 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Learning of Dynamic Causal Structures
Feb 26, 2026Learning the dynamic causal structure of time series is a challenging problem. Most existing approaches rely on distributional or structural invariance to uncover underlying causal dynamics, assuming stationary or partially stationary causality. However, these assumptions often conflict with the complex, time-varying causal relationships observed in real-world systems. This motivates the need for methods that address fully dynamic causality, where both instantaneous and lagged dependencies evolve over time. Such a setting poses significant challenges for the efficiency and stability of causal discovery. To address these challenges, we introduce DyCausal, a dynamic causal structure learning framework. DyCausal leverages convolutional networks to capture causal patterns within coarse-grained time windows, and then applies linear interpolation to refine causal structures at each time step, thereby recovering fine-grained and time-varying causal graphs. In addition, we propose an acyclic constraint based on matrix norm scaling, which improves efficiency while effectively constraining loops in evolving causal structures. Comprehensive evaluations on both synthetic and real-world datasets demonstrate that DyCausal achieves superior performance compared to existing methods, offering a stable and efficient approach for identifying fully dynamic causal structures from coarse to fine.
Calibration-compatible Listwise Distillation of Privileged Features for CTR Prediction
Dec 14, 2023



In machine learning systems, privileged features refer to the features that are available during offline training but inaccessible for online serving. Previous studies have recognized the importance of privileged features and explored ways to tackle online-offline discrepancies. A typical practice is privileged features distillation (PFD): train a teacher model using all features (including privileged ones) and then distill the knowledge from the teacher model using a student model (excluding the privileged features), which is then employed for online serving. In practice, the pointwise cross-entropy loss is often adopted for PFD. However, this loss is insufficient to distill the ranking ability for CTR prediction. First, it does not consider the non-i.i.d. characteristic of the data distribution, i.e., other items on the same page significantly impact the click probability of the candidate item. Second, it fails to consider the relative item order ranked by the teacher model's predictions, which is essential to distill the ranking ability. To address these issues, we first extend the pointwise-based PFD to the listwise-based PFD. We then define the calibration-compatible property of distillation loss and show that commonly used listwise losses do not satisfy this property when employed as distillation loss, thus compromising the model's calibration ability, which is another important measure for CTR prediction. To tackle this dilemma, we propose Calibration-compatible LIstwise Distillation (CLID), which employs carefully-designed listwise distillation loss to achieve better ranking ability than the pointwise-based PFD while preserving the model's calibration ability. We theoretically prove it is calibration-compatible. Extensive experiments on public datasets and a production dataset collected from the display advertising system of Alibaba further demonstrate the effectiveness of CLID.
Multi-granularity Causal Structure Learning
Dec 12, 2023



Unveil, model, and comprehend the causal mechanisms underpinning natural phenomena stand as fundamental endeavors across myriad scientific disciplines. Meanwhile, new knowledge emerges when discovering causal relationships from data. Existing causal learning algorithms predominantly focus on the isolated effects of variables, overlook the intricate interplay of multiple variables and their collective behavioral patterns. Furthermore, the ubiquity of high-dimensional data exacts a substantial temporal cost for causal algorithms. In this paper, we develop a novel method called MgCSL (Multi-granularity Causal Structure Learning), which first leverages sparse auto-encoder to explore coarse-graining strategies and causal abstractions from micro-variables to macro-ones. MgCSL then takes multi-granularity variables as inputs to train multilayer perceptrons and to delve the causality between variables. To enhance the efficacy on high-dimensional data, MgCSL introduces a simplified acyclicity constraint to adeptly search the directed acyclic graph among variables. Experimental results show that MgCSL outperforms competitive baselines, and finds out explainable causal connections on fMRI datasets.
Multi-dimensional Fair Federated Learning
Dec 09, 2023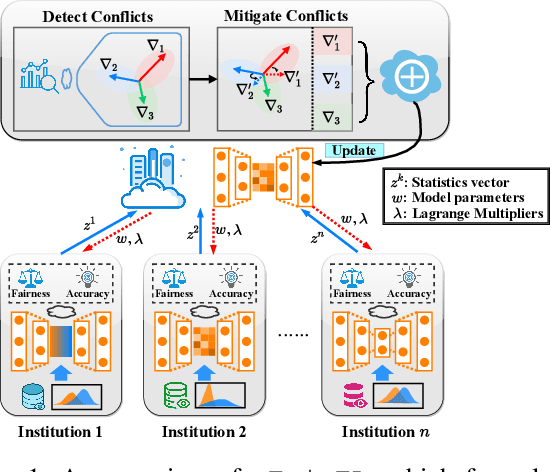
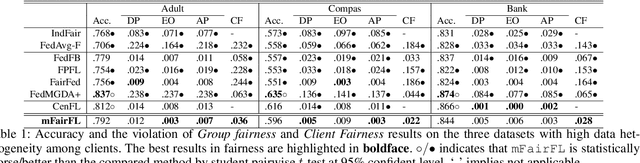
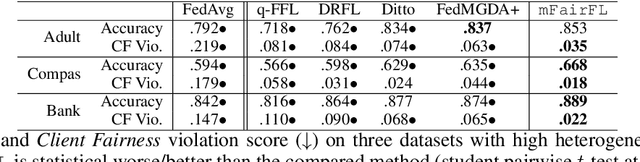
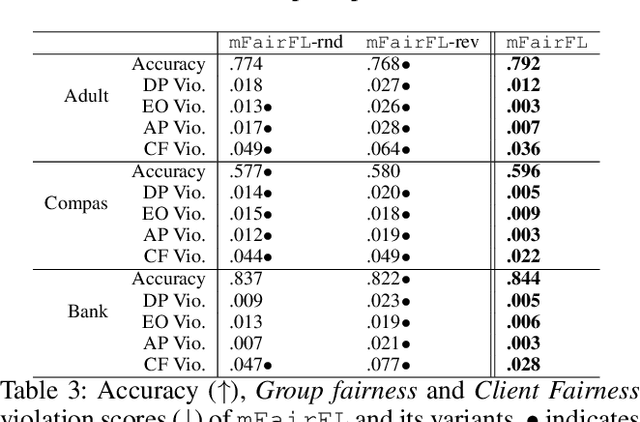
Federated learning (FL) has emerged as a promising collaborative and secure paradigm for training a model from decentralized data without compromising privacy. Group fairness and client fairness are two dimensions of fairness that are important for FL. Standard FL can result in disproportionate disadvantages for certain clients, and it still faces the challenge of treating different groups equitably in a population. The problem of privately training fair FL models without compromising the generalization capability of disadvantaged clients remains open. In this paper, we propose a method, called mFairFL, to address this problem and achieve group fairness and client fairness simultaneously. mFairFL leverages differential multipliers to construct an optimization objective for empirical risk minimization with fairness constraints. Before aggregating locally trained models, it first detects conflicts among their gradients, and then iteratively curates the direction and magnitude of gradients to mitigate these conflicts. Theoretical analysis proves mFairFL facilitates the fairness in model development. The experimental evaluations based on three benchmark datasets show significant advantages of mFairFL compared to seven state-of-the-art baselines.
Federated Causality Learning with Explainable Adaptive Optimization
Dec 09, 2023



Discovering the causality from observational data is a crucial task in various scientific domains. With increasing awareness of privacy, data are not allowed to be exposed, and it is very hard to learn causal graphs from dispersed data, since these data may have different distributions. In this paper, we propose a federated causal discovery strategy (FedCausal) to learn the unified global causal graph from decentralized heterogeneous data. We design a global optimization formula to naturally aggregate the causal graphs from client data and constrain the acyclicity of the global graph without exposing local data. Unlike other federated causal learning algorithms, FedCausal unifies the local and global optimizations into a complete directed acyclic graph (DAG) learning process with a flexible optimization objective. We prove that this optimization objective has a high interpretability and can adaptively handle homogeneous and heterogeneous data. Experimental results on synthetic and real datasets show that FedCausal can effectively deal with non-independently and identically distributed (non-iid) data and has a superior performance.
Entire Space Cascade Delayed Feedback Modeling for Effective Conversion Rate Prediction
Aug 09, 2023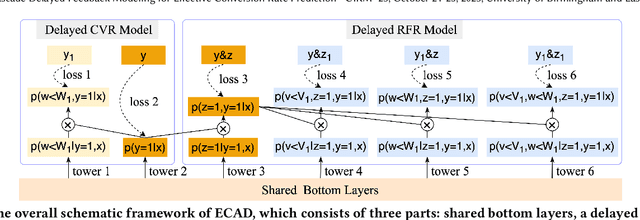
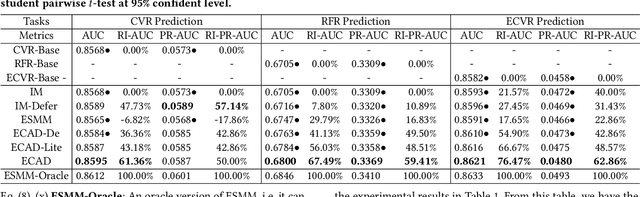
Conversion rate (CVR) prediction is an essential task for large-scale e-commerce platforms. However, refund behaviors frequently occur after conversion in online shopping systems, which drives us to pay attention to effective conversion for building healthier shopping services. This paper defines the probability of item purchasing without any subsequent refund as an effective conversion rate (ECVR). A simple paradigm for ECVR prediction is to decompose it into two sub-tasks: CVR prediction and post-conversion refund rate (RFR) prediction. However, RFR prediction suffers from data sparsity (DS) and sample selection bias (SSB) issues, as the refund behaviors are only available after user purchase. Furthermore, there is delayed feedback in both conversion and refund events and they are sequentially dependent, named cascade delayed feedback (CDF), which significantly harms data freshness for model training. Previous studies mainly focus on tackling DS and SSB or delayed feedback for a single event. To jointly tackle these issues in ECVR prediction, we propose an Entire space CAscade Delayed feedback modeling (ECAD) method. Specifically, ECAD deals with DS and SSB by constructing two tasks including CVR prediction and conversion \& refund rate (CVRFR) prediction using the entire space modeling framework. In addition, it carefully schedules auxiliary tasks to leverage both conversion and refund time within data to alleviate CDF. Experimental results on the offline industrial dataset and online A/B testing demonstrate the effectiveness of ECAD. In addition, ECAD has been deployed in one of the recommender systems in Alibaba, contributing to a significant improvement of ECVR.
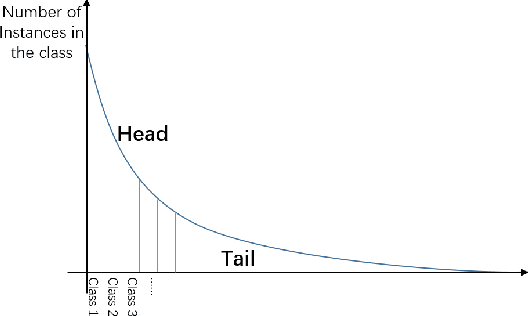
Long-tail Cross Modal Hashing
Nov 28, 2022



Existing Cross Modal Hashing (CMH) methods are mainly designed for balanced data, while imbalanced data with long-tail distribution is more general in real-world. Several long-tail hashing methods have been proposed but they can not adapt for multi-modal data, due to the complex interplay between labels and individuality and commonality information of multi-modal data. Furthermore, CMH methods mostly mine the commonality of multi-modal data to learn hash codes, which may override tail labels encoded by the individuality of respective modalities. In this paper, we propose LtCMH (Long-tail CMH) to handle imbalanced multi-modal data. LtCMH firstly adopts auto-encoders to mine the individuality and commonality of different modalities by minimizing the dependency between the individuality of respective modalities and by enhancing the commonality of these modalities. Then it dynamically combines the individuality and commonality with direct features extracted from respective modalities to create meta features that enrich the representation of tail labels, and binaries meta features to generate hash codes. LtCMH significantly outperforms state-of-the-art baselines on long-tail datasets and holds a better (or comparable) performance on datasets with balanced labels.
Reinforcement Causal Structure Learning on Order Graph
Nov 22, 2022



Learning directed acyclic graph (DAG) that describes the causality of observed data is a very challenging but important task. Due to the limited quantity and quality of observed data, and non-identifiability of causal graph, it is almost impossible to infer a single precise DAG. Some methods approximate the posterior distribution of DAGs to explore the DAG space via Markov chain Monte Carlo (MCMC), but the DAG space is over the nature of super-exponential growth, accurately characterizing the whole distribution over DAGs is very intractable. In this paper, we propose {Reinforcement Causal Structure Learning on Order Graph} (RCL-OG) that uses order graph instead of MCMC to model different DAG topological orderings and to reduce the problem size. RCL-OG first defines reinforcement learning with a new reward mechanism to approximate the posterior distribution of orderings in an efficacy way, and uses deep Q-learning to update and transfer rewards between nodes. Next, it obtains the probability transition model of nodes on order graph, and computes the posterior probability of different orderings. In this way, we can sample on this model to obtain the ordering with high probability. Experiments on synthetic and benchmark datasets show that RCL-OG provides accurate posterior probability approximation and achieves better results than competitive causal discovery algorithms.
MetaMIML: Meta Multi-Instance Multi-Label Learning
Nov 07, 2021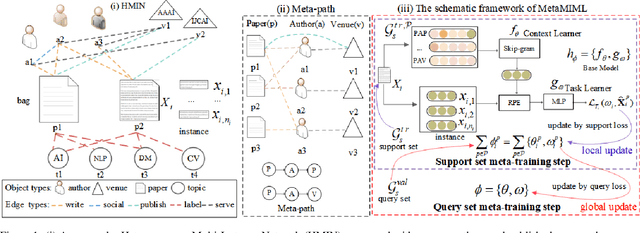
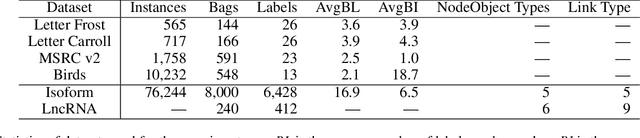
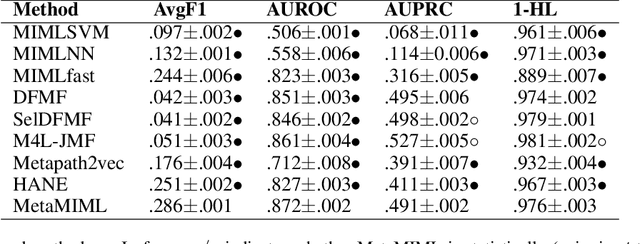

Multi-Instance Multi-Label learning (MIML) models complex objects (bags), each of which is associated with a set of interrelated labels and composed with a set of instances. Current MIML solutions still focus on a single-type of objects and assumes an IID distribution of training data. But these objects are linked with objects of other types, %(i.e., pictures in Facebook link with various users), which also encode the semantics of target objects. In addition, they generally need abundant labeled data for training. To effectively mine interdependent MIML objects of different types, we propose a network embedding and meta learning based approach (MetaMIML). MetaMIML introduces the context learner with network embedding to capture semantic information of objects of different types, and the task learner to extract the meta knowledge for fast adapting to new tasks. In this way, MetaMIML can naturally deal with MIML objects at data level improving, but also exploit the power of meta-learning at the model enhancing. Experiments on benchmark datasets demonstrate that MetaMIML achieves a significantly better performance than state-of-the-art algorithms.
Meta Cross-Modal Hashing on Long-Tailed Data
Nov 07, 2021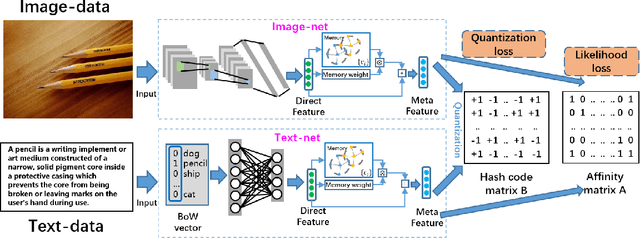
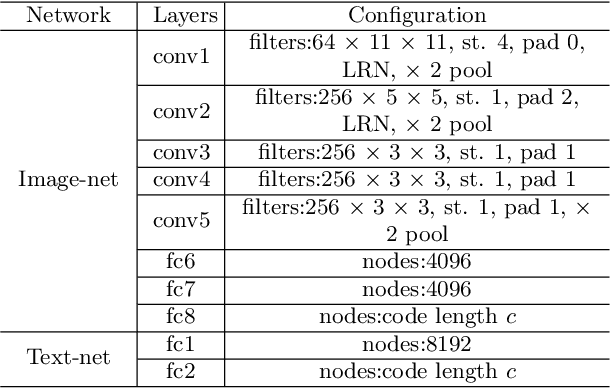

Due to the advantage of reducing storage while speeding up query time on big heterogeneous data, cross-modal hashing has been extensively studied for approximate nearest neighbor search of multi-modal data. Most hashing methods assume that training data is class-balanced.However, in practice, real world data often have a long-tailed distribution. In this paper, we introduce a meta-learning based cross-modal hashing method (MetaCMH) to handle long-tailed data. Due to the lack of training samples in the tail classes, MetaCMH first learns direct features from data in different modalities, and then introduces an associative memory module to learn the memory features of samples of the tail classes. It then combines the direct and memory features to obtain meta features for each sample. For samples of the head classes of the long tail distribution, the weight of the direct features is larger, because there are enough training data to learn them well; while for rare classes, the weight of the memory features is larger. Finally, MetaCMH uses a likelihood loss function to preserve the similarity in different modalities and learns hash functions in an end-to-end fashion. Experiments on long-tailed datasets show that MetaCMH performs significantly better than state-of-the-art methods, especially on the tail classes.