 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFT: From Imitation to Reward Fine-Tuning with Unbiased Group Advantages and Dynamic Coefficient Rectification
Apr 15, 2026Large language models are typically post-trained using supervised fine-tuning (SFT) and reinforcement learning (RL), yet effectively unifying efficient knowledge injection with robust generalization remains challenging. In this work, we provide a training-dynamics analysis showing that SFT can be interpreted as a special case of policy gradient optimization with an extremely sparse implicit reward and unstable inverse-probability weighting, which together lead to single-path dependency, entropy collapse, and gradient explosion. Motivated by this diagnosis, we propose Group Fine-Tuning (GFT), a unified post-training framework that addresses these intrinsic limitations through two mechanisms: Group Advantage Learning, which constructs diverse response groups and derives normalized contrastive supervision to alleviate reward sparsity, and Dynamic Coefficient Rectification, which adaptively bounds inverse-probability weights to stabilize optimization while preserving efficient knowledge injection. Experiments demonstrate that GFT consistently surpasses SFT-based methods and yields policies that integrate more smoothly with subsequent RL training.
SARE: Sample-wise Adaptive Reasoning for Training-free Fine-grained Visual Recognition
Mar 18, 2026Recent advances in Large Vision-Language Models (LVLMs) have enabled training-free Fine-Grained Visual Recognition (FGVR). However, effectively exploiting LVLMs for FGVR remains challenging due to the inherent visual ambiguity of subordinate-level categories. Existing methods predominantly adopt either retrieval-oriented or reasoning-oriented paradigms to tackle this challenge, but both are constrained by two fundamental limitations:(1) They apply the same inference pipeline to all samples without accounting for uneven recognition difficulty, thereby leading to suboptimal accuracy and efficiency; (2) The lack of mechanisms to consolidate and reuse error-specific experience causes repeated failures on similar challenging cases. To address these limitations, we propose SARE, a Sample-wise Adaptive textbfREasoning framework for training-free FGVR. Specifically, SARE adopts a cascaded design that combines fast candidate retrieval with fine-grained reasoning, invoking the latter only when necessary. In the reasoning process, SARE incorporates a self-reflective experience mechanism that leverages past failures to provide transferable discriminative guidance during inference, without any parameter updates. Extensive experiments across 14 datasets substantiate that SARE achieves state-of-the-art performance while substantially reducing computational overhead.
WebWeaver: Breaking Topology Confidentiality in LLM Multi-Agent Systems with Stealthy Context-Based Inference
Mar 11, 2026Communication topology is a critical factor in the utility and safety of LLM-based multi-agent systems (LLM-MAS), making it a high-value intellectual property (IP) whose confidentiality remains insufficiently studied. % Existing topology inference attempts rely on impractical assumptions, including control over the administrative agent and direct identity queries via jailbreaks, which are easily defeated by basic keyword-based defenses. As a result, prior analyses fail to capture the real-world threat of such attacks. % To bridge this realism gap, we propose \textit{WebWeaver}, an attack framework that infers the complete LLM-MAS topology by compromising only a single arbitrary agent instead of the administrative agent. % Unlike prior approaches, WebWeaver relies solely on agent contexts rather than agent IDs, enabling significantly stealthier inference. % WebWeaver further introduces a new covert jailbreak-based mechanism and a novel fully jailbreak-free diffusion design to handle cases where jailbreaks fail. % Additionally, we address a key challenge in diffusion-based inference by proposing a masking strategy that preserves known topology during diffusion, with theoretical guarantees of correctness. % Extensive experiments show that WebWeaver substantially outperforms state-of-the-art (SOTA) baselines, achieving about 60\% higher inference accuracy under active defenses with negligible overhead.
pFedNavi: Structure-Aware Personalized Federated Vision-Language Navigation for Embodied AI
Feb 16, 2026Vision-Language Navigation VLN requires large-scale trajectory instruction data from private indoor environments, raising significant privacy concerns. Federated Learning FL mitigates this by keeping data on-device, but vanilla FL struggles under VLNs' extreme cross-client heterogeneity in environments and instruction styles, making a single global model suboptimal. This paper proposes pFedNavi, a structure-aware and dynamically adaptive personalized federated learning framework tailored for VLN. Our key idea is to personalize where it matters: pFedNavi adaptively identifies client-specific layers via layer-wise mixing coefficients, and performs fine-grained parameter fusion on the selected components (e.g., the encoder-decoder projection and environment-sensitive decoder layers) to balance global knowledge sharing with local specialization. We evaluate pFedNavi on two standard VLN benchmarks, R2R and RxR, using both ResNet and CLIP visual representations. Across all metrics, pFedNavi consistently outperforms the FedAvg-based VLN baseline, achieving up to 7.5% improvement in navigation success rate and up to 7.8% gain in trajectory fidelity, while converging 1.38x faster under non-IID conditions.
Ground What You See: Hallucination-Resistant MLLMs via Caption Feedback, Diversity-Aware Sampling, and Conflict Regularization
Jan 13, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse tasks, their practical deployment is severely hindered by hallucination issues, which become particularly acute during Reinforcement Learning (RL) optimization. This paper systematically analyzes the root causes of hallucinations in MLLMs under RL training, identifying three critical factors: (1) an over-reliance on chained visual reasoning, where inaccurate initial descriptions or redundant information anchor subsequent inferences to incorrect premises; (2) insufficient exploration diversity during policy optimization, leading the model to generate overly confident but erroneous outputs; and (3) destructive conflicts between training samples, where Neural Tangent Kernel (NTK) similarity causes false associations and unstable parameter updates. To address these challenges, we propose a comprehensive framework comprising three core modules. First, we enhance visual localization by introducing dedicated planning and captioning stages before the reasoning phase, employing a quality-based caption reward to ensure accurate initial anchoring. Second, to improve exploration, we categorize samples based on the mean and variance of their reward distributions, prioritizing samples with high variance to focus the model on diverse and informative data. Finally, to mitigate sample interference, we regulate NTK similarity by grouping sample pairs and applying an InfoNCE loss to push overly similar pairs apart and pull dissimilar ones closer, thereby guiding gradient interactions toward a balanced range. Experimental results demonstrate that our proposed method significantly reduces hallucination rates and effectively enhances the inference accuracy of MLLMs.
Do Not Merge My Model! Safeguarding Open-Source LLMs Against Unauthorized Model Merging
Nov 13, 2025Model merging has emerged as an efficient technique for expanding large language models (LLMs) by integrating specialized expert models. However, it also introduces a new threat: model merging stealing, where free-riders exploit models through unauthorized model merging. Unfortunately, existing defense mechanisms fail to provide effective protection. Specifically, we identify three critical protection properties that existing methods fail to simultaneously satisfy: (1) proactively preventing unauthorized merging; (2) ensuring compatibility with general open-source settings; (3) achieving high security with negligible performance loss. To address the above issues, we propose MergeBarrier, a plug-and-play defense that proactively prevents unauthorized merging. The core design of MergeBarrier is to disrupt the Linear Mode Connectivity (LMC) between the protected model and its homologous counterparts, thereby eliminating the low-loss path required for effective model merging. Extensive experiments show that MergeBarrier effectively prevents model merging stealing with negligible accuracy loss.
RAGFort: Dual-Path Defense Against Proprietary Knowledge Base Extraction in Retrieval-Augmented Generation
Nov 13, 2025
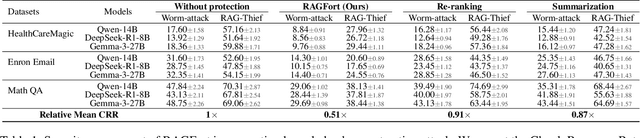
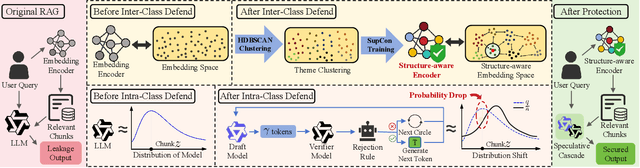
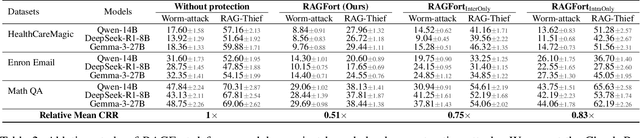
Retrieval-Augmented Generation (RAG) systems deployed over proprietary knowledge bases face growing threats from reconstruction attacks that aggregate model responses to replicate knowledge bases. Such attacks exploit both intra-class and inter-class paths, progressively extracting fine-grained knowledge within topics and diffusing it across semantically related ones, thereby enabling comprehensive extraction of the original knowledge base. However, existing defenses target only one path, leaving the other unprotected. We conduct a systematic exploration to assess the impact of protecting each path independently and find that joint protection is essential for effective defense. Based on this, we propose RAGFort, a structure-aware dual-module defense combining "contrastive reindexing" for inter-class isolation and "constrained cascade generation" for intra-class protection. Experiments across security, performance, and robustness confirm that RAGFort significantly reduces reconstruction success while preserving answer quality, offering comprehensive defense against knowledge base extraction attacks.
iSeal: Encrypted Fingerprinting for Reliable LLM Ownership Verification
Nov 12, 2025Given the high cost of large language model (LLM) training from scratch, safeguarding LLM intellectual property (IP) has become increasingly crucial. As the standard paradigm for IP ownership verification, LLM fingerprinting thus plays a vital role in addressing this challenge. Existing LLM fingerprinting methods verify ownership by extracting or injecting model-specific features. However, they overlook potential attacks during the verification process, leaving them ineffective when the model thief fully controls the LLM's inference process. In such settings, attackers may share prompt-response pairs to enable fingerprint unlearning or manipulate outputs to evade exact-match verification. We propose iSeal, the first fingerprinting method designed for reliable verification when the model thief controls the suspected LLM in an end-to-end manner. It injects unique features into both the model and an external module, reinforced by an error-correction mechanism and a similarity-based verification strategy. These components are resistant to verification-time attacks, including collusion-based fingerprint unlearning and response manipulation, backed by both theoretical analysis and empirical results. iSeal achieves 100 percent Fingerprint Success Rate (FSR) on 12 LLMs against more than 10 attacks, while baselines fail under unlearning and response manipulations.
EchoMark: Perceptual Acoustic Environment Transfer with Watermark-Embedded Room Impulse Response
Nov 09, 2025Acoustic Environment Matching (AEM) is the task of transferring clean audio into a target acoustic environment, enabling engaging applications such as audio dubbing and auditory immersive virtual reality (VR). Recovering similar room impulse response (RIR) directly from reverberant speech offers more accessible and flexible AEM solution. However, this capability also introduces vulnerabilities of arbitrary ``relocation" if misused by malicious user, such as facilitating advanced voice spoofing attacks or undermining the authenticity of recorded evidence. To address this issue, we propose EchoMark, the first deep learning-based AEM framework that generates perceptually similar RIRs with embedded watermark. Our design tackle the challenges posed by variable RIR characteristics, such as different durations and energy decays, by operating in the latent domain. By jointly optimizing the model with a perceptual loss for RIR reconstruction and a loss for watermark detection, EchoMark achieves both high-quality environment transfer and reliable watermark recovery. Experiments on diverse datasets validate that EchoMark achieves room acoustic parameter matching performance comparable to FiNS, the state-of-the-art RIR estimator. Furthermore, a high Mean Opinion Score (MOS) of 4.22 out of 5, watermark detection accuracy exceeding 99\%, and bit error rates (BER) below 0.3\% collectively demonstrate the effectiveness of EchoMark in preserving perceptual quality while ensuring reliable watermark embedding.
PAE MobiLLM: Privacy-Aware and Efficient LLM Fine-Tuning on the Mobile Device via Additive Side-Tuning
Jul 01, 2025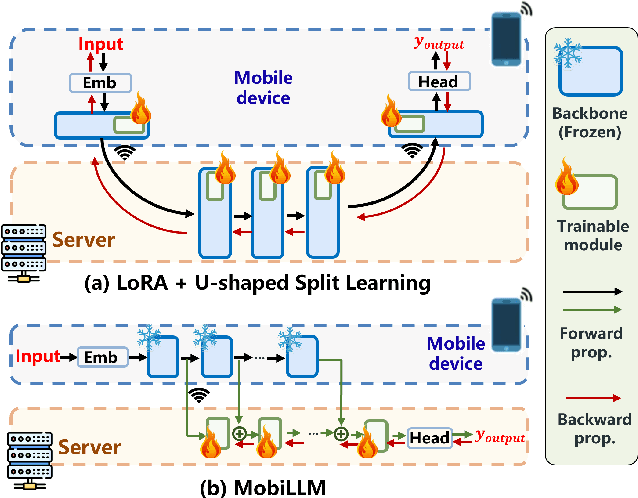
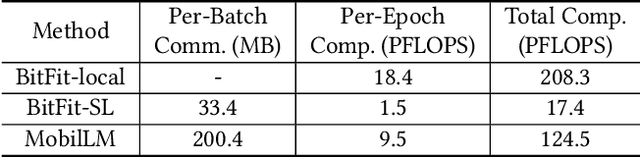
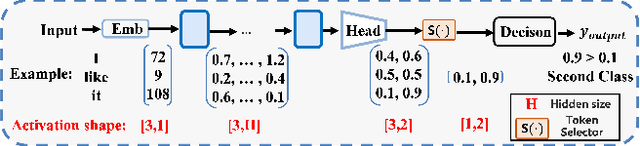
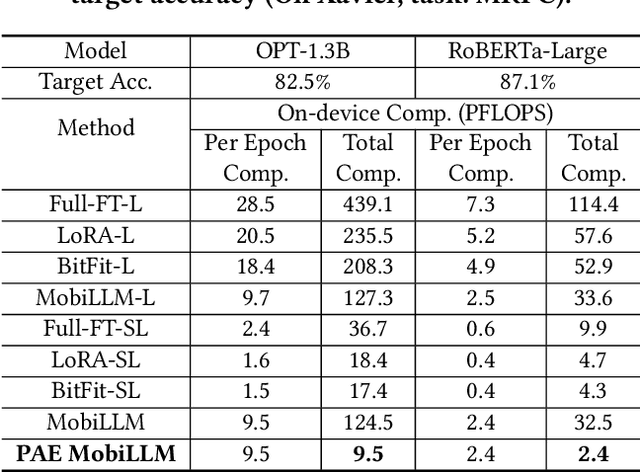
There is a huge gap between numerous intriguing applications fostered by on-device large language model (LLM) fine-tuning (FT) from fresh mobile data and the limited resources of a mobile device. While existing server-assisted methods (e.g., split learning or side-tuning) may enable LLM FT on the local mobile device, they suffer from heavy communication burdens of activation transmissions, and may disclose data, labels or fine-tuned models to the server. To address those issues, we develop PAE MobiLLM, a privacy-aware and efficient LLM FT method which can be deployed on the mobile device via server-assisted additive side-tuning. To further accelerate FT convergence and improve computing efficiency, PAE MobiLLM integrates activation caching on the server side, which allows the server to reuse historical activations and saves the mobile device from repeatedly computing forward passes for the recurring data samples. Besides, to reduce communication cost, PAE MobiLLM develops a one-token (i.e., ``pivot'' token) activation shortcut that transmits only a single activation dimension instead of full activation matrices to guide the side network tuning. Last but not least, PAE MobiLLM introduces the additive adapter side-network design which makes the server train the adapter modules based on device-defined prediction differences rather than raw ground-truth labels. In this way, the server can only assist device-defined side-network computing, and learn nothing about data, labels or fine-tuned models.