 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgescGSDR: Harnessing Gene Semantics for Single-Cell Pharmacological Profiling
Feb 02, 2025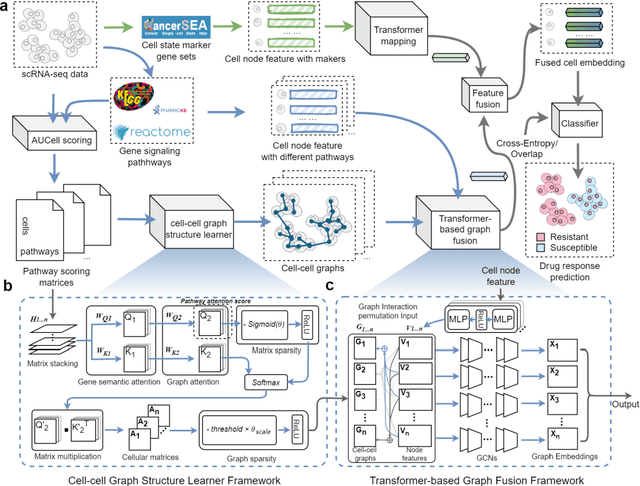



The rise of single-cell sequencing technologies has revolutionized the exploration of drug resistance, revealing the crucial role of cellular heterogeneity in advancing precision medicine. By building computational models from existing single-cell drug response data, we can rapidly annotate cellular responses to drugs in subsequent trials. To this end, we developed scGSDR, a model that integrates two computational pipelines grounded in the knowledge of cellular states and gene signaling pathways, both essential for understanding biological gene semantics. scGSDR enhances predictive performance by incorporating gene semantics and employs an interpretability module to identify key pathways contributing to drug resistance phenotypes. Our extensive validation, which included 16 experiments covering 11 drugs, demonstrates scGSDR's superior predictive accuracy, when trained with either bulk-seq or scRNA-seq data, achieving high AUROC, AUPR, and F1 Scores. The model's application has extended from single-drug predictions to scenarios involving drug combinations. Leveraging pathways of known drug target genes, we found that scGSDR's cell-pathway attention scores are biologically interpretable, which helped us identify other potential drug-related genes. Literature review of top-ranking genes in our predictions such as BCL2, CCND1, the AKT family, and PIK3CA for PLX4720; and ICAM1, VCAM1, NFKB1, NFKBIA, and RAC1 for Paclitaxel confirmed their relevance. In conclusion, scGSDR, by incorporating gene semantics, enhances predictive modeling of cellular responses to diverse drugs, proving invaluable for scenarios involving both single drug and combination therapies and effectively identifying key resistance-related pathways, thus advancing precision medicine and targeted therapy development.
Federated Deep Subspace Clustering
Dec 31, 2024This paper introduces FDSC, a private-protected subspace clustering (SC) approach with federated learning (FC) schema. In each client, there is a deep subspace clustering network accounting for grouping the isolated data, composed of a encode network, a self-expressive layer, and a decode network. FDSC is achieved by uploading the encode network to communicate with other clients in the server. Besides, FDSC is also enhanced by preserving the local neighborhood relationship in each client. With the effects of federated learning and locality preservation, the learned data features from the encoder are boosted so as to enhance the self-expressiveness learning and result in better clustering performance. Experiments test FDSC on public datasets and compare with other clustering methods, demonstrating the effectiveness of FDSC.
Cooperative SQL Generation for Segmented Databases By Using Multi-functional LLM Agents
Dec 08, 2024



Text-to-SQL task aims to automatically yield SQL queries according to user text questions. To address this problem, we propose a Cooperative SQL Generation framework based on Multi-functional Agents (CSMA) through information interaction among large language model (LLM) based agents who own part of the database schema seperately. Inspired by the collaboration in human teamwork, CSMA consists of three stages: 1) Question-related schema collection, 2) Question-corresponding SQL query generation, and 3) SQL query correctness check. In the first stage, agents analyze their respective schema and communicate with each other to collect the schema information relevant to the question. In the second stage, agents try to generate the corresponding SQL query for the question using the collected information. In the third stage, agents check if the SQL query is created correctly according to their known information. This interaction-based method makes the question-relevant part of database schema from each agent to be used for SQL generation and check. Experiments on the Spider and Bird benckmark demonstrate that CSMA achieves a high performance level comparable to the state-of-the-arts, meanwhile holding the private data in these individual agents.
Spatial-temporal Memories Enhanced Graph Autoencoder for Anomaly Detection in Dynamic Graphs
Mar 14, 2024Anomaly detection in dynamic graphs presents a significant challenge due to the temporal evolution of graph structures and attributes. The conventional approaches that tackle this problem typically employ an unsupervised learning framework, capturing normality patterns with exclusive normal data during training and identifying deviations as anomalies during testing. However, these methods face critical drawbacks: they either only depend on proxy tasks for general representation without directly pinpointing normal patterns, or they neglect to differentiate between spatial and temporal normality patterns, leading to diminished efficacy in anomaly detection. To address these challenges, we introduce a novel Spatial-Temporal memories-enhanced graph autoencoder (STRIPE). Initially, STRIPE employs Graph Neural Networks (GNNs) and gated temporal convolution layers to extract spatial features and temporal features, respectively. Then STRIPE incorporates separate spatial and temporal memory networks, which capture and store prototypes of normal patterns, thereby preserving the uniqueness of spatial and temporal normality. After that, through a mutual attention mechanism, these stored patterns are then retrieved and integrated with encoded graph embeddings. Finally, the integrated features are fed into the decoder to reconstruct the graph streams which serve as the proxy task for anomaly detection. This comprehensive approach not only minimizes reconstruction errors but also refines the model by emphasizing the compactness and distinctiveness of the embeddings in relation to the nearest memory prototypes. Through extensive testing, STRIPE has demonstrated a superior capability to discern anomalies by effectively leveraging the distinct spatial and temporal dynamics of dynamic graphs, significantly outperforming existing methodologies, with an average improvement of 15.39% on AUC values.
Federated learning-outcome prediction with multi-layer privacy protection
Dec 25, 2023Learning-outcome prediction (LOP) is a long-standing and critical problem in educational routes. Many studies have contributed to developing effective models while often suffering from data shortage and low generalization to various institutions due to the privacy-protection issue. To this end, this study proposes a distributed grade prediction model, dubbed FecMap, by exploiting the federated learning (FL) framework that preserves the private data of local clients and communicates with others through a global generalized model. FecMap considers local subspace learning (LSL), which explicitly learns the local features against the global features, and multi-layer privacy protection (MPP), which hierarchically protects the private features, including model-shareable features and not-allowably shared features, to achieve client-specific classifiers of high performance on LOP per institution. FecMap is then achieved in an iteration manner with all datasets distributed on clients by training a local neural network composed of a global part, a local part, and a classification head in clients and averaging the global parts from clients on the server. To evaluate the FecMap model, we collected three higher-educational datasets of student academic records from engineering majors. Experiment results manifest that FecMap benefits from the proposed LSL and MPP and achieves steady performance on the task of LOP, compared with the state-of-the-art models. This study makes a fresh attempt at the use of federated learning in the learning-analytical task, potentially paving the way to facilitating personalized education with privacy protection.
* 10 pages, 9 figures, 3 tables. This preprint will be published in Frontiers of Computer Science on Dec 15, 2024
Concept Prerequisite Relation Prediction by Using Permutation-Equivariant Directed Graph Neural Networks
Dec 15, 2023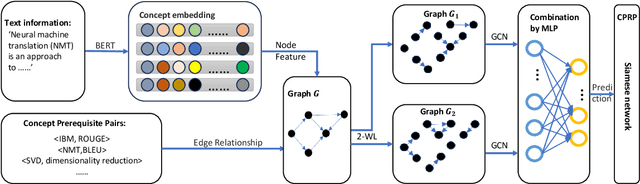
This paper studies the problem of CPRP, concept prerequisite relation prediction, which is a fundamental task in using AI for education. CPRP is usually formulated into a link-prediction task on a relationship graph of concepts and solved by training the graph neural network (GNN) model. However, current directed GNNs fail to manage graph isomorphism which refers to the invariance of non-isomorphic graphs, reducing the expressivity of resulting representations. We present a permutation-equivariant directed GNN model by introducing the Weisfeiler-Lehman test into directed GNN learning. Our method is then used for CPRP and evaluated on three public datasets. The experimental results show that our model delivers better prediction performance than the state-of-the-art methods.
BOURNE: Bootstrapped Self-supervised Learning Framework for Unified Graph Anomaly Detection
Jul 28, 2023Graph anomaly detection (GAD) has gained increasing attention in recent years due to its critical application in a wide range of domains, such as social networks, financial risk management, and traffic analysis. Existing GAD methods can be categorized into node and edge anomaly detection models based on the type of graph objects being detected. However, these methods typically treat node and edge anomalies as separate tasks, overlooking their associations and frequent co-occurrences in real-world graphs. As a result, they fail to leverage the complementary information provided by node and edge anomalies for mutual detection. Additionally, state-of-the-art GAD methods, such as CoLA and SL-GAD, heavily rely on negative pair sampling in contrastive learning, which incurs high computational costs, hindering their scalability to large graphs. To address these limitations, we propose a novel unified graph anomaly detection framework based on bootstrapped self-supervised learning (named BOURNE). We extract a subgraph (graph view) centered on each target node as node context and transform it into a dual hypergraph (hypergraph view) as edge context. These views are encoded using graph and hypergraph neural networks to capture the representations of nodes, edges, and their associated contexts. By swapping the context embeddings between nodes and edges and measuring the agreement in the embedding space, we enable the mutual detection of node and edge anomalies. Furthermore, we adopt a bootstrapped training strategy that eliminates the need for negative sampling, enabling BOURNE to handle large graphs efficiently. Extensive experiments conducted on six benchmark datasets demonstrate the superior effectiveness and efficiency of BOURNE in detecting both node and edge anomalies.
Imbalanced Node Classification Beyond Homophilic Assumption
Apr 28, 2023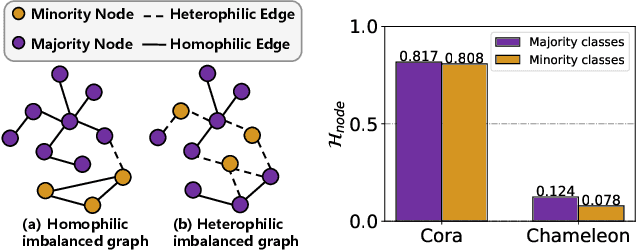
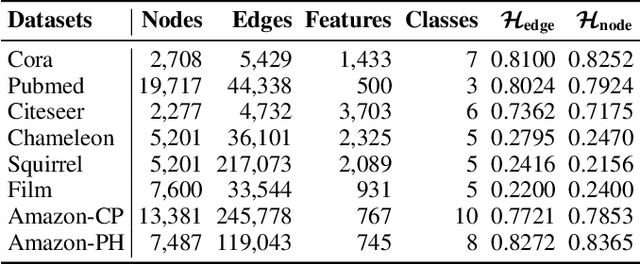
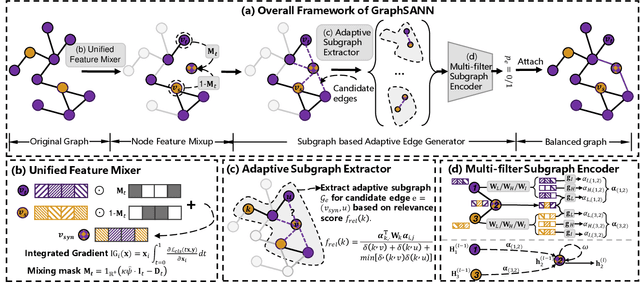
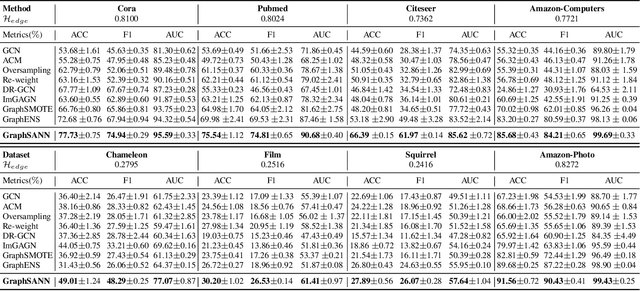
Imbalanced node classification widely exists in real-world networks where graph neural networks (GNNs) are usually highly inclined to majority classes and suffer from severe performance degradation on classifying minority class nodes. Various imbalanced node classification methods have been proposed recently which construct synthetic nodes and edges w.r.t. minority classes to balance the label and topology distribution. However, they are all based on the homophilic assumption that nodes of the same label tend to connect despite the wide existence of heterophilic edges in real-world graphs. Thus, they uniformly aggregate features from both homophilic and heterophilic neighbors and rely on feature similarity to generate synthetic edges, which cannot be applied to imbalanced graphs in high heterophily. To address this problem, we propose a novel GraphSANN for imbalanced node classification on both homophilic and heterophilic graphs. Firstly, we propose a unified feature mixer to generate synthetic nodes with both homophilic and heterophilic interpolation in a unified way. Next, by randomly sampling edges between synthetic nodes and existing nodes as candidate edges, we design an adaptive subgraph extractor to adaptively extract the contextual subgraphs of candidate edges with flexible ranges. Finally, we develop a multi-filter subgraph encoder that constructs different filter channels to discriminatively aggregate neighbor's information along the homophilic and heterophilic edges. Extensive experiments on eight datasets demonstrate the superiority of our model for imbalanced node classification on both homophilic and heterophilic graphs.
Deep Feature Learning of Multi-Network Topology for Node Classification
Sep 07, 2018



Networks are ubiquitous structure that describes complex relationships between different entities in the real world. As a critical component of prediction task over nodes in networks, learning the feature representation of nodes has become one of the most active areas recently. Network Embedding, aiming to learn non-linear and low-dimensional feature representation based on network topology, has been proved to be helpful on tasks of network analysis, especially node classification. For many real-world systems, multiple types of relations are naturally represented by multiple networks. However, existing network embedding methods mainly focus on single network embedding and neglect the information shared among different networks. In this paper, we propose a novel multiple network embedding method based on semisupervised autoencoder, named DeepMNE, which captures complex topological structures of multi-networks and takes the correlation among multi-networks into account. We evaluate DeepMNE on the task of node classification with two real-world datasets. The experimental results demonstrate the superior performance of our method over four state-of-the-art algorithms.