 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-universal phonetic encoder for low-resource speech recognition
Paper and Code
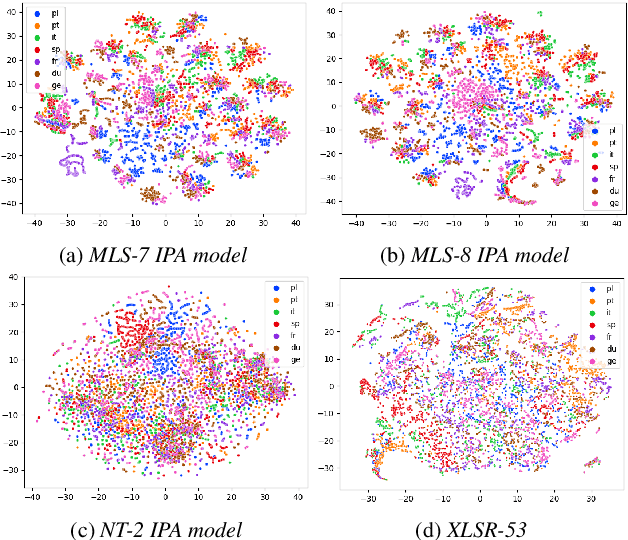

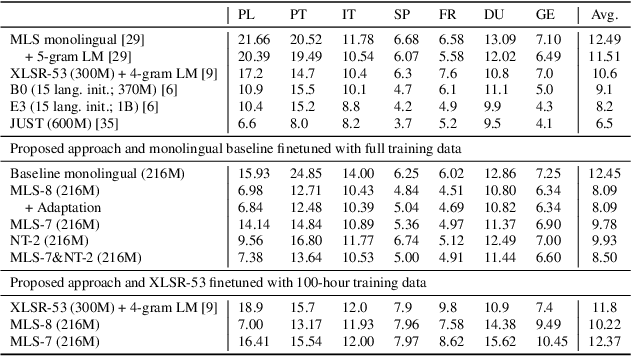
Multilingual training is effective in improving low-resource ASR, which may partially be explained by phonetic representation sharing between languages. In end-to-end (E2E) ASR systems, graphemes are often used as basic modeling units, however graphemes may not be ideal for multilingual phonetic sharing. In this paper, we leverage International Phonetic Alphabet (IPA) based language-universal phonetic model to improve low-resource ASR performances, for the first time within the attention encoder-decoder architecture. We propose an adaptation method on the phonetic IPA model to further improve the proposed approach on extreme low-resource languages. Experiments carried out on the open-source MLS corpus and our internal databases show our approach outperforms baseline monolingual models and most state-of-the-art works. Our main approach and adaptation are effective on extremely low-resource languages, even within domain- and language-mismatched scenarios.