 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
Nov 11, 2025Speech-to-Speech (S2S) models have shown promising dialogue capabilities, but their ability to handle paralinguistic cues--such as emotion, tone, and speaker attributes--and to respond appropriately in both content and style remains underexplored. Progress is further hindered by the scarcity of high-quality and expressive demonstrations. To address this, we introduce a novel reinforcement learning (RL) framework for paralinguistic-aware S2S, ParaS2S, which evaluates and optimizes both content and speaking style directly at the waveform level. We first construct ParaS2SBench, a benchmark comprehensively evaluates S2S models' output for content and style appropriateness from diverse and challenging input queries. It scores the fitness of input-output pairs and aligns well with human judgments, serving as an automatic judge for model outputs. With this scalable scoring feedback, we enable the model to explore and learn from diverse unlabeled speech via Group Relative Policy Optimization (GRPO). Experiments show that existing S2S models fail to respond appropriately to paralinguistic attributes, performing no better than pipeline-based baselines. Our RL approach achieves a 11% relative improvement in response content and style's appropriateness on ParaS2SBench over supervised fine-tuning (SFT), surpassing all prior models while requiring substantially fewer warm-up annotations than pure SFT.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
VoiceShop: A Unified Speech-to-Speech Framework for Identity-Preserving Zero-Shot Voice Editing
Apr 11, 2024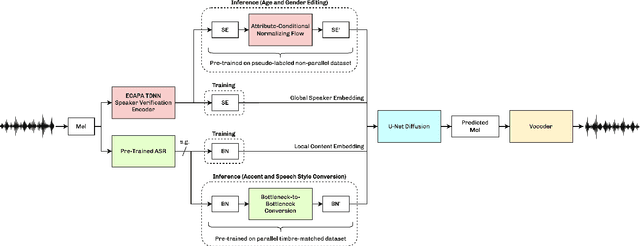

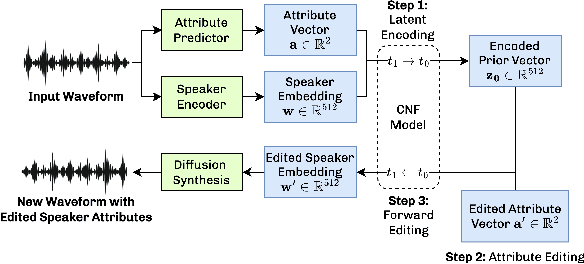
We present VoiceShop, a novel speech-to-speech framework that can modify multiple attributes of speech, such as age, gender, accent, and speech style, in a single forward pass while preserving the input speaker's timbre. Previous works have been constrained to specialized models that can only edit these attributes individually and suffer from the following pitfalls: the magnitude of the conversion effect is weak, there is no zero-shot capability for out-of-distribution speakers, or the synthesized outputs exhibit undesirable timbre leakage. Our work proposes solutions for each of these issues in a simple modular framework based on a conditional diffusion backbone model with optional normalizing flow-based and sequence-to-sequence speaker attribute-editing modules, whose components can be combined or removed during inference to meet a wide array of tasks without additional model finetuning. Audio samples are available at \url{https://voiceshopai.github.io}.
Efficient Neural Music Generation
May 25, 2023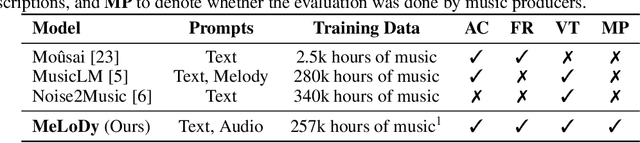
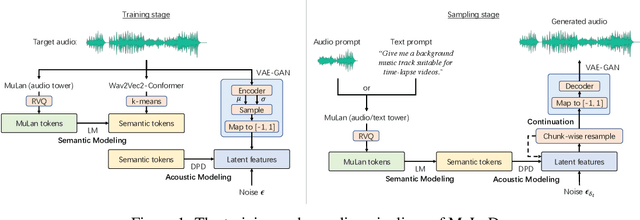
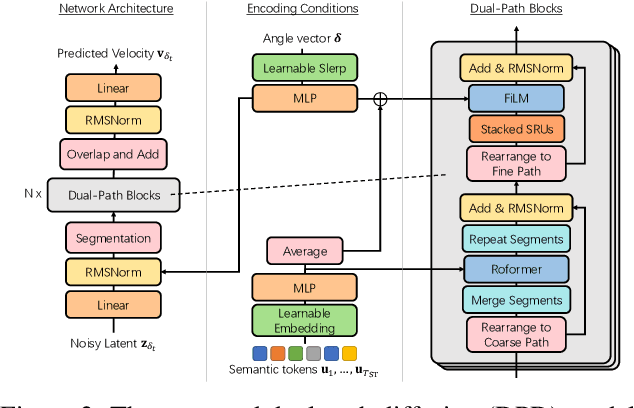

Recent progress in music generation has been remarkably advanced by the state-of-the-art MusicLM, which comprises a hierarchy of three LMs, respectively, for semantic, coarse acoustic, and fine acoustic modelings. Yet, sampling with the MusicLM requires processing through these LMs one by one to obtain the fine-grained acoustic tokens, making it computationally expensive and prohibitive for a real-time generation. Efficient music generation with a quality on par with MusicLM remains a significant challenge. In this paper, we present MeLoDy (M for music; L for LM; D for diffusion), an LM-guided diffusion model that generates music audios of state-of-the-art quality meanwhile reducing 95.7% or 99.6% forward passes in MusicLM, respectively, for sampling 10s or 30s music. MeLoDy inherits the highest-level LM from MusicLM for semantic modeling, and applies a novel dual-path diffusion (DPD) model and an audio VAE-GAN to efficiently decode the conditioning semantic tokens into waveform. DPD is proposed to simultaneously model the coarse and fine acoustics by incorporating the semantic information into segments of latents effectively via cross-attention at each denoising step. Our experimental results suggest the superiority of MeLoDy, not only in its practical advantages on sampling speed and infinitely continuable generation, but also in its state-of-the-art musicality, audio quality, and text correlation. Our samples are available at https://Efficient-MeLoDy.github.io/.
Language-universal phonetic encoder for low-resource speech recognition
May 19, 2023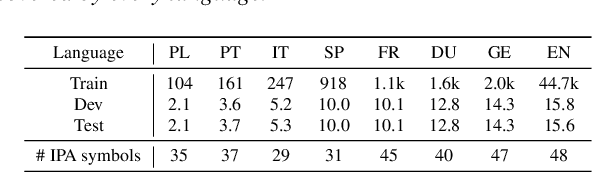
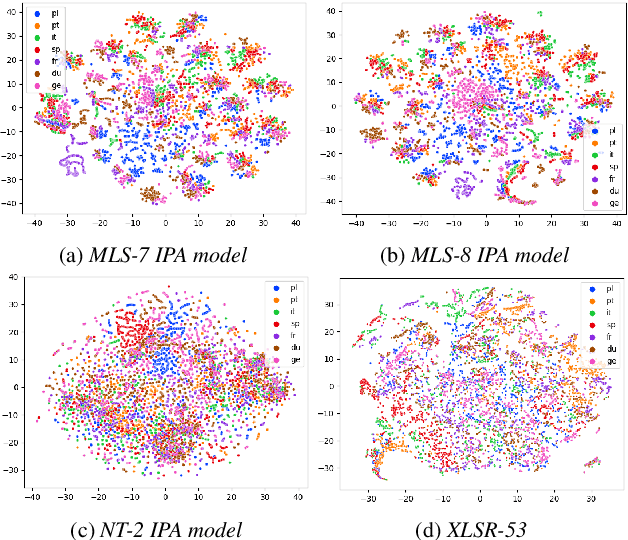

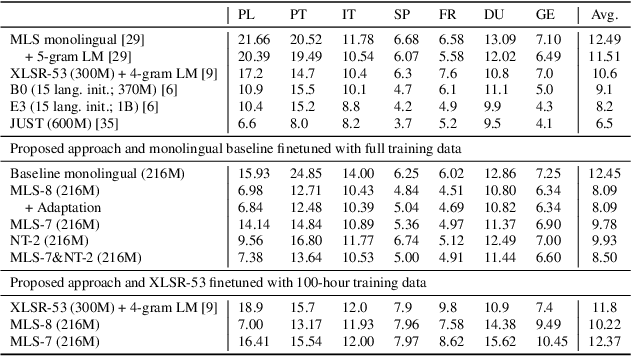
Multilingual training is effective in improving low-resource ASR, which may partially be explained by phonetic representation sharing between languages. In end-to-end (E2E) ASR systems, graphemes are often used as basic modeling units, however graphemes may not be ideal for multilingual phonetic sharing. In this paper, we leverage International Phonetic Alphabet (IPA) based language-universal phonetic model to improve low-resource ASR performances, for the first time within the attention encoder-decoder architecture. We propose an adaptation method on the phonetic IPA model to further improve the proposed approach on extreme low-resource languages. Experiments carried out on the open-source MLS corpus and our internal databases show our approach outperforms baseline monolingual models and most state-of-the-art works. Our main approach and adaptation are effective on extremely low-resource languages, even within domain- and language-mismatched scenarios.
Language-Universal Phonetic Representation in Multilingual Speech Pretraining for Low-Resource Speech Recognition
May 19, 2023

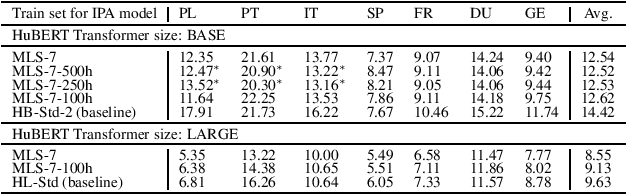
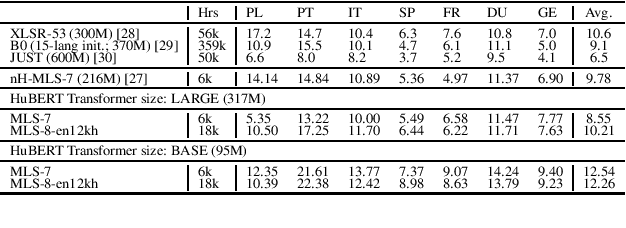
We improve low-resource ASR by integrating the ideas of multilingual training and self-supervised learning. Concretely, we leverage an International Phonetic Alphabet (IPA) multilingual model to create frame-level pseudo labels for unlabeled speech, and use these pseudo labels to guide hidden-unit BERT (HuBERT) based speech pretraining in a phonetically-informed manner. The experiments on the Multilingual Speech (MLS) Corpus show that the proposed approach consistently outperforms the standard HuBERT on all the target languages. Moreover, on 3 of the 4 languages, comparing to the standard HuBERT, the approach performs better, meanwhile is able to save supervised training data by 1.5k hours (75%) at most. Our approach outperforms most of the state of the arts, with much less pretraining data in terms of hours and language diversity. Compared to XLSR-53 and a retraining based multilingual method, our approach performs better with full and limited finetuning data scenarios.
Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Dec 30, 2022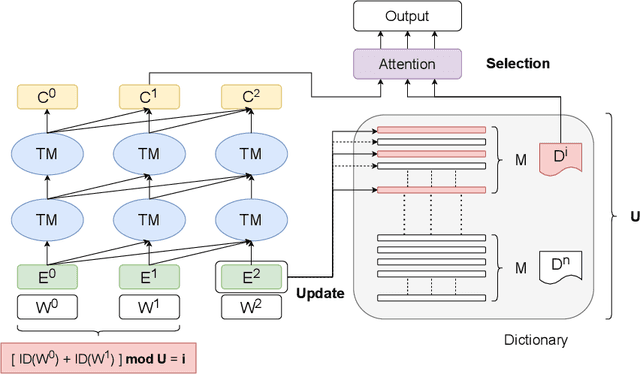
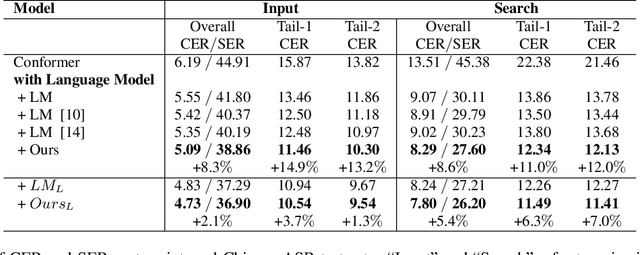
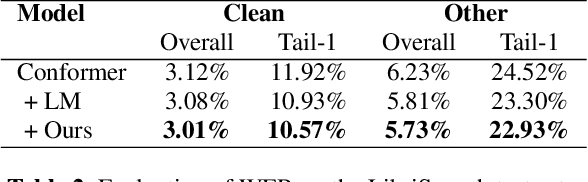
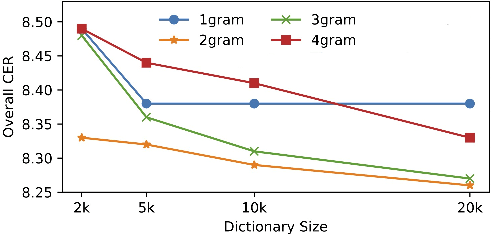
Recent studies have shown that using an external Language Model (LM) benefits the end-to-end Automatic Speech Recognition (ASR). However, predicting tokens that appear less frequently in the training set is still quite challenging. The long-tail prediction problems have been widely studied in many applications, but only been addressed by a few studies for ASR and LMs. In this paper, we propose a new memory augmented lookup dictionary based Transformer architecture for LM. The newly introduced lookup dictionary incorporates rich contextual information in training set, which is vital to correctly predict long-tail tokens. With intensive experiments on Chinese and English data sets, our proposed method is proved to outperform the baseline Transformer LM by a great margin on both word/character error rate and tail tokens error rate. This is achieved without impact on the decoding efficiency. Overall, we demonstrate the effectiveness of our proposed method in boosting the ASR decoding performance, especially for long-tail tokens.
Streaming Voice Conversion Via Intermediate Bottleneck Features And Non-streaming Teacher Guidance
Oct 27, 2022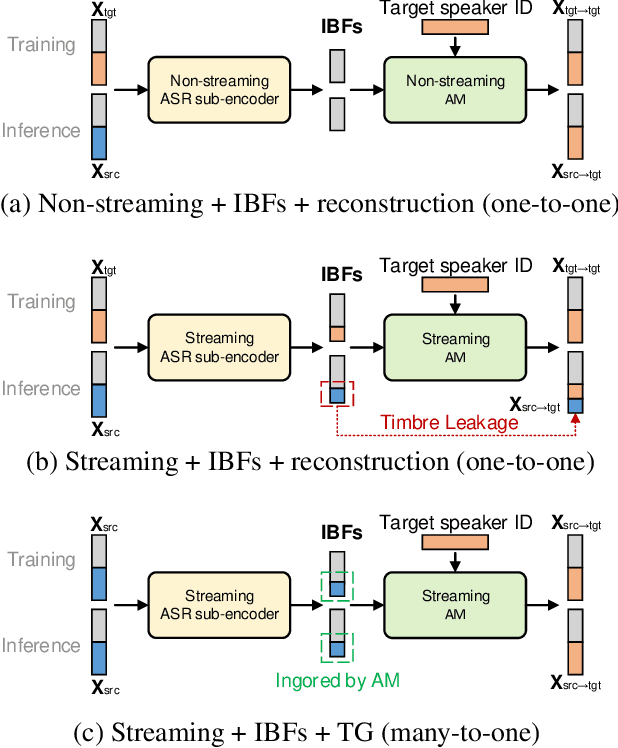
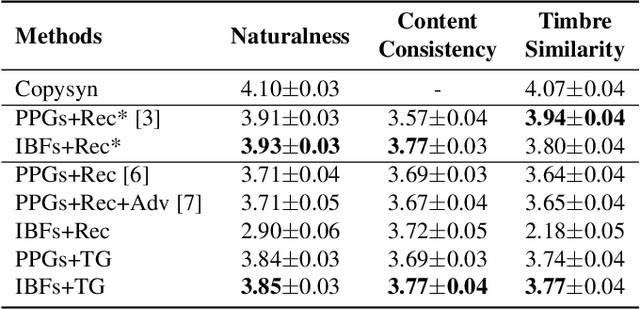
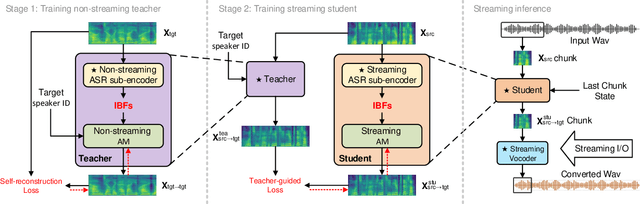
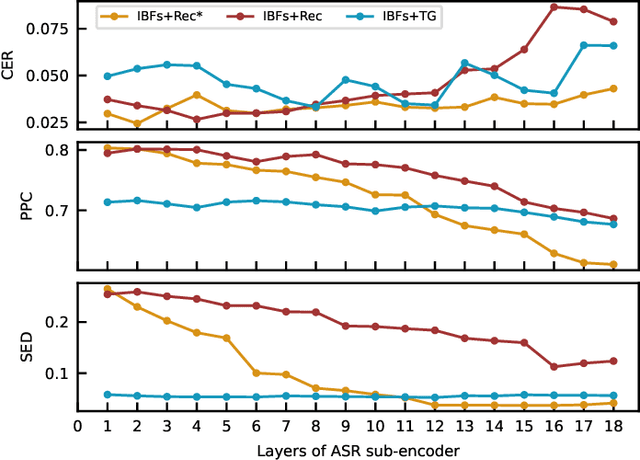
Streaming voice conversion (VC) is the task of converting the voice of one person to another in real-time. Previous streaming VC methods use phonetic posteriorgrams (PPGs) extracted from automatic speech recognition (ASR) systems to represent speaker-independent information. However, PPGs lack the prosody and vocalization information of the source speaker, and streaming PPGs contain undesired leaked timbre of the source speaker. In this paper, we propose to use intermediate bottleneck features (IBFs) to replace PPGs. VC systems trained with IBFs retain more prosody and vocalization information of the source speaker. Furthermore, we propose a non-streaming teacher guidance (TG) framework that addresses the timbre leakage problem. Experiments show that our proposed IBFs and the TG framework achieve a state-of-the-art streaming VC naturalness of 3.85, a content consistency of 3.77, and a timbre similarity of 3.77 under a future receptive field of 160 ms which significantly outperform previous streaming VC systems.
Cloning one's voice using very limited data in the wild
Oct 08, 2021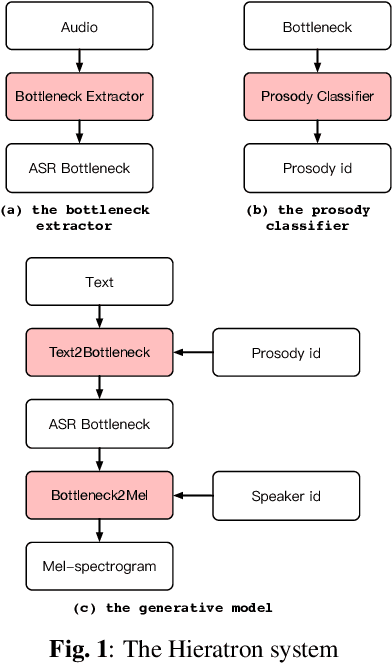
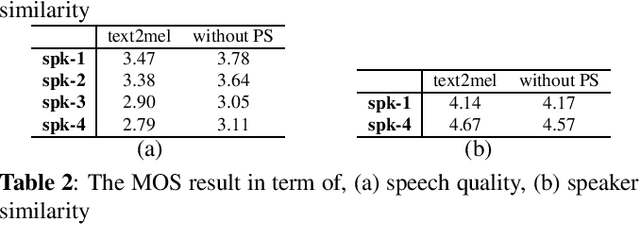
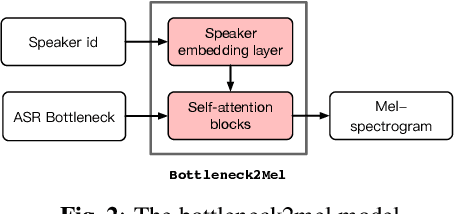
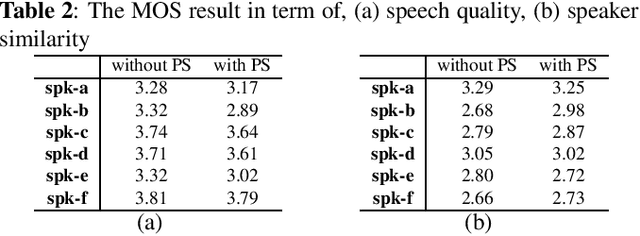
With the increasing popularity of speech synthesis products, the industry has put forward more requirements for personalized speech synthesis: (1) How to use low-resource, easily accessible data to clone a person's voice. (2) How to clone a person's voice while controlling the style and prosody. To solve the above two problems, we proposed the Hieratron model framework in which the prosody and timbre are modeled separately using two modules, therefore, the independent control of timbre and the other characteristics of audio can be achieved while generating speech. The practice shows that, for very limited target speaker data in the wild, Hieratron has obvious advantages over the traditional method, in addition to controlling the style and language of the generated speech, the mean opinion score on speech quality of the generated speech has also been improved by more than 0.2 points.
Graph Sequential Network for Reasoning over Sequences
Apr 04, 2020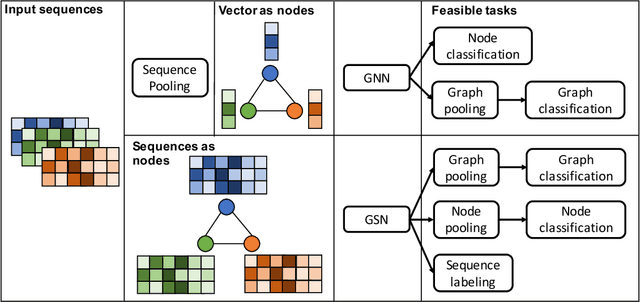


Recently Graph Neural Network (GNN) has been applied successfully to various NLP tasks that require reasoning, such as multi-hop machine reading comprehension. In this paper, we consider a novel case where reasoning is needed over graphs built from sequences, i.e. graph nodes with sequence data. Existing GNN models fulfill this goal by first summarizing the node sequences into fixed-dimensional vectors, then applying GNN on these vectors. To avoid information loss inherent in the early summarization and make sequential labeling tasks on GNN output feasible, we propose a new type of GNN called Graph Sequential Network (GSN), which features a new message passing algorithm based on co-attention between a node and each of its neighbors. We validate the proposed GSN on two NLP tasks: interpretable multi-hop reading comprehension on HotpotQA and graph based fact verification on FEVER. Both tasks require reasoning over multiple documents or sentences. Our experimental results show that the proposed GSN attains better performance than the standard GNN based methods.