 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDOL: Meeting Diverse Distribution Shifts with Prior Physics for Tropical Cyclone Multi-Task Estimation
Nov 13, 2025



Tropical Cyclone (TC) estimation aims to accurately estimate various TC attributes in real time. However, distribution shifts arising from the complex and dynamic nature of TC environmental fields, such as varying geographical conditions and seasonal changes, present significant challenges to reliable estimation. Most existing methods rely on multi-modal fusion for feature extraction but overlook the intrinsic distribution of feature representations, leading to poor generalization under out-of-distribution (OOD) scenarios. To address this, we propose an effective Identity Distribution-Oriented Physical Invariant Learning framework (IDOL), which imposes identity-oriented constraints to regulate the feature space under the guidance of prior physical knowledge, thereby dealing distribution variability with physical invariance. Specifically, the proposed IDOL employs the wind field model and dark correlation knowledge of TC to model task-shared and task-specific identity tokens. These tokens capture task dependencies and intrinsic physical invariances of TC, enabling robust estimation of TC wind speed, pressure, inner-core, and outer-core size under distribution shifts. Extensive experiments conducted on multiple datasets and tasks demonstrate the outperformance of the proposed IDOL, verifying that imposing identity-oriented constraints based on prior physical knowledge can effectively mitigates diverse distribution shifts in TC estimation.Code is available at https://github.com/Zjut-MultimediaPlus/IDOL.
Single Image Reflection Removal via inter-layer Complementarity
May 19, 2025Although dual-stream architectures have achieved remarkable success in single image reflection removal, they fail to fully exploit inter-layer complementarity in their physical modeling and network design, which limits the quality of image separation. To address this fundamental limitation, we propose two targeted improvements to enhance dual-stream architectures: First, we introduce a novel inter-layer complementarity model where low-frequency components extracted from the residual layer interact with the transmission layer through dual-stream architecture to enhance inter-layer complementarity. Meanwhile, high-frequency components from the residual layer provide inverse modulation to both streams, improving the detail quality of the transmission layer. Second, we propose an efficient inter-layer complementarity attention mechanism which first cross-reorganizes dual streams at the channel level to obtain reorganized streams with inter-layer complementary structures, then performs attention computation on the reorganized streams to achieve better inter-layer separation, and finally restores the original stream structure for output. Experimental results demonstrate that our method achieves state-of-the-art separation quality on multiple public datasets while significantly reducing both computational cost and model complexity.
MetricGrids: Arbitrary Nonlinear Approximation with Elementary Metric Grids based Implicit Neural Representation
Mar 13, 2025
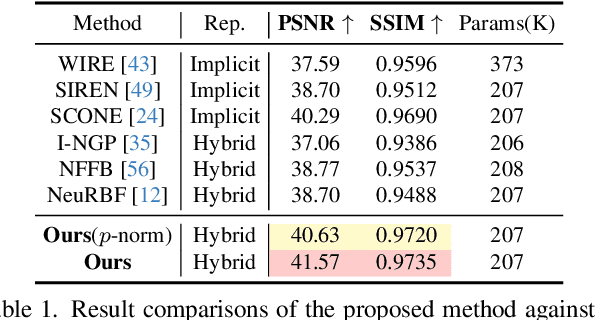

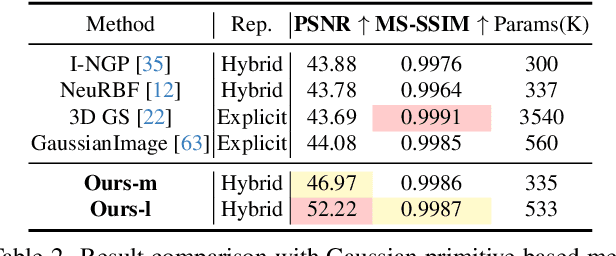
This paper presents MetricGrids, a novel grid-based neural representation that combines elementary metric grids in various metric spaces to approximate complex nonlinear signals. While grid-based representations are widely adopted for their efficiency and scalability, the existing feature grids with linear indexing for continuous-space points can only provide degenerate linear latent space representations, and such representations cannot be adequately compensated to represent complex nonlinear signals by the following compact decoder. To address this problem while keeping the simplicity of a regular grid structure, our approach builds upon the standard grid-based paradigm by constructing multiple elementary metric grids as high-order terms to approximate complex nonlinearities, following the Taylor expansion principle. Furthermore, we enhance model compactness with hash encoding based on different sparsities of the grids to prevent detrimental hash collisions, and a high-order extrapolation decoder to reduce explicit grid storage requirements. experimental results on both 2D and 3D reconstructions demonstrate the superior fitting and rendering accuracy of the proposed method across diverse signal types, validating its robustness and generalizability. Code is available at https://github.com/wangshu31/MetricGrids}{https://github.com/wangshu31/MetricGrids.
ViTGaze: Gaze Following with Interaction Features in Vision Transformers
Mar 19, 2024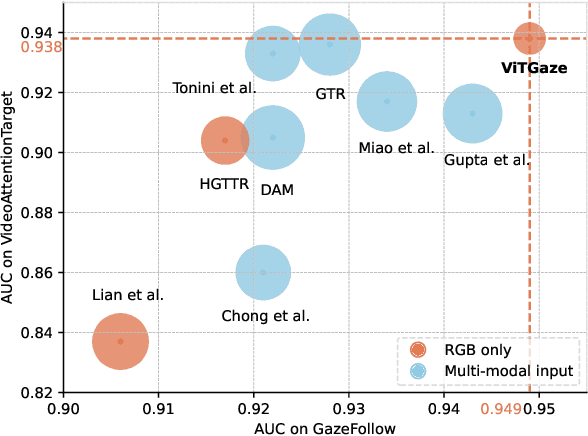

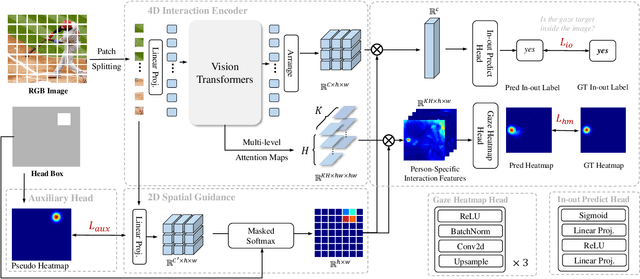

Gaze following aims to interpret human-scene interactions by predicting the person's focal point of gaze. Prevailing approaches often use multi-modality inputs, most of which adopt a two-stage framework. Hence their performance highly depends on the previous prediction accuracy. Others use a single-modality approach with complex decoders, increasing network computational load. Inspired by the remarkable success of pre-trained plain Vision Transformers (ViTs), we introduce a novel single-modality gaze following framework, ViTGaze. In contrast to previous methods, ViTGaze creates a brand new gaze following framework based mainly on powerful encoders (dec. param. less than 1%). Our principal insight lies in that the inter-token interactions within self-attention can be transferred to interactions between humans and scenes. Leveraging this presumption, we formulate a framework consisting of a 4D interaction encoder and a 2D spatial guidance module to extract human-scene interaction information from self-attention maps. Furthermore, our investigation reveals that ViT with self-supervised pre-training exhibits an enhanced ability to extract correlated information. A large number of experiments have been conducted to demonstrate the performance of the proposed method. Our method achieves state-of-the-art (SOTA) performance among all single-modality methods (3.4% improvement on AUC, 5.1% improvement on AP) and very comparable performance against multi-modality methods with 59% number of parameters less.
Federated Causality Learning with Explainable Adaptive Optimization
Dec 09, 2023



Discovering the causality from observational data is a crucial task in various scientific domains. With increasing awareness of privacy, data are not allowed to be exposed, and it is very hard to learn causal graphs from dispersed data, since these data may have different distributions. In this paper, we propose a federated causal discovery strategy (FedCausal) to learn the unified global causal graph from decentralized heterogeneous data. We design a global optimization formula to naturally aggregate the causal graphs from client data and constrain the acyclicity of the global graph without exposing local data. Unlike other federated causal learning algorithms, FedCausal unifies the local and global optimizations into a complete directed acyclic graph (DAG) learning process with a flexible optimization objective. We prove that this optimization objective has a high interpretability and can adaptively handle homogeneous and heterogeneous data. Experimental results on synthetic and real datasets show that FedCausal can effectively deal with non-independently and identically distributed (non-iid) data and has a superior performance.
ResDiff: Combining CNN and Diffusion Model for Image Super-Resolution
Mar 16, 2023



Adapting the Diffusion Probabilistic Model (DPM) for direct image super-resolution is wasteful, given that a simple Convolutional Neural Network (CNN) can recover the main low-frequency content. Therefore, we present ResDiff, a novel Diffusion Probabilistic Model based on Residual structure for Single Image Super-Resolution (SISR). ResDiff utilizes a combination of a CNN, which restores primary low-frequency components, and a DPM, which predicts the residual between the ground-truth image and the CNN-predicted image. In contrast to the common diffusion-based methods that directly use LR images to guide the noise towards HR space, ResDiff utilizes the CNN's initial prediction to direct the noise towards the residual space between HR space and CNN-predicted space, which not only accelerates the generation process but also acquires superior sample quality. Additionally, a frequency-domain-based loss function for CNN is introduced to facilitate its restoration, and a frequency-domain guided diffusion is designed for DPM on behalf of predicting high-frequency details. The extensive experiments on multiple benchmark datasets demonstrate that ResDiff outperforms previous diffusion-based methods in terms of shorter model convergence time, superior generation quality, and more diverse samples.
Long-tail Cross Modal Hashing
Nov 28, 2022



Existing Cross Modal Hashing (CMH) methods are mainly designed for balanced data, while imbalanced data with long-tail distribution is more general in real-world. Several long-tail hashing methods have been proposed but they can not adapt for multi-modal data, due to the complex interplay between labels and individuality and commonality information of multi-modal data. Furthermore, CMH methods mostly mine the commonality of multi-modal data to learn hash codes, which may override tail labels encoded by the individuality of respective modalities. In this paper, we propose LtCMH (Long-tail CMH) to handle imbalanced multi-modal data. LtCMH firstly adopts auto-encoders to mine the individuality and commonality of different modalities by minimizing the dependency between the individuality of respective modalities and by enhancing the commonality of these modalities. Then it dynamically combines the individuality and commonality with direct features extracted from respective modalities to create meta features that enrich the representation of tail labels, and binaries meta features to generate hash codes. LtCMH significantly outperforms state-of-the-art baselines on long-tail datasets and holds a better (or comparable) performance on datasets with balanced labels.
Codebook-Based Beam Tracking for Conformal ArrayEnabled UAV MmWave Networks
May 28, 2020
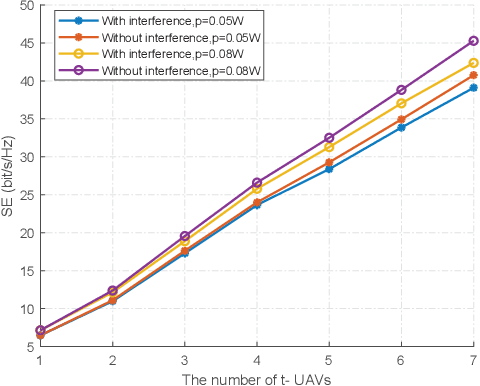

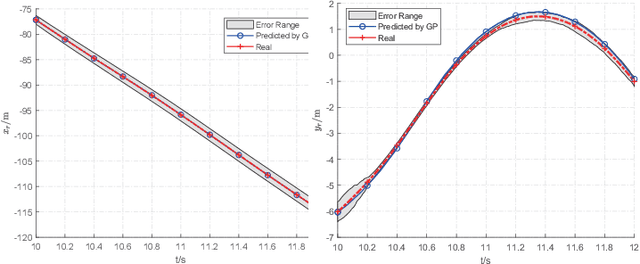
Millimeter wave (mmWave) communications can potentially meet the high data-rate requirements of unmanned aerial vehicle (UAV) networks. However, as the prerequisite of mmWave communications, the narrow directional beam tracking is very challenging because of the three-dimensional (3D) mobility and attitude variation of UAVs. Aiming to address the beam tracking difficulties, we propose to integrate the conformal array (CA) with the surface of each UAV, which enables the full spatial coverage and the agile beam tracking in highly dynamic UAV mmWave networks. More specifically, the key contributions of our work are three-fold. 1) A new mmWave beam tracking framework is established for the CA-enabled UAV mmWave network. 2) A specialized hierarchical codebook is constructed to drive the directional radiating element (DRE)-covered cylindrical conformal array (CCA), which contains both the angular beam pattern and the subarray pattern to fully utilize the potential of the CA. 3) A codebook-based multiuser beam tracking scheme is proposed, where the Gaussian process machine learning enabled UAV position/attitude predication is developed to improve the beam tracking efficiency in conjunction with the tracking-error aware adaptive beamwidth control. Simulation results validate the effectiveness of the proposed codebook-based beam tracking scheme in the CA-enabled UAV mmWave network, and demonstrate the advantages of CA over the conventional planner array in terms of spectrum efficiency and outage probability in the highly dynamic scenarios.