 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc2Spec: Synthesizing Formal Programming Specifications from Natural Language via Grammar Induction
Jan 30, 2026Ensuring that API implementations and usage comply with natural language programming rules is critical for software correctness, security, and reliability. Formal verification can provide strong guarantees but requires precise specifications, which are difficult and costly to write manually. To address this challenge, we present Doc2Spec, a multi-agent framework that uses LLMs to automatically induce a specification grammar from natural-language rules and then generates formal specifications guided by the induced grammar. The grammar captures essential domain knowledge, constrains the specification space, and enforces consistent representations, thereby improving the reliability and quality of generated specifications. Evaluated on seven benchmarks across three programming languages, Doc2Spec outperforms a baseline without grammar induction and achieves competitive results against a technique with a manually crafted grammar, demonstrating the effectiveness of automated grammar induction for formalizing natural-language rules.
SymGPT: Auditing Smart Contracts via Combining Symbolic Execution with Large Language Models
Feb 12, 2025To govern smart contracts running on Ethereum, multiple Ethereum Request for Comment (ERC) standards have been developed, each having a set of rules to guide the behaviors of smart contracts. Violating the ERC rules could cause serious security issues and financial loss, signifying the importance of verifying smart contracts follow ERCs. Today's practices of such verification are to manually audit each single contract, use expert-developed program-analysis tools, or use large language models (LLMs), all of which are far from effective in identifying ERC rule violations. This paper introduces SymGPT, a tool that combines the natural language understanding of large language models (LLMs) with the formal guarantees of symbolic execution to automatically verify smart contracts' compliance with ERC rules. To develop SymGPT, we conduct an empirical study of 132 ERC rules from three widely used ERC standards, examining their content, security implications, and natural language descriptions. Based on this study, we design SymGPT by first instructing an LLM to translate ERC rules into a defined EBNF grammar. We then synthesize constraints from the formalized rules to represent scenarios where violations may occur and use symbolic execution to detect them. Our evaluation shows that SymGPT identifies 5,783 ERC rule violations in 4,000 real-world contracts, including 1,375 violations with clear attack paths for stealing financial assets, demonstrating its effectiveness. Furthermore, SymGPT outperforms six automated techniques and a security-expert auditing service, underscoring its superiority over current smart contract analysis methods.
SC-Bench: A Large-Scale Dataset for Smart Contract Auditing
Oct 08, 2024



There is a huge demand to ensure the compliance of smart contracts listed on blockchain platforms to safety and economic standards. Today, manual efforts in the form of auditing are commonly used to achieve this goal. ML-based automated techniques have the promise to alleviate human efforts and the resulting monetary costs. However, unlike other domains where ML techniques have had huge successes, no systematic ML techniques have been proposed or applied to smart contract auditing. We present SC-Bench, the first dataset for automated smart-contract auditing research. SC-Bench consists of 5,377 real-world smart contracts running on Ethereum, a widely used blockchain platform, and 15,975 violations of standards on Ehereum called ERCs. Out of these violations, 139 are real violations programmers made. The remaining are errors we systematically injected to reflect the violations of different ERC rules. We evaluate SC-Bench using GPT-4 by prompting it with both the contracts and ERC rules. In addition, we manually identify each violated rule and the corresponding code site (i.e., oracle) and prompt GPT-4 with the information asking for a True-or-False question. Our results show that without the oracle, GPT-4 can only detect 0.9% violations, and with the oracle, it detects 22.9% violations. These results show the potential room for improvement in ML-based techniques for smart-contract auditing.
AuditGPT: Auditing Smart Contracts with ChatGPT
Apr 05, 2024To govern smart contracts running on Ethereum, multiple Ethereum Request for Comment (ERC) standards have been developed, each containing a set of rules to guide the behaviors of smart contracts. Violating the ERC rules could cause serious security issues and financial loss, signifying the importance of verifying smart contracts follow ERCs. Today's practices of such verification are to either manually audit each single contract or use expert-developed, limited-scope program-analysis tools, both of which are far from being effective in identifying ERC rule violations. This paper presents a tool named AuditGPT that leverages large language models (LLMs) to automatically and comprehensively verify ERC rules against smart contracts. To build AuditGPT, we first conduct an empirical study on 222 ERC rules specified in four popular ERCs to understand their content, their security impacts, their specification in natural language, and their implementation in Solidity. Guided by the study, we construct AuditGPT by separating the large, complex auditing process into small, manageable tasks and design prompts specialized for each ERC rule type to enhance LLMs' auditing performance. In the evaluation, AuditGPT successfully pinpoints 418 ERC rule violations and only reports 18 false positives, showcasing its effectiveness and accuracy. Moreover, AuditGPT beats an auditing service provided by security experts in effectiveness, accuracy, and cost, demonstrating its advancement over state-of-the-art smart-contract auditing practices.
BOURNE: Bootstrapped Self-supervised Learning Framework for Unified Graph Anomaly Detection
Jul 28, 2023Graph anomaly detection (GAD) has gained increasing attention in recent years due to its critical application in a wide range of domains, such as social networks, financial risk management, and traffic analysis. Existing GAD methods can be categorized into node and edge anomaly detection models based on the type of graph objects being detected. However, these methods typically treat node and edge anomalies as separate tasks, overlooking their associations and frequent co-occurrences in real-world graphs. As a result, they fail to leverage the complementary information provided by node and edge anomalies for mutual detection. Additionally, state-of-the-art GAD methods, such as CoLA and SL-GAD, heavily rely on negative pair sampling in contrastive learning, which incurs high computational costs, hindering their scalability to large graphs. To address these limitations, we propose a novel unified graph anomaly detection framework based on bootstrapped self-supervised learning (named BOURNE). We extract a subgraph (graph view) centered on each target node as node context and transform it into a dual hypergraph (hypergraph view) as edge context. These views are encoded using graph and hypergraph neural networks to capture the representations of nodes, edges, and their associated contexts. By swapping the context embeddings between nodes and edges and measuring the agreement in the embedding space, we enable the mutual detection of node and edge anomalies. Furthermore, we adopt a bootstrapped training strategy that eliminates the need for negative sampling, enabling BOURNE to handle large graphs efficiently. Extensive experiments conducted on six benchmark datasets demonstrate the superior effectiveness and efficiency of BOURNE in detecting both node and edge anomalies.
Imbalanced Node Classification Beyond Homophilic Assumption
Apr 28, 2023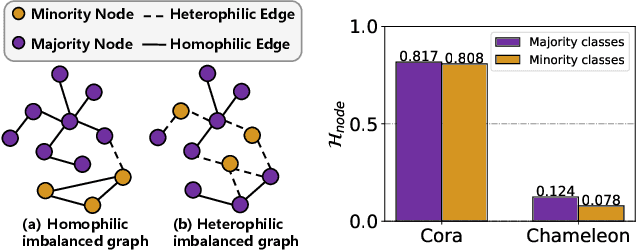
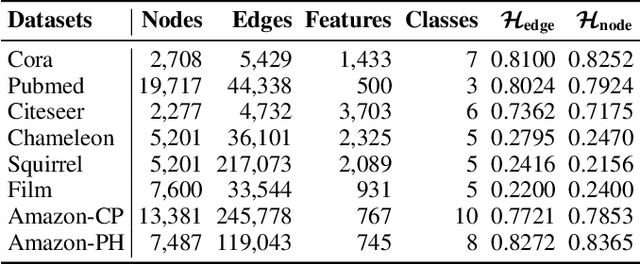
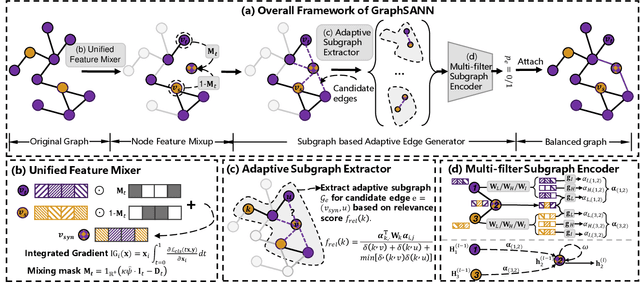
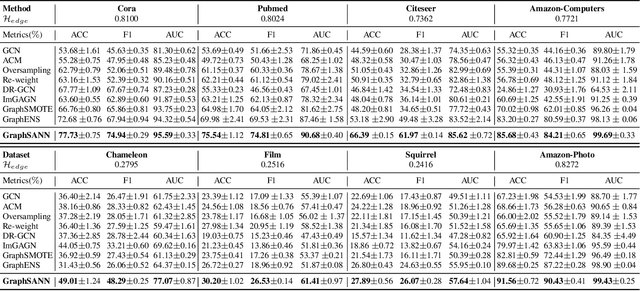
Imbalanced node classification widely exists in real-world networks where graph neural networks (GNNs) are usually highly inclined to majority classes and suffer from severe performance degradation on classifying minority class nodes. Various imbalanced node classification methods have been proposed recently which construct synthetic nodes and edges w.r.t. minority classes to balance the label and topology distribution. However, they are all based on the homophilic assumption that nodes of the same label tend to connect despite the wide existence of heterophilic edges in real-world graphs. Thus, they uniformly aggregate features from both homophilic and heterophilic neighbors and rely on feature similarity to generate synthetic edges, which cannot be applied to imbalanced graphs in high heterophily. To address this problem, we propose a novel GraphSANN for imbalanced node classification on both homophilic and heterophilic graphs. Firstly, we propose a unified feature mixer to generate synthetic nodes with both homophilic and heterophilic interpolation in a unified way. Next, by randomly sampling edges between synthetic nodes and existing nodes as candidate edges, we design an adaptive subgraph extractor to adaptively extract the contextual subgraphs of candidate edges with flexible ranges. Finally, we develop a multi-filter subgraph encoder that constructs different filter channels to discriminatively aggregate neighbor's information along the homophilic and heterophilic edges. Extensive experiments on eight datasets demonstrate the superiority of our model for imbalanced node classification on both homophilic and heterophilic graphs.