 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperEdit: Unlocking Instruction-based Text Editing in LLMs via Hypernetworks
Dec 14, 2025Instruction-based text editing is increasingly critical for real-world applications such as code editors (e.g., Cursor), but Large Language Models (LLMs) continue to struggle with this task. Unlike free-form generation, editing requires faithfully implementing user instructions while preserving unchanged content, as even minor unintended modifications can break functionality. Existing approaches treat editing as generic text generation, leading to two key failures: they struggle to faithfully align edits with diverse user intents, and they often over-edit unchanged regions. We propose HyperEdit to address both issues. First, we introduce hypernetwork-based dynamic adaptation that generates request-specific parameters, enabling the model to tailor its editing strategy to each instruction. Second, we develop difference-aware regularization that focuses supervision on modified spans, preventing over-editing while ensuring precise, minimal changes. HyperEdit achieves a 9%--30% relative improvement in BLEU on modified regions over state-of-the-art baselines, despite utilizing only 3B parameters.
A Fully Automatic Framework for Intracranial Pressure Grading: Integrating Keyframe Identification, ONSD Measurement and Clinical Data
Sep 11, 2025Intracranial pressure (ICP) elevation poses severe threats to cerebral function, thus necessitating monitoring for timely intervention. While lumbar puncture is the gold standard for ICP measurement, its invasiveness and associated risks drive the need for non-invasive alternatives. Optic nerve sheath diameter (ONSD) has emerged as a promising biomarker, as elevated ICP directly correlates with increased ONSD. However, current clinical practices for ONSD measurement suffer from inconsistency in manual operation, subjectivity in optimal view selection, and variability in thresholding, limiting their reliability. To address these challenges, we introduce a fully automatic two-stage framework for ICP grading, integrating keyframe identification, ONSD measurement and clinical data. Specifically, the fundus ultrasound video processing stage performs frame-level anatomical segmentation, rule-based keyframe identification guided by an international consensus statement, and precise ONSD measurement. The intracranial pressure grading stage then fuses ONSD metrics with clinical features to enable the prediction of ICP grades, thereby demonstrating an innovative blend of interpretable ultrasound analysis and multi-source data integration for objective clinical evaluation. Experimental results demonstrate that our method achieves a validation accuracy of $0.845 \pm 0.071$ (with standard deviation from five-fold cross-validation) and an independent test accuracy of 0.786, significantly outperforming conventional threshold-based method ($0.637 \pm 0.111$ validation accuracy, $0.429$ test accuracy). Through effectively reducing operator variability and integrating multi-source information, our framework establishes a reliable non-invasive approach for clinical ICP evaluation, holding promise for improving patient management in acute neurological conditions.
Bridging the Editing Gap in LLMs: FineEdit for Precise and Targeted Text Modifications
Feb 19, 2025Large Language Models (LLMs) have transformed natural language processing, yet they still struggle with direct text editing tasks that demand precise, context-aware modifications. While models like ChatGPT excel in text generation and analysis, their editing abilities often fall short, addressing only superficial issues rather than deeper structural or logical inconsistencies. In this work, we introduce a dual approach to enhance LLMs editing performance. First, we present InstrEditBench, a high-quality benchmark dataset comprising over 20,000 structured editing tasks spanning Wiki articles, LaTeX documents, code, and database Domain-specific Languages (DSL). InstrEditBench is generated using an innovative automated workflow that accurately identifies and evaluates targeted edits, ensuring that modifications adhere strictly to specified instructions without altering unrelated content. Second, we propose FineEdit, a specialized model trained on this curated benchmark. Experimental results demonstrate that FineEdit achieves significant improvements around {10\%} compared with Gemini on direct editing tasks, convincingly validating its effectiveness.
SymGPT: Auditing Smart Contracts via Combining Symbolic Execution with Large Language Models
Feb 12, 2025To govern smart contracts running on Ethereum, multiple Ethereum Request for Comment (ERC) standards have been developed, each having a set of rules to guide the behaviors of smart contracts. Violating the ERC rules could cause serious security issues and financial loss, signifying the importance of verifying smart contracts follow ERCs. Today's practices of such verification are to manually audit each single contract, use expert-developed program-analysis tools, or use large language models (LLMs), all of which are far from effective in identifying ERC rule violations. This paper introduces SymGPT, a tool that combines the natural language understanding of large language models (LLMs) with the formal guarantees of symbolic execution to automatically verify smart contracts' compliance with ERC rules. To develop SymGPT, we conduct an empirical study of 132 ERC rules from three widely used ERC standards, examining their content, security implications, and natural language descriptions. Based on this study, we design SymGPT by first instructing an LLM to translate ERC rules into a defined EBNF grammar. We then synthesize constraints from the formalized rules to represent scenarios where violations may occur and use symbolic execution to detect them. Our evaluation shows that SymGPT identifies 5,783 ERC rule violations in 4,000 real-world contracts, including 1,375 violations with clear attack paths for stealing financial assets, demonstrating its effectiveness. Furthermore, SymGPT outperforms six automated techniques and a security-expert auditing service, underscoring its superiority over current smart contract analysis methods.
AuditGPT: Auditing Smart Contracts with ChatGPT
Apr 05, 2024To govern smart contracts running on Ethereum, multiple Ethereum Request for Comment (ERC) standards have been developed, each containing a set of rules to guide the behaviors of smart contracts. Violating the ERC rules could cause serious security issues and financial loss, signifying the importance of verifying smart contracts follow ERCs. Today's practices of such verification are to either manually audit each single contract or use expert-developed, limited-scope program-analysis tools, both of which are far from being effective in identifying ERC rule violations. This paper presents a tool named AuditGPT that leverages large language models (LLMs) to automatically and comprehensively verify ERC rules against smart contracts. To build AuditGPT, we first conduct an empirical study on 222 ERC rules specified in four popular ERCs to understand their content, their security impacts, their specification in natural language, and their implementation in Solidity. Guided by the study, we construct AuditGPT by separating the large, complex auditing process into small, manageable tasks and design prompts specialized for each ERC rule type to enhance LLMs' auditing performance. In the evaluation, AuditGPT successfully pinpoints 418 ERC rule violations and only reports 18 false positives, showcasing its effectiveness and accuracy. Moreover, AuditGPT beats an auditing service provided by security experts in effectiveness, accuracy, and cost, demonstrating its advancement over state-of-the-art smart-contract auditing practices.
Partial Multi-label Learning with Label and Feature Collaboration
Mar 17, 2020
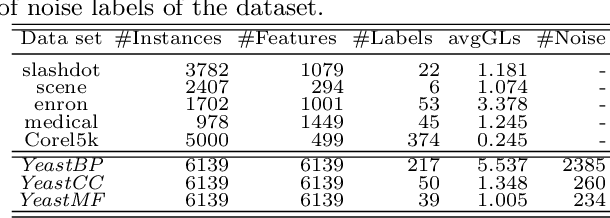
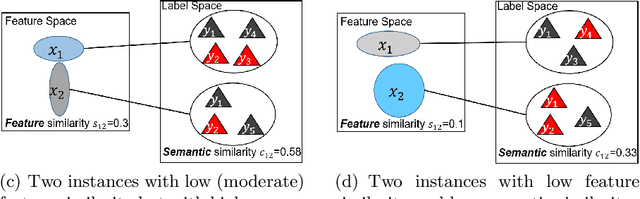
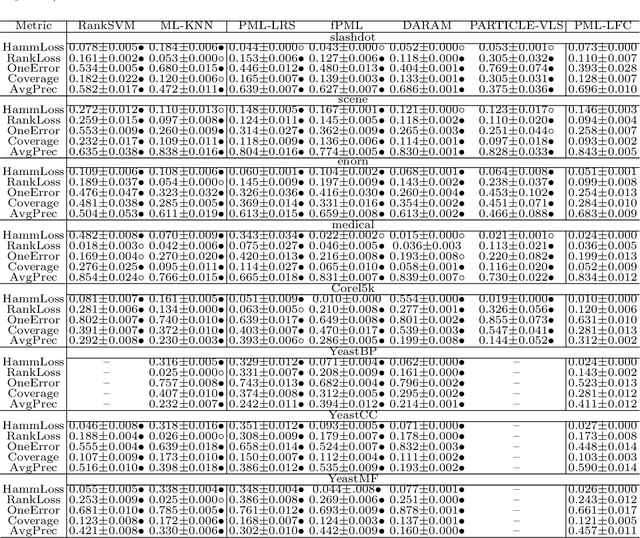
Partial multi-label learning (PML) models the scenario where each training instance is annotated with a set of candidate labels, and only some of the labels are relevant. The PML problem is practical in real-world scenarios, as it is difficult and even impossible to obtain precisely labeled samples. Several PML solutions have been proposed to combat with the prone misled by the irrelevant labels concealed in the candidate labels, but they generally focus on the smoothness assumption in feature space or low-rank assumption in label space, while ignore the negative information between features and labels. Specifically, if two instances have largely overlapped candidate labels, irrespective of their feature similarity, their ground-truth labels should be similar; while if they are dissimilar in the feature and candidate label space, their ground-truth labels should be dissimilar with each other. To achieve a credible predictor on PML data, we propose a novel approach called PML-LFC (Partial Multi-label Learning with Label and Feature Collaboration). PML-LFC estimates the confidence values of relevant labels for each instance using the similarity from both the label and feature spaces, and trains the desired predictor with the estimated confidence values. PML-LFC achieves the predictor and the latent label matrix in a reciprocal reinforce manner by a unified model, and develops an alternative optimization procedure to optimize them. Extensive empirical study on both synthetic and real-world datasets demonstrates the superiority of PML-LFC.