 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Family Speculative Prefill: Training-Free Long-Context Compression with Small Draft Models
Mar 03, 2026Prompt length is a major bottleneck in agentic large language model (LLM) workloads, where repeated inference steps and multi-call loops incur substantial prefill cost. Recent work on speculative prefill demonstrates that attention-based token importance estimation can enable training-free prompt compression, but this assumes the existence of a draft model that shares the same tokenizer as the target model. In practice, however, agentic pipelines frequently employ models without any smaller in-family draft model. In this work, we study cross-family speculative prefill, where a lightweight draft model from one model family is used to perform prompt compression for a target model from a different family. Using the same speculative prefill mechanism as prior work, we evaluate a range of cross-family draft-target combinations, including Qwen, LLaMA, and DeepSeek models. Across a broad diversity of tasks, we find that attention-based token importance estimation transfers reliably across different model families despite differences in model architectures and tokenizers between draft and target models. Cross-model prompt compression largely retains 90~100% of full-prompt baseline performance and, in some cases, slightly improves accuracy due to denoising effects, while delivering substantial reductions in time to first token (TTFT). These results suggest that speculative prefill depends mainly on task priors and semantic structure, thus serving as a generalizable prompt compression primitive. We discuss the implications of our findings for agentic systems, where repeated long-context inference and heterogeneous model stacks make cross-model prompt compression both necessary and practical.
LLMs Know What to Drop: Self-Attention Guided KV Cache Eviction for Efficient Long-Context Inference
Mar 11, 2025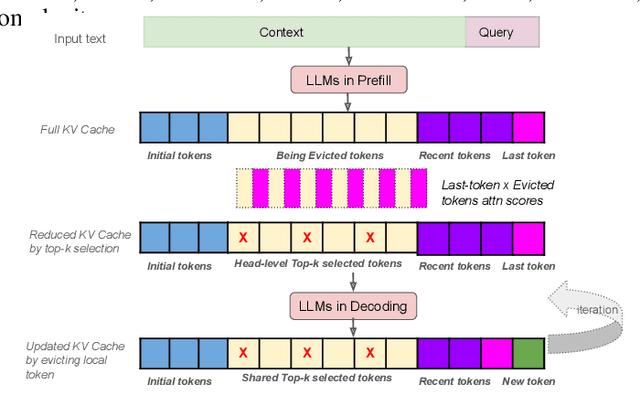
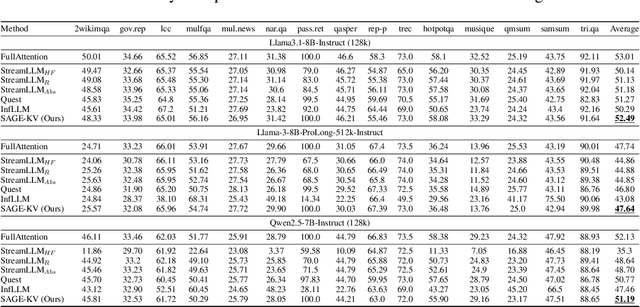
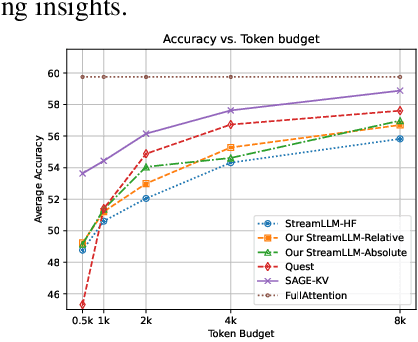
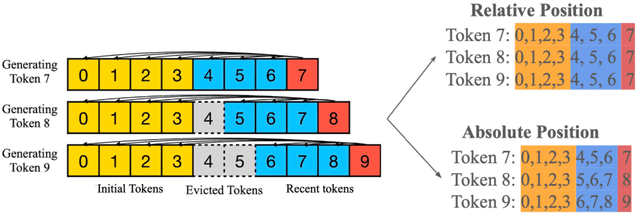
Efficient long-context inference is critical as large language models (LLMs) adopt context windows of ranging from 128K to 1M tokens. However, the growing key-value (KV) cache and the high computational complexity of attention create significant bottlenecks in memory usage and latency. In this paper, we find that attention in diverse long-context tasks exhibits sparsity, and LLMs implicitly "know" which tokens can be dropped or evicted at the head level after the pre-filling stage. Based on this insight, we propose Self-Attention Guided Eviction~(SAGE-KV), a simple and effective KV eviction cache method for long-context inference. After prefilling, our method performs a one-time top-k selection at both the token and head levels to compress the KV cache, enabling efficient inference with the reduced cache. Evaluations on LongBench and three long-context LLMs (Llama3.1-8B-Instruct-128k, Llama3-8B-Prolong-512k-Instruct, and Qwen2.5-7B-Instruct-128k) show that SAGE-KV maintains accuracy comparable to full attention while significantly improving efficiency. Specifically, SAGE-KV achieves 4x higher memory efficiency with improved accuracy over the static KV cache selection method StreamLLM, and 2x higher memory efficiency with better accuracy than the dynamic KV cache selection method Quest.
EfficientSRFace: An Efficient Network with Super-Resolution Enhancement for Accurate Face Detection
Jun 04, 2023
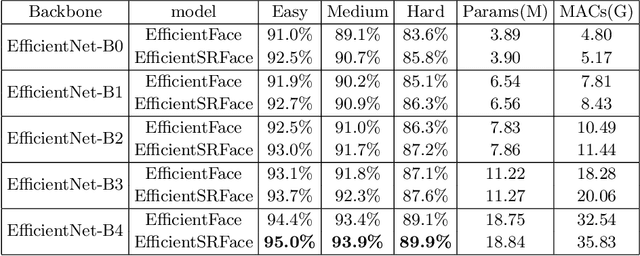
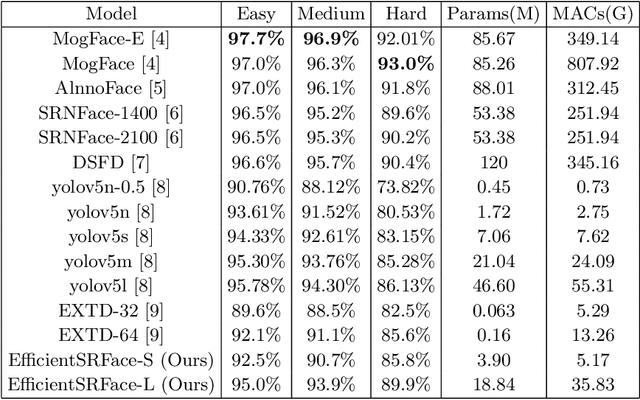
In face detection, low-resolution faces, such as numerous small faces of a human group in a crowded scene, are common in dense face prediction tasks. They usually contain limited visual clues and make small faces less distinguishable from the other small objects, which poses great challenge to accurate face detection. Although deep convolutional neural network has significantly promoted the research on face detection recently, current deep face detectors rarely take into account low-resolution faces and are still vulnerable to the real-world scenarios where massive amount of low-resolution faces exist. Consequently, they usually achieve degraded performance for low-resolution face detection. In order to alleviate this problem, we develop an efficient detector termed EfficientSRFace by introducing a feature-level super-resolution reconstruction network for enhancing the feature representation capability of the model. This module plays an auxiliary role in the training process, and can be removed during the inference without increasing the inference time. Extensive experiments on public benchmarking datasets, such as FDDB and WIDER Face, show that the embedded image super-resolution module can significantly improve the detection accuracy at the cost of a small amount of additional parameters and computational overhead, while helping our model achieve competitive performance compared with the state-of-the-arts methods.
Imbalanced Node Classification Beyond Homophilic Assumption
Apr 28, 2023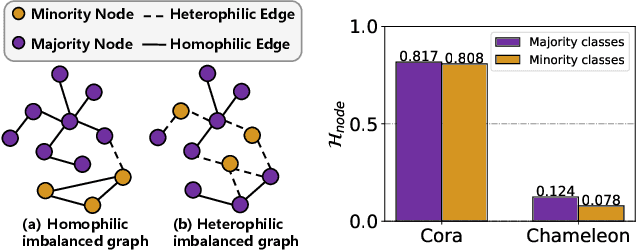
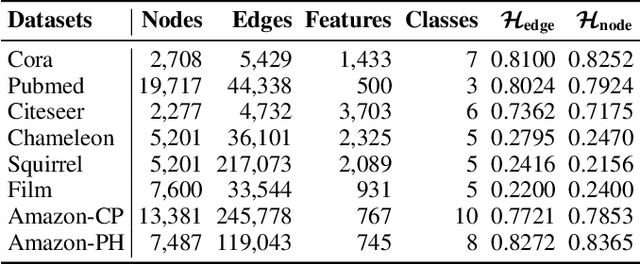
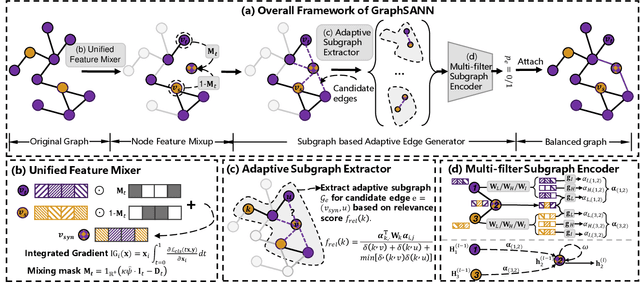
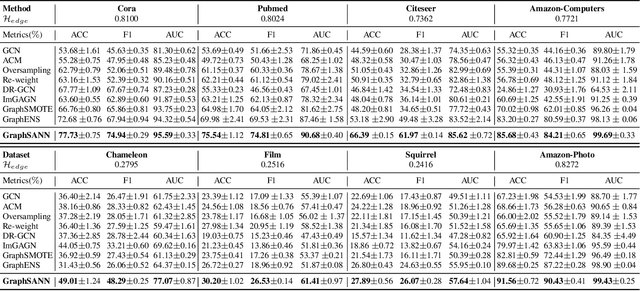
Imbalanced node classification widely exists in real-world networks where graph neural networks (GNNs) are usually highly inclined to majority classes and suffer from severe performance degradation on classifying minority class nodes. Various imbalanced node classification methods have been proposed recently which construct synthetic nodes and edges w.r.t. minority classes to balance the label and topology distribution. However, they are all based on the homophilic assumption that nodes of the same label tend to connect despite the wide existence of heterophilic edges in real-world graphs. Thus, they uniformly aggregate features from both homophilic and heterophilic neighbors and rely on feature similarity to generate synthetic edges, which cannot be applied to imbalanced graphs in high heterophily. To address this problem, we propose a novel GraphSANN for imbalanced node classification on both homophilic and heterophilic graphs. Firstly, we propose a unified feature mixer to generate synthetic nodes with both homophilic and heterophilic interpolation in a unified way. Next, by randomly sampling edges between synthetic nodes and existing nodes as candidate edges, we design an adaptive subgraph extractor to adaptively extract the contextual subgraphs of candidate edges with flexible ranges. Finally, we develop a multi-filter subgraph encoder that constructs different filter channels to discriminatively aggregate neighbor's information along the homophilic and heterophilic edges. Extensive experiments on eight datasets demonstrate the superiority of our model for imbalanced node classification on both homophilic and heterophilic graphs.
EfficientFace: An Efficient Deep Network with Feature Enhancement for Accurate Face Detection
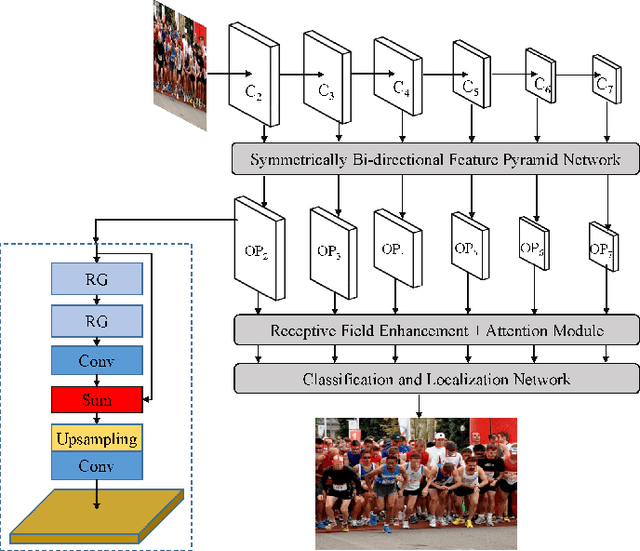
Feb 23, 2023In recent years, deep convolutional neural networks (CNN) have significantly advanced face detection. In particular, lightweight CNNbased architectures have achieved great success due to their lowcomplexity structure facilitating real-time detection tasks. However, current lightweight CNN-based face detectors trading accuracy for efficiency have inadequate capability in handling insufficient feature representation, faces with unbalanced aspect ratios and occlusion. Consequently, they exhibit deteriorated performance far lagging behind the deep heavy detectors. To achieve efficient face detection without sacrificing accuracy, we design an efficient deep face detector termed EfficientFace in this study, which contains three modules for feature enhancement. To begin with, we design a novel cross-scale feature fusion strategy to facilitate bottom-up information propagation, such that fusing low-level and highlevel features is further strengthened. Besides, this is conducive to estimating the locations of faces and enhancing the descriptive power of face features. Secondly, we introduce a Receptive Field Enhancement module to consider faces with various aspect ratios. Thirdly, we add an Attention Mechanism module for improving the representational capability of occluded faces. We have evaluated EfficientFace on four public benchmarks and experimental results demonstrate the appealing performance of our method. In particular, our model respectively achieves 95.1% (Easy), 94.0% (Medium) and 90.1% (Hard) on validation set of WIDER Face dataset, which is competitive with heavyweight models with only 1/15 computational costs of the state-of-the-art MogFace detector.
SpanDrop: Simple and Effective Counterfactual Learning for Long Sequences
Aug 03, 2022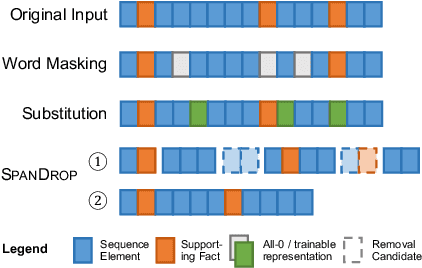
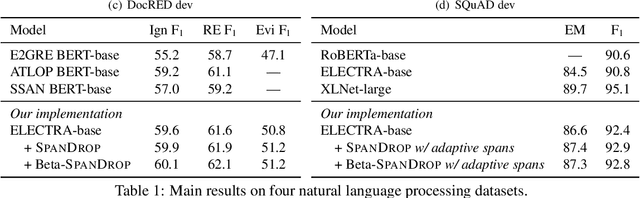
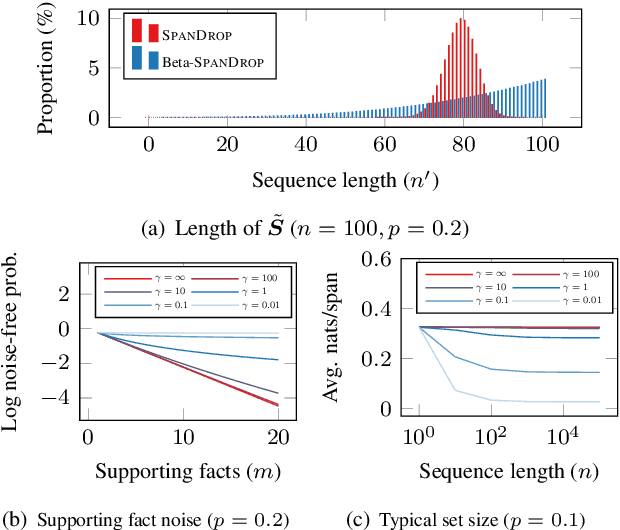
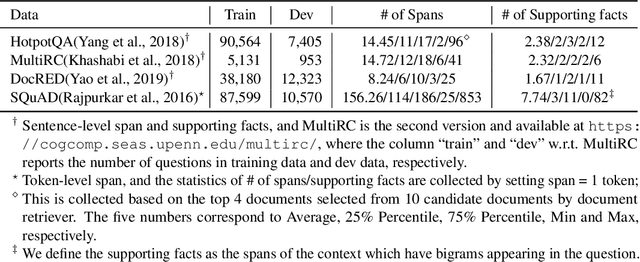
Distilling supervision signal from a long sequence to make predictions is a challenging task in machine learning, especially when not all elements in the input sequence contribute equally to the desired output. In this paper, we propose SpanDrop, a simple and effective data augmentation technique that helps models identify the true supervision signal in a long sequence with very few examples. By directly manipulating the input sequence, SpanDrop randomly ablates parts of the sequence at a time and ask the model to perform the same task to emulate counterfactual learning and achieve input attribution. Based on theoretical analysis of its properties, we also propose a variant of SpanDrop based on the beta-Bernoulli distribution, which yields diverse augmented sequences while providing a learning objective that is more consistent with the original dataset. We demonstrate the effectiveness of SpanDrop on a set of carefully designed toy tasks, as well as various natural language processing tasks that require reasoning over long sequences to arrive at the correct answer, and show that it helps models improve performance both when data is scarce and abundant.
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
Mar 01, 2022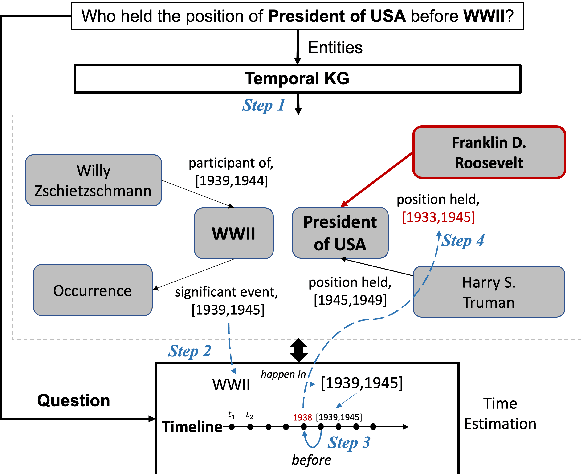
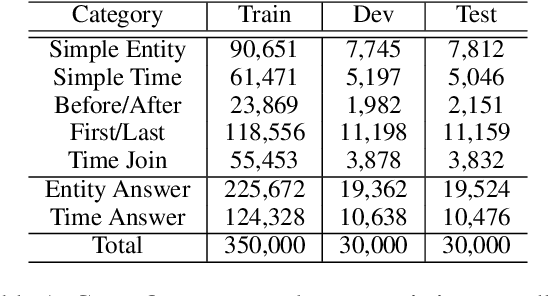
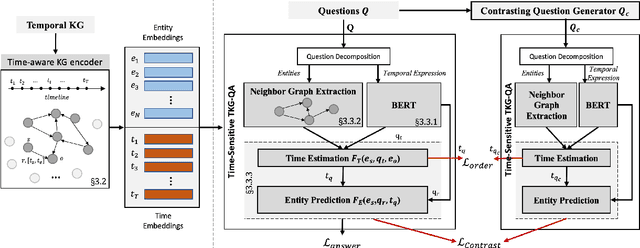
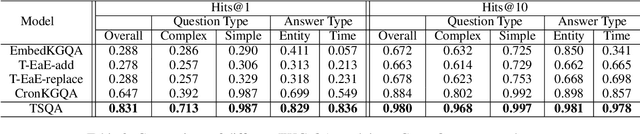
Question answering over temporal knowledge graphs (KGs) efficiently uses facts contained in a temporal KG, which records entity relations and when they occur in time, to answer natural language questions (e.g., "Who was the president of the US before Obama?"). These questions often involve three time-related challenges that previous work fail to adequately address: 1) questions often do not specify exact timestamps of interest (e.g., "Obama" instead of 2000); 2) subtle lexical differences in time relations (e.g., "before" vs "after"); 3) off-the-shelf temporal KG embeddings that previous work builds on ignore the temporal order of timestamps, which is crucial for answering temporal-order related questions. In this paper, we propose a time-sensitive question answering (TSQA) framework to tackle these problems. TSQA features a timestamp estimation module to infer the unwritten timestamp from the question. We also employ a time-sensitive KG encoder to inject ordering information into the temporal KG embeddings that TSQA is based on. With the help of techniques to reduce the search space for potential answers, TSQA significantly outperforms the previous state of the art on a new benchmark for question answering over temporal KGs, especially achieving a 32% (absolute) error reduction on complex questions that require multiple steps of reasoning over facts in the temporal KG.
* 10 pages, 2 figures
Graph Ensemble Learning over Multiple Dependency Trees for Aspect-level Sentiment Classification
Mar 12, 2021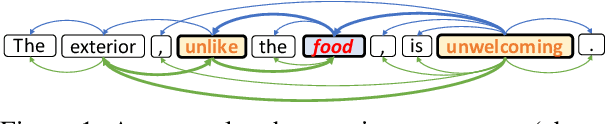
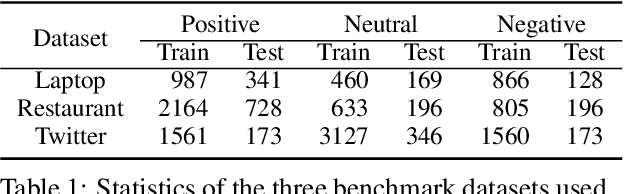
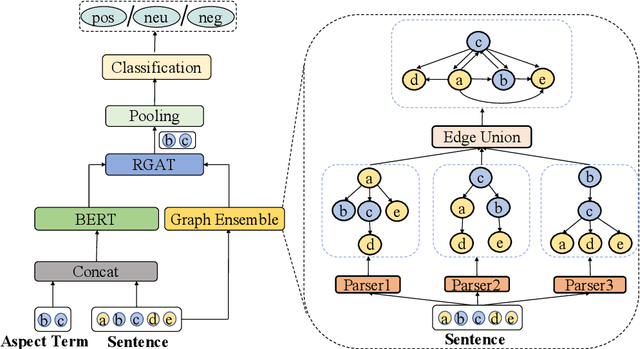
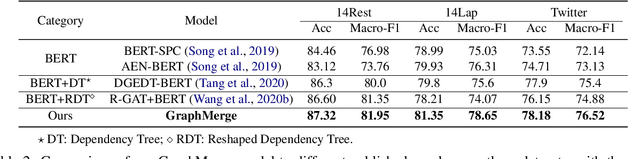
Recent work on aspect-level sentiment classification has demonstrated the efficacy of incorporating syntactic structures such as dependency trees with graph neural networks(GNN), but these approaches are usually vulnerable to parsing errors. To better leverage syntactic information in the face of unavoidable errors, we propose a simple yet effective graph ensemble technique, GraphMerge, to make use of the predictions from differ-ent parsers. Instead of assigning one set of model parameters to each dependency tree, we first combine the dependency relations from different parses before applying GNNs over the resulting graph. This allows GNN mod-els to be robust to parse errors at no additional computational cost, and helps avoid overparameterization and overfitting from GNN layer stacking by introducing more connectivity into the ensemble graph. Our experiments on the SemEval 2014 Task 4 and ACL 14 Twitter datasets show that our GraphMerge model not only outperforms models with single dependency tree, but also beats other ensemble mod-els without adding model parameters.
Ensemble Learning Based Classification Algorithm Recommendation
Jan 15, 2021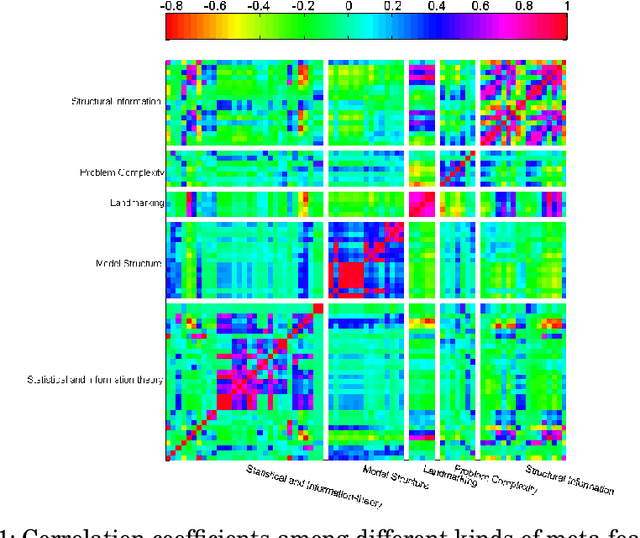
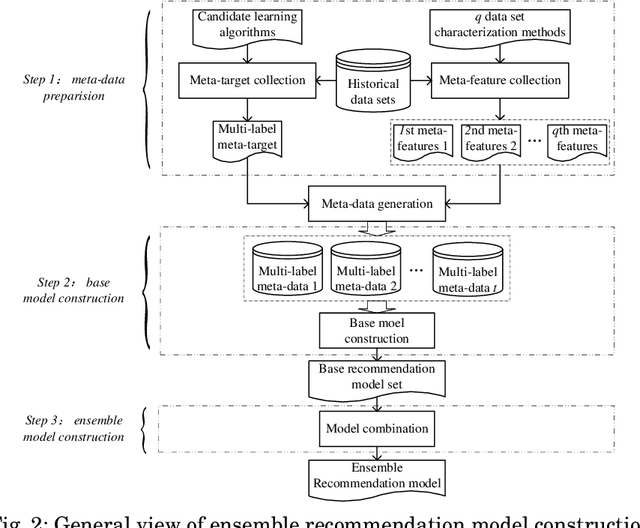

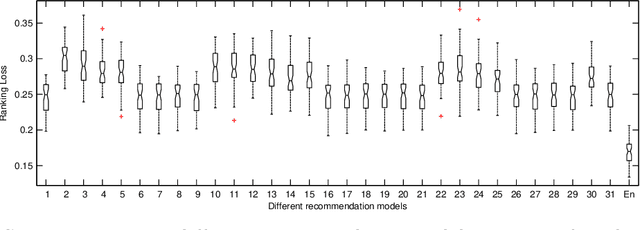
Recommending appropriate algorithms to a classification problem is one of the most challenging issues in the field of data mining. The existing algorithm recommendation models are generally constructed on only one kind of meta-features by single learners. Considering that i) ensemble learners usually show better performance and ii) different kinds of meta-features characterize the classification problems in different viewpoints independently, and further the models constructed with different sets of meta-features will be complementary with each other and applicable for ensemble. This paper proposes an ensemble learning-based algorithm recommendation method. To evaluate the proposed recommendation method, extensive experiments with 13 well-known candidate classification algorithms and five different kinds of meta-features are conducted on 1090 benchmark classification problems. The results show the effectiveness of the proposed ensemble learning based recommendation method.
Direct Multi-hop Attention based Graph Neural Network
Oct 02, 2020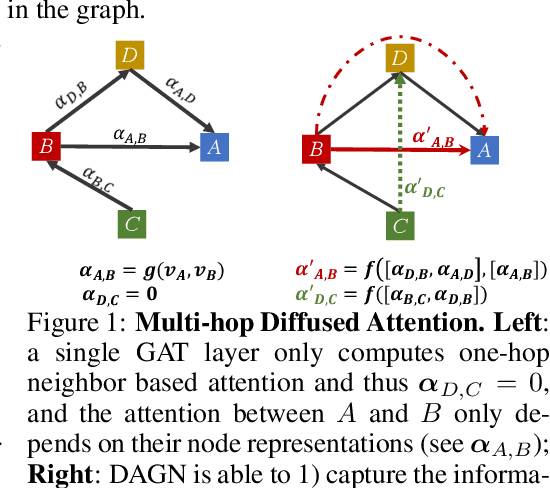
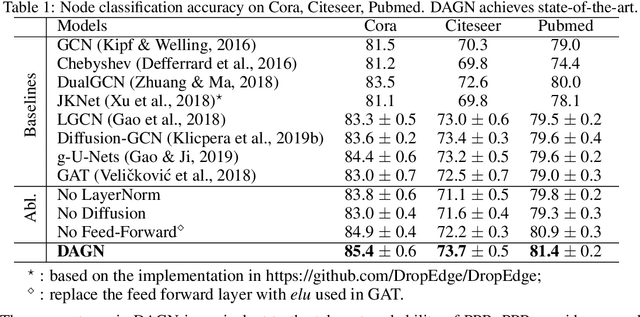
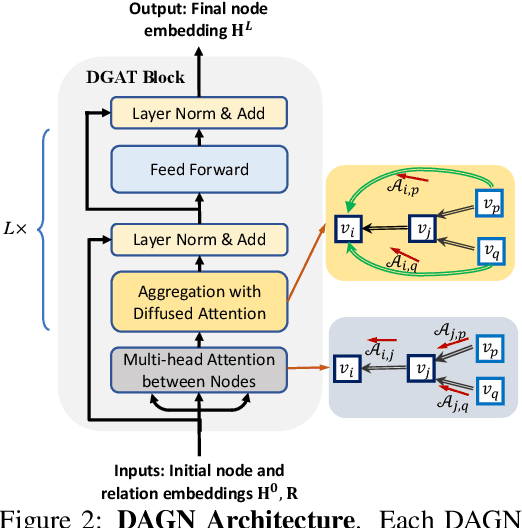
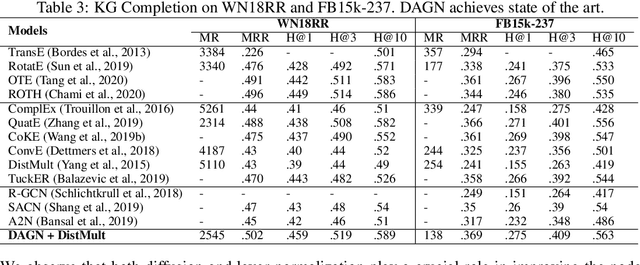
Introducing self-attention mechanism in graph neural networks (GNNs) achieved state-of-the-art performance for graph representation learning. However, at every layer, attention is only computed between two connected nodes and depends solely on the representation of both nodes. This attention computation cannot account for the multi-hop neighbors which supply graph structure context information and have influence on the node representation learning as well. In this paper, we propose Direct Multi-hop Attention based Graph neural Network (DAGN) for graph representation learning, a principled way to incorporate multi-hop neighboring context into attention computation, enabling long-range interactions at every layer. To compute attention between nodes that are multiple hops away, DAGN diffuses the attention scores from neighboring nodes to non-neighboring nodes, thus increasing the receptive field for every message passing layer. Unlike previous methods, DAGN uses a diffusion prior on attention values, to efficiently account for all paths between the pair of nodes when computing multi-hop attention weights. This helps DAGN capture large-scale structural information in a single layer, and learn more informative attention distribution. Experimental results on standard semi-supervised node classification as well as the knowledge graph completion show that DAGN achieves state-of-the-art results: DAGN achieves up to 5.7% relative error reduction over the previous state-of-the-art on Cora, Citeseer, and Pubmed. DAGN also obtains the best performance on a large-scale Open Graph Benchmark dataset. On knowledge graph completion DAGN advances state-of-the-art on WN18RR and FB15k-237 across four different performance metrics.