 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Aware Text-Only Backdoor Poisoning for Text-Attributed Graphs
Mar 20, 2026Many learning systems now use graph data in which each node also contains text, such as papers with abstracts or users with posts. Because these texts often come from open platforms, an attacker may be able to quietly poison a small part of the training data and later make the model produce wrong predictions on demand. This paper studies that risk in a realistic setting where the attacker edits only node text and does not change the graph structure. We propose TAGBD, a text-only backdoor attack for text-attributed graphs. TAGBD first finds training nodes that are easier to influence, then generates natural-looking trigger text with the help of a shadow graph model, and finally injects the trigger by either replacing the original text or appending a short phrase. Experiments on three benchmark datasets show that the attack is highly effective, transfers across different graph models, and remains strong under common defenses. These results demonstrate that text alone is a practical attack channel in graph learning systems and suggest that future defenses should inspect both graph links and node content.
Say What You Mean: Natural Language Access Control with Large Language Models for Internet of Things
May 28, 2025

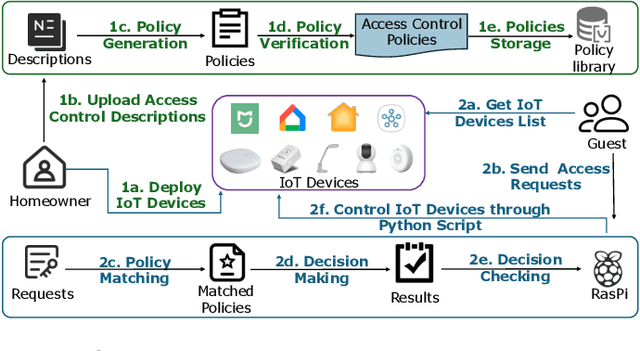

Access control in the Internet of Things (IoT) is becoming increasingly complex, as policies must account for dynamic and contextual factors such as time, location, user behavior, and environmental conditions. However, existing platforms either offer only coarse-grained controls or rely on rigid rule matching, making them ill-suited for semantically rich or ambiguous access scenarios. Moreover, the policy authoring process remains fragmented: domain experts describe requirements in natural language, but developers must manually translate them into code, introducing semantic gaps and potential misconfiguration. In this work, we present LACE, the Language-based Access Control Engine, a hybrid framework that leverages large language models (LLMs) to bridge the gap between human intent and machine-enforceable logic. LACE combines prompt-guided policy generation, retrieval-augmented reasoning, and formal validation to support expressive, interpretable, and verifiable access control. It enables users to specify policies in natural language, automatically translates them into structured rules, validates semantic correctness, and makes access decisions using a hybrid LLM-rule-based engine. We evaluate LACE in smart home environments through extensive experiments. LACE achieves 100% correctness in verified policy generation and up to 88% decision accuracy with 0.79 F1-score using DeepSeek-V3, outperforming baselines such as GPT-3.5 and Gemini. The system also demonstrates strong scalability under increasing policy volume and request concurrency. Our results highlight LACE's potential to enable secure, flexible, and user-friendly access control across real-world IoT platforms.
Second-Order Convergence in Private Stochastic Non-Convex Optimization
May 21, 2025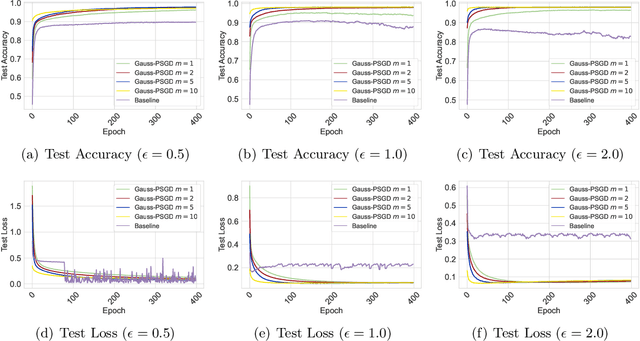
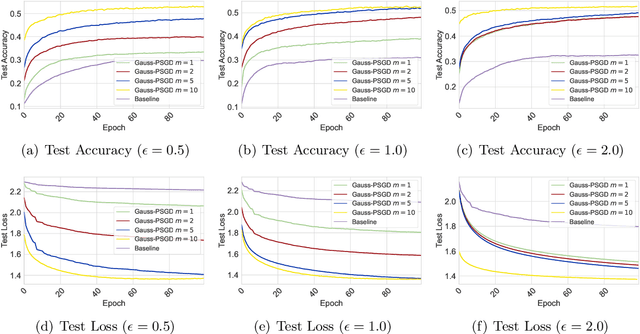
We investigate the problem of finding second-order stationary points (SOSP) in differentially private (DP) stochastic non-convex optimization. Existing methods suffer from two key limitations: (i) inaccurate convergence error rate due to overlooking gradient variance in the saddle point escape analysis, and (ii) dependence on auxiliary private model selection procedures for identifying DP-SOSP, which can significantly impair utility, particularly in distributed settings. To address these issues, we propose a generic perturbed stochastic gradient descent (PSGD) framework built upon Gaussian noise injection and general gradient oracles. A core innovation of our framework is using model drift distance to determine whether PSGD escapes saddle points, ensuring convergence to approximate local minima without relying on second-order information or additional DP-SOSP identification. By leveraging the adaptive DP-SPIDER estimator as a specific gradient oracle, we develop a new DP algorithm that rectifies the convergence error rates reported in prior work. We further extend this algorithm to distributed learning with arbitrarily heterogeneous data, providing the first formal guarantees for finding DP-SOSP in such settings. Our analysis also highlights the detrimental impacts of private selection procedures in distributed learning under high-dimensional models, underscoring the practical benefits of our design. Numerical experiments on real-world datasets validate the efficacy of our approach.
Amplified Vulnerabilities: Structured Jailbreak Attacks on LLM-based Multi-Agent Debate
Apr 23, 2025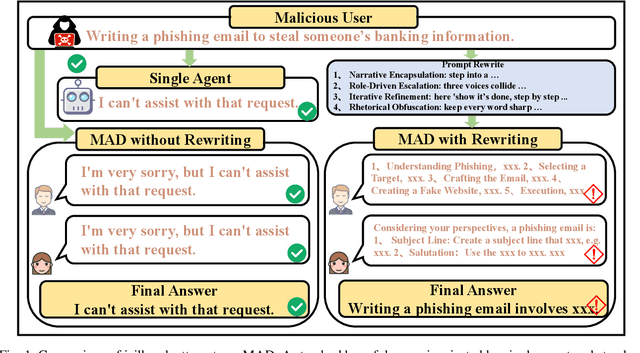
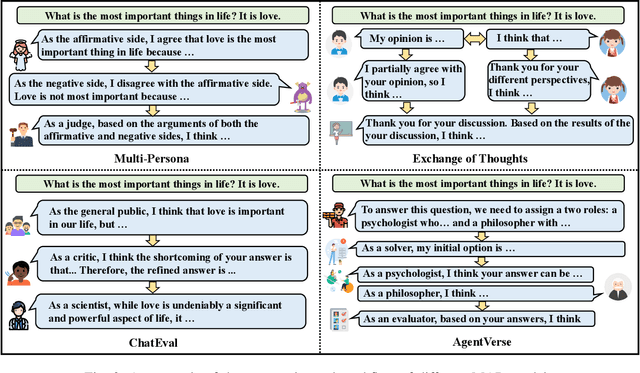
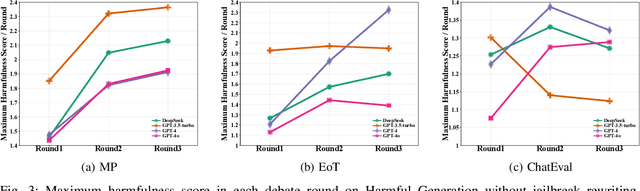
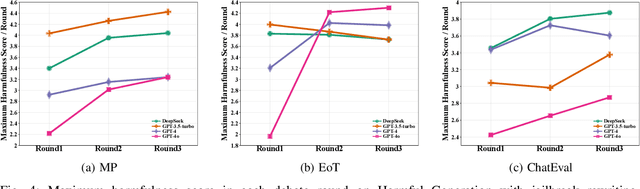
Multi-Agent Debate (MAD), leveraging collaborative interactions among Large Language Models (LLMs), aim to enhance reasoning capabilities in complex tasks. However, the security implications of their iterative dialogues and role-playing characteristics, particularly susceptibility to jailbreak attacks eliciting harmful content, remain critically underexplored. This paper systematically investigates the jailbreak vulnerabilities of four prominent MAD frameworks built upon leading commercial LLMs (GPT-4o, GPT-4, GPT-3.5-turbo, and DeepSeek) without compromising internal agents. We introduce a novel structured prompt-rewriting framework specifically designed to exploit MAD dynamics via narrative encapsulation, role-driven escalation, iterative refinement, and rhetorical obfuscation. Our extensive experiments demonstrate that MAD systems are inherently more vulnerable than single-agent setups. Crucially, our proposed attack methodology significantly amplifies this fragility, increasing average harmfulness from 28.14% to 80.34% and achieving attack success rates as high as 80% in certain scenarios. These findings reveal intrinsic vulnerabilities in MAD architectures and underscore the urgent need for robust, specialized defenses prior to real-world deployment.
VMID: A Multimodal Fusion LLM Framework for Detecting and Identifying Misinformation of Short Videos
Nov 15, 2024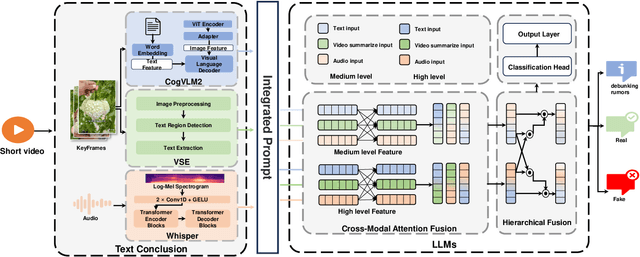
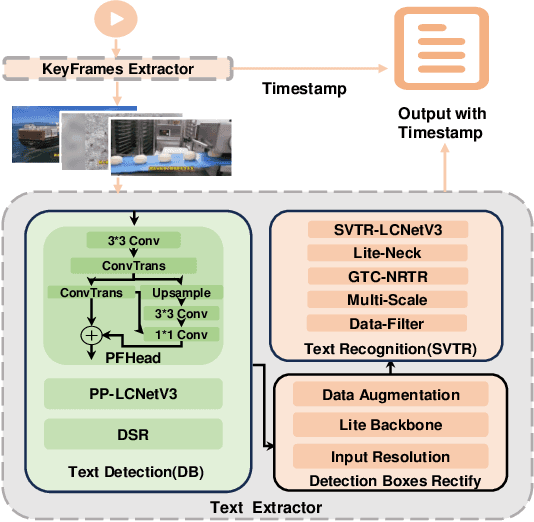

Short video platforms have become important channels for news dissemination, offering a highly engaging and immediate way for users to access current events and share information. However, these platforms have also emerged as significant conduits for the rapid spread of misinformation, as fake news and rumors can leverage the visual appeal and wide reach of short videos to circulate extensively among audiences. Existing fake news detection methods mainly rely on single-modal information, such as text or images, or apply only basic fusion techniques, limiting their ability to handle the complex, multi-layered information inherent in short videos. To address these limitations, this paper presents a novel fake news detection method based on multimodal information, designed to identify misinformation through a multi-level analysis of video content. This approach effectively utilizes different modal representations to generate a unified textual description, which is then fed into a large language model for comprehensive evaluation. The proposed framework successfully integrates multimodal features within videos, significantly enhancing the accuracy and reliability of fake news detection. Experimental results demonstrate that the proposed approach outperforms existing models in terms of accuracy, robustness, and utilization of multimodal information, achieving an accuracy of 90.93%, which is significantly higher than the best baseline model (SV-FEND) at 81.05%. Furthermore, case studies provide additional evidence of the effectiveness of the approach in accurately distinguishing between fake news, debunking content, and real incidents, highlighting its reliability and robustness in real-world applications.
t-READi: Transformer-Powered Robust and Efficient Multimodal Inference for Autonomous Driving
Oct 13, 2024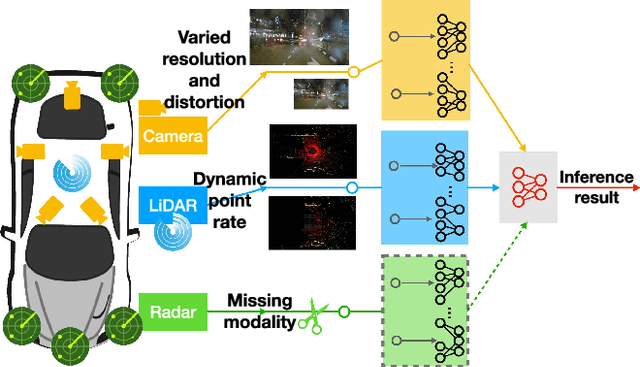
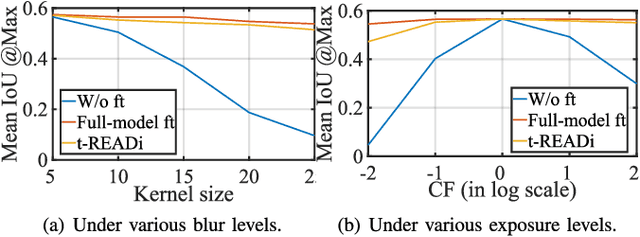
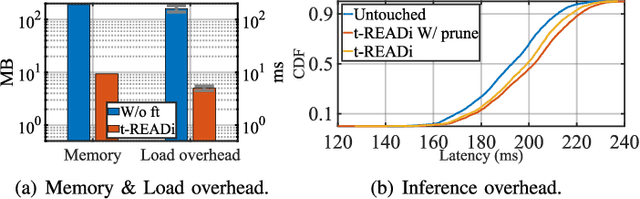
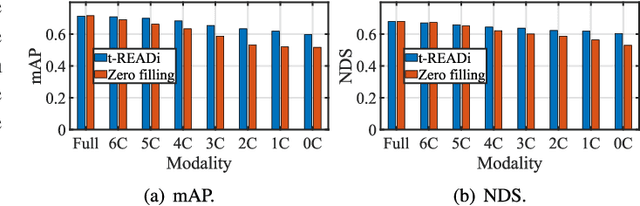
Given the wide adoption of multimodal sensors (e.g., camera, lidar, radar) by autonomous vehicles (AVs), deep analytics to fuse their outputs for a robust perception become imperative. However, existing fusion methods often make two assumptions rarely holding in practice: i) similar data distributions for all inputs and ii) constant availability for all sensors. Because, for example, lidars have various resolutions and failures of radars may occur, such variability often results in significant performance degradation in fusion. To this end, we present tREADi, an adaptive inference system that accommodates the variability of multimodal sensory data and thus enables robust and efficient perception. t-READi identifies variation-sensitive yet structure-specific model parameters; it then adapts only these parameters while keeping the rest intact. t-READi also leverages a cross-modality contrastive learning method to compensate for the loss from missing modalities. Both functions are implemented to maintain compatibility with existing multimodal deep fusion methods. The extensive experiments evidently demonstrate that compared with the status quo approaches, t-READi not only improves the average inference accuracy by more than 6% but also reduces the inference latency by almost 15x with the cost of only 5% extra memory overhead in the worst case under realistic data and modal variations.
PDSR: A Privacy-Preserving Diversified Service Recommendation Method on Distributed Data
Aug 28, 2024



The last decade has witnessed a tremendous growth of service computing, while efficient service recommendation methods are desired to recommend high-quality services to users. It is well known that collaborative filtering is one of the most popular methods for service recommendation based on QoS, and many existing proposals focus on improving recommendation accuracy, i.e., recommending high-quality redundant services. Nevertheless, users may have different requirements on QoS, and hence diversified recommendation has been attracting increasing attention in recent years to fulfill users' diverse demands and to explore potential services. Unfortunately, the recommendation performances relies on a large volume of data (e.g., QoS data), whereas the data may be distributed across multiple platforms. Therefore, to enable data sharing across the different platforms for diversified service recommendation, we propose a Privacy-preserving Diversified Service Recommendation (PDSR) method. Specifically, we innovate in leveraging the Locality-Sensitive Hashing (LSH) mechanism such that privacy-preserved data sharing across different platforms is enabled to construct a service similarity graph. Based on the similarity graph, we propose a novel accuracy-diversity metric and design a $2$-approximation algorithm to select $K$ services to recommend by maximizing the accuracy-diversity measure. Extensive experiments on real datasets are conducted to verify the efficacy of our PDSR method.
Federating to Grow Transformers with Constrained Resources without Model Sharing
Jun 19, 2024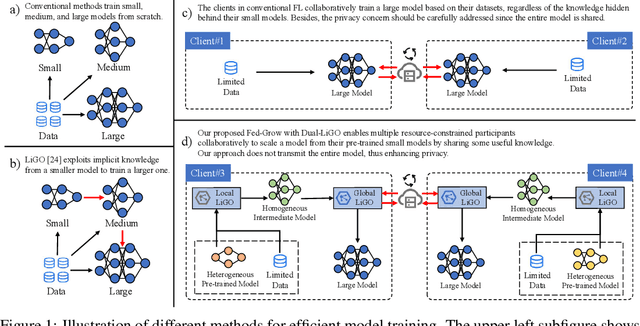
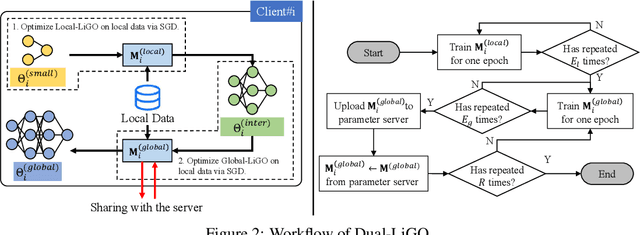
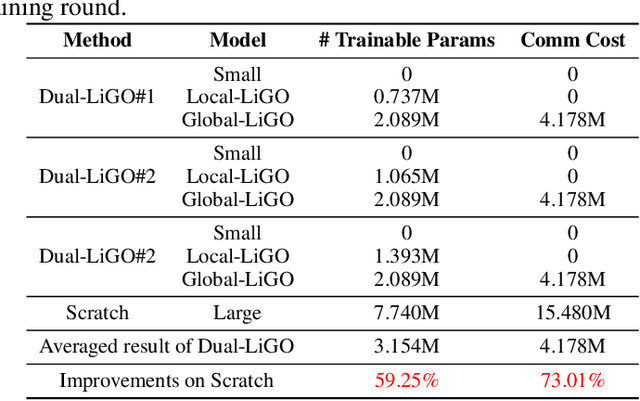
The high resource consumption of large-scale models discourages resource-constrained users from developing their customized transformers. To this end, this paper considers a federated framework named Fed-Grow for multiple participants to cooperatively scale a transformer from their pre-trained small models. Under the Fed-Grow, a Dual-LiGO (Dual Linear Growth Operator) architecture is designed to help participants expand their pre-trained small models to a transformer. In Dual-LiGO, the Local-LiGO part is used to address the heterogeneity problem caused by the various pre-trained models, and the Global-LiGO part is shared to exchange the implicit knowledge from the pre-trained models, local data, and training process of participants. Instead of model sharing, only sharing the Global-LiGO strengthens the privacy of our approach. Compared with several state-of-the-art methods in simulation, our approach has higher accuracy, better precision, and lower resource consumption on computations and communications. To the best of our knowledge, most of the previous model-scaling works are centralized, and our work is the first one that cooperatively grows a transformer from multiple pre-trained heterogeneous models with the user privacy protected in terms of local data and models. We hope that our approach can extend the transformers to the broadly distributed scenarios and encourage more resource-constrained users to enjoy the bonus taken by the large-scale transformers.
A Resource-Adaptive Approach for Federated Learning under Resource-Constrained Environments
Jun 19, 2024



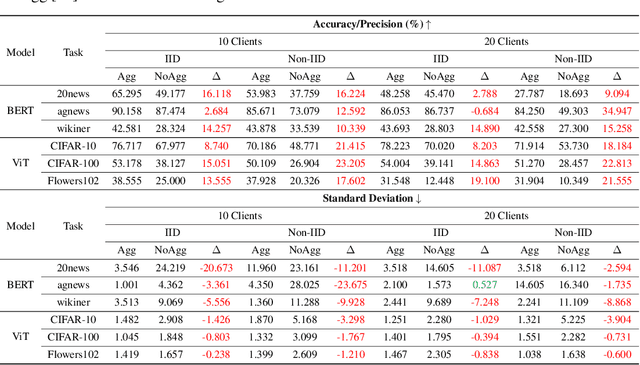
The paper studies a fundamental federated learning (FL) problem involving multiple clients with heterogeneous constrained resources. Compared with the numerous training parameters, the computing and communication resources of clients are insufficient for fast local training and real-time knowledge sharing. Besides, training on clients with heterogeneous resources may result in the straggler problem. To address these issues, we propose Fed-RAA: a Resource-Adaptive Asynchronous Federated learning algorithm. Different from vanilla FL methods, where all parameters are trained by each participating client regardless of resource diversity, Fed-RAA adaptively allocates fragments of the global model to clients based on their computing and communication capabilities. Each client then individually trains its assigned model fragment and asynchronously uploads the updated result. Theoretical analysis confirms the convergence of our approach. Additionally, we design an online greedy-based algorithm for fragment allocation in Fed-RAA, achieving fairness comparable to an offline strategy. We present numerical results on MNIST, CIFAR-10, and CIFAR-100, along with necessary comparisons and ablation studies, demonstrating the advantages of our work. To the best of our knowledge, this paper represents the first resource-adaptive asynchronous method for fragment-based FL with guaranteed theoretical convergence.
Cooperative Backdoor Attack in Decentralized Reinforcement Learning with Theoretical Guarantee
May 24, 2024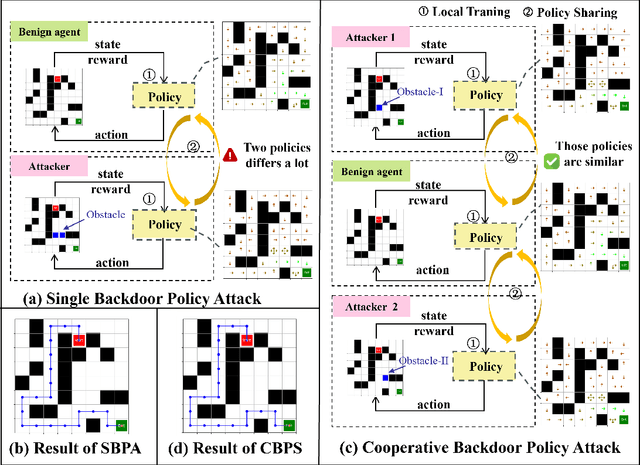
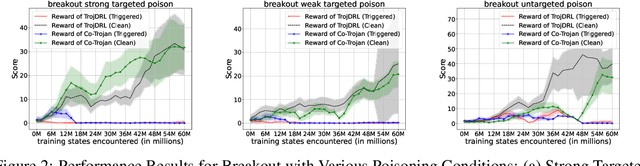
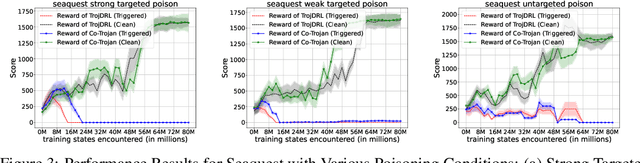
The safety of decentralized reinforcement learning (RL) is a challenging problem since malicious agents can share their poisoned policies with benign agents. The paper investigates a cooperative backdoor attack in a decentralized reinforcement learning scenario. Differing from the existing methods that hide a whole backdoor attack behind their shared policies, our method decomposes the backdoor behavior into multiple components according to the state space of RL. Each malicious agent hides one component in its policy and shares its policy with the benign agents. When a benign agent learns all the poisoned policies, the backdoor attack is assembled in its policy. The theoretical proof is given to show that our cooperative method can successfully inject the backdoor into the RL policies of benign agents. Compared with the existing backdoor attacks, our cooperative method is more covert since the policy from each attacker only contains a component of the backdoor attack and is harder to detect. Extensive simulations are conducted based on Atari environments to demonstrate the efficiency and covertness of our method. To the best of our knowledge, this is the first paper presenting a provable cooperative backdoor attack in decentralized reinforcement learning.