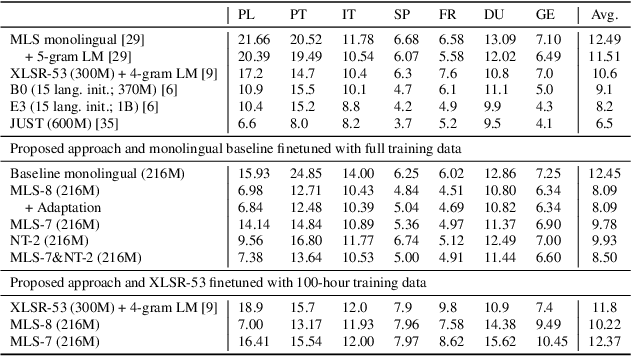
Multilingual training is effective in improving low-resource ASR, which may partially be explained by phonetic representation sharing between languages. In end-to-end (E2E) ASR systems, graphemes are often used as basic modeling units, however graphemes may not be ideal for multilingual phonetic sharing. In this paper, we leverage International Phonetic Alphabet (IPA) based language-universal phonetic model to improve low-resource ASR performances, for the first time within the attention encoder-decoder architecture. We propose an adaptation method on the phonetic IPA model to further improve the proposed approach on extreme low-resource languages. Experiments carried out on the open-source MLS corpus and our internal databases show our approach outperforms baseline monolingual models and most state-of-the-art works. Our main approach and adaptation are effective on extremely low-resource languages, even within domain- and language-mismatched scenarios.
Language-Universal Phonetic Representation in Multilingual Speech Pretraining for Low-Resource Speech Recognition
May 19, 2023

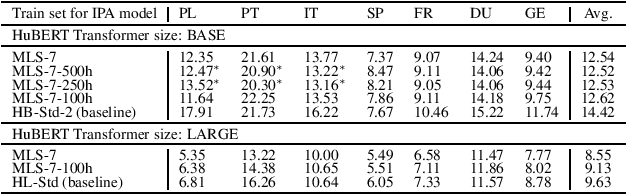
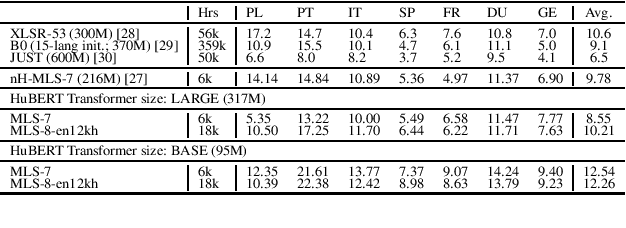
We improve low-resource ASR by integrating the ideas of multilingual training and self-supervised learning. Concretely, we leverage an International Phonetic Alphabet (IPA) multilingual model to create frame-level pseudo labels for unlabeled speech, and use these pseudo labels to guide hidden-unit BERT (HuBERT) based speech pretraining in a phonetically-informed manner. The experiments on the Multilingual Speech (MLS) Corpus show that the proposed approach consistently outperforms the standard HuBERT on all the target languages. Moreover, on 3 of the 4 languages, comparing to the standard HuBERT, the approach performs better, meanwhile is able to save supervised training data by 1.5k hours (75%) at most. Our approach outperforms most of the state of the arts, with much less pretraining data in terms of hours and language diversity. Compared to XLSR-53 and a retraining based multilingual method, our approach performs better with full and limited finetuning data scenarios.
Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Dec 30, 2022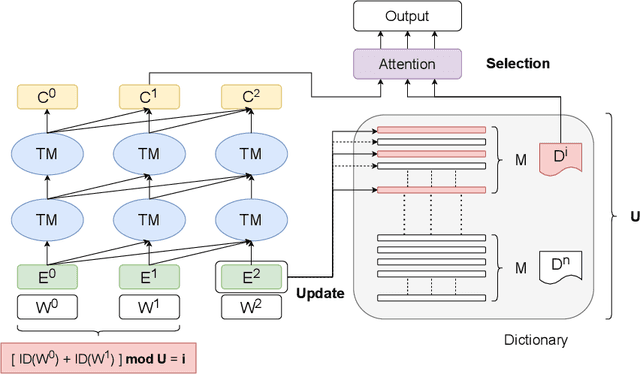
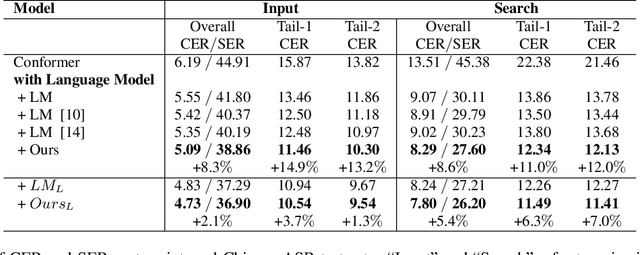
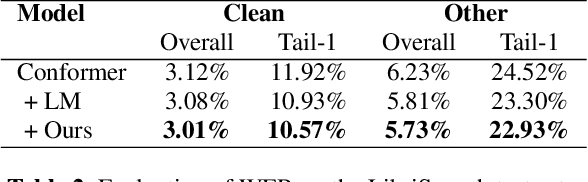
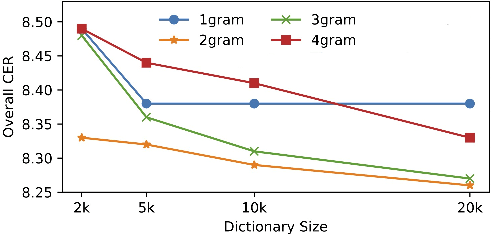
Recent studies have shown that using an external Language Model (LM) benefits the end-to-end Automatic Speech Recognition (ASR). However, predicting tokens that appear less frequently in the training set is still quite challenging. The long-tail prediction problems have been widely studied in many applications, but only been addressed by a few studies for ASR and LMs. In this paper, we propose a new memory augmented lookup dictionary based Transformer architecture for LM. The newly introduced lookup dictionary incorporates rich contextual information in training set, which is vital to correctly predict long-tail tokens. With intensive experiments on Chinese and English data sets, our proposed method is proved to outperform the baseline Transformer LM by a great margin on both word/character error rate and tail tokens error rate. This is achieved without impact on the decoding efficiency. Overall, we demonstrate the effectiveness of our proposed method in boosting the ASR decoding performance, especially for long-tail tokens.
VoiceFixer: A Unified Framework for High-Fidelity Speech Restoration
Apr 17, 2022
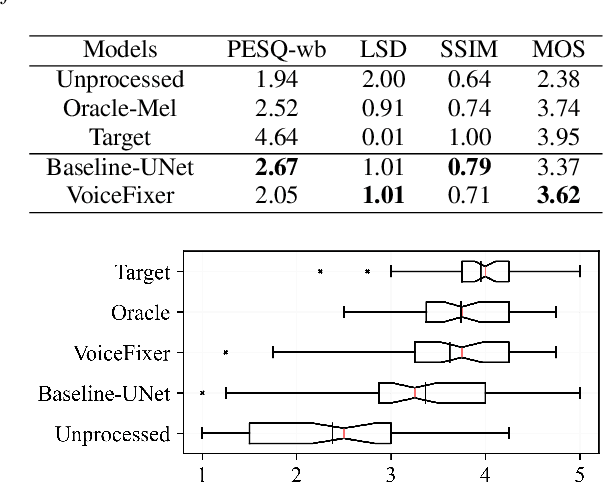
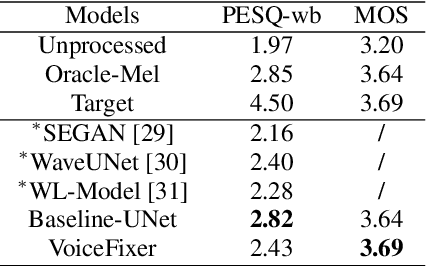
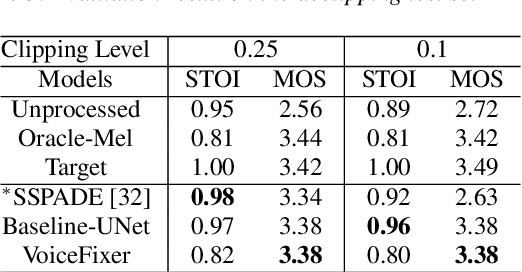
Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on a single type of distortion, such as speech denoising or dereverberation. However, speech signals can be degraded by several different distortions simultaneously in the real world. It is thus important to extend speech restoration models to deal with multiple distortions. In this paper, we introduce VoiceFixer, a unified framework for high-fidelity speech restoration. VoiceFixer restores speech from multiple distortions (e.g., noise, reverberation, and clipping) and can expand degraded speech (e.g., noisy speech) with a low bandwidth to 44.1 kHz full-bandwidth high-fidelity speech. We design VoiceFixer based on (1) an analysis stage that predicts intermediate-level features from the degraded speech, and (2) a synthesis stage that generates waveform using a neural vocoder. Both objective and subjective evaluations show that VoiceFixer is effective on severely degraded speech, such as real-world historical speech recordings. Samples of VoiceFixer are available at https://haoheliu.github.io/voicefixer.