 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAD-Bench: A Comprehensive Benchmark for Embedding-Based Text Anomaly Detection
Jan 21, 2025



Text anomaly detection is crucial for identifying spam, misinformation, and offensive language in natural language processing tasks. Despite the growing adoption of embedding-based methods, their effectiveness and generalizability across diverse application scenarios remain under-explored. To address this, we present TAD-Bench, a comprehensive benchmark designed to systematically evaluate embedding-based approaches for text anomaly detection. TAD-Bench integrates multiple datasets spanning different domains, combining state-of-the-art embeddings from large language models with a variety of anomaly detection algorithms. Through extensive experiments, we analyze the interplay between embeddings and detection methods, uncovering their strengths, weaknesses, and applicability to different tasks. These findings offer new perspectives on building more robust, efficient, and generalizable anomaly detection systems for real-world applications.
DapperFL: Domain Adaptive Federated Learning with Model Fusion Pruning for Edge Devices
Dec 08, 2024Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data. In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a realworld FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to 2.28%, while significantly achieving model volume reductions ranging from 20% to 80%. Our code is available at: https://github.com/jyzgh/DapperFL.
PDSR: A Privacy-Preserving Diversified Service Recommendation Method on Distributed Data
Aug 28, 2024



The last decade has witnessed a tremendous growth of service computing, while efficient service recommendation methods are desired to recommend high-quality services to users. It is well known that collaborative filtering is one of the most popular methods for service recommendation based on QoS, and many existing proposals focus on improving recommendation accuracy, i.e., recommending high-quality redundant services. Nevertheless, users may have different requirements on QoS, and hence diversified recommendation has been attracting increasing attention in recent years to fulfill users' diverse demands and to explore potential services. Unfortunately, the recommendation performances relies on a large volume of data (e.g., QoS data), whereas the data may be distributed across multiple platforms. Therefore, to enable data sharing across the different platforms for diversified service recommendation, we propose a Privacy-preserving Diversified Service Recommendation (PDSR) method. Specifically, we innovate in leveraging the Locality-Sensitive Hashing (LSH) mechanism such that privacy-preserved data sharing across different platforms is enabled to construct a service similarity graph. Based on the similarity graph, we propose a novel accuracy-diversity metric and design a $2$-approximation algorithm to select $K$ services to recommend by maximizing the accuracy-diversity measure. Extensive experiments on real datasets are conducted to verify the efficacy of our PDSR method.
OptIForest: Optimal Isolation Forest for Anomaly Detection
Jun 23, 2023
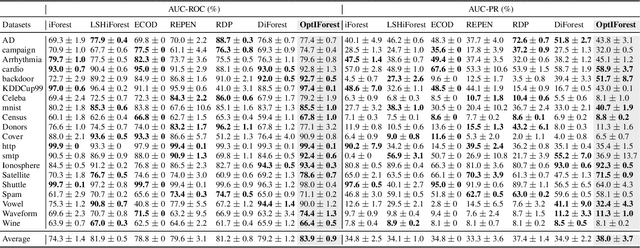
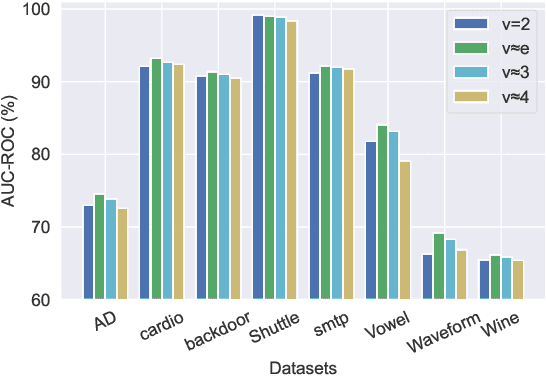
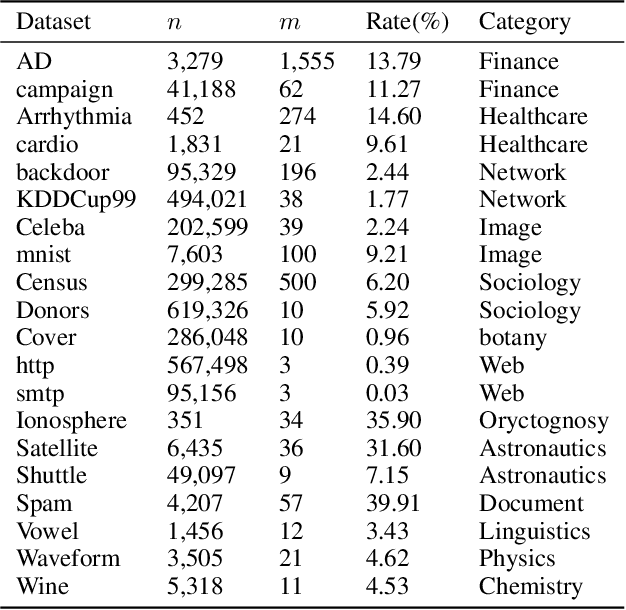
Anomaly detection plays an increasingly important role in various fields for critical tasks such as intrusion detection in cybersecurity, financial risk detection, and human health monitoring. A variety of anomaly detection methods have been proposed, and a category based on the isolation forest mechanism stands out due to its simplicity, effectiveness, and efficiency, e.g., iForest is often employed as a state-of-the-art detector for real deployment. While the majority of isolation forests use the binary structure, a framework LSHiForest has demonstrated that the multi-fork isolation tree structure can lead to better detection performance. However, there is no theoretical work answering the fundamentally and practically important question on the optimal tree structure for an isolation forest with respect to the branching factor. In this paper, we establish a theory on isolation efficiency to answer the question and determine the optimal branching factor for an isolation tree. Based on the theoretical underpinning, we design a practical optimal isolation forest OptIForest incorporating clustering based learning to hash which enables more information to be learned from data for better isolation quality. The rationale of our approach relies on a better bias-variance trade-off achieved by bias reduction in OptIForest. Extensive experiments on a series of benchmarking datasets for comparative and ablation studies demonstrate that our approach can efficiently and robustly achieve better detection performance in general than the state-of-the-arts including the deep learning based methods.
Intrinsically Motivated Reinforcement Learning based Recommendation with Counterfactual Data Augmentation
Sep 17, 2022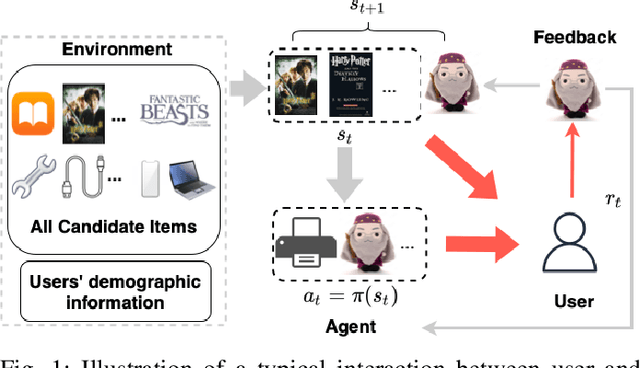
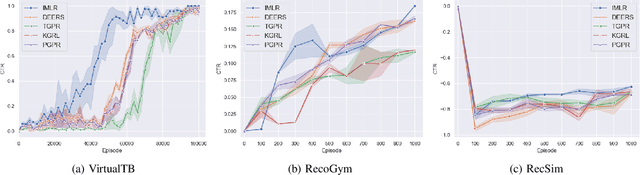
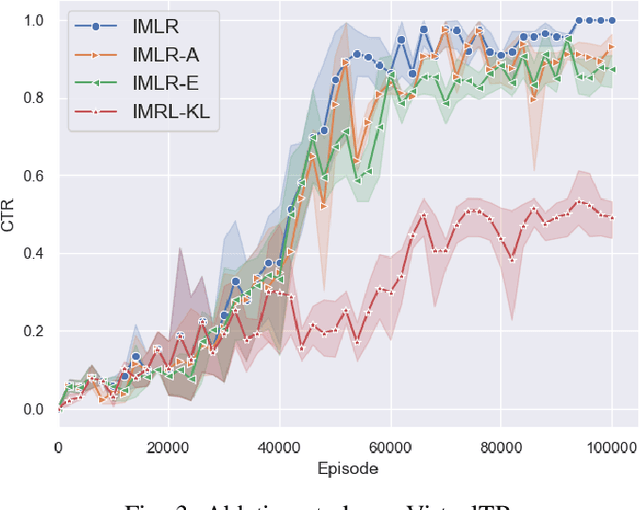
Deep reinforcement learning (DRL) has been proven its efficiency in capturing users' dynamic interests in recent literature. However, training a DRL agent is challenging, because of the sparse environment in recommender systems (RS), DRL agents could spend times either exploring informative user-item interaction trajectories or using existing trajectories for policy learning. It is also known as the exploration and exploitation trade-off which affects the recommendation performance significantly when the environment is sparse. It is more challenging to balance the exploration and exploitation in DRL RS where RS agent need to deeply explore the informative trajectories and exploit them efficiently in the context of recommender systems. As a step to address this issue, We design a novel intrinsically ,otivated reinforcement learning method to increase the capability of exploring informative interaction trajectories in the sparse environment, which are further enriched via a counterfactual augmentation strategy for more efficient exploitation. The extensive experiments on six offline datasets and three online simulation platforms demonstrate the superiority of our model to a set of existing state-of-the-art methods.
Diversity-aware Web APIs Recommendation with Compatibility Guarantee
Aug 10, 2021



With the ever-increasing prevalence of web APIs (Application Programming Interfaces) in enabling smart software developments, finding and composing a list of existing web APIs that can corporately fulfil the software developers' functional needs have become a promising way to develop a successful mobile app, economically and conveniently. However, the big volume and diversity of candidate web APIs put additional burden on the app developers' web APIs selection decision-makings, since it is often a challenging task to simultaneously guarantee the diversity and compatibility of the finally selected a set of web APIs. Considering this challenge, a Diversity-aware and Compatibility-driven web APIs Recommendation approach, namely DivCAR, is put forward in this paper. First, to achieve diversity, DivCAR employs random walk sampling technique on a pre-built correlation graph to generate diverse correlation subgraphs. Afterwards, with the diverse correlation subgraphs, we model the compatible web APIs recommendation problem to be a minimum group Steiner tree search problem. Through solving the minimum group Steiner tree search problem, manifold sets of compatible and diverse web APIs ranked are returned to the app developers. At last, we design and enact a set of experiments on a real-world dataset crawled from www.programmableWeb.com. Experimental results validate the effectiveness and efficiency of our proposed DivCAR approach in balancing the web APIs recommendation diversity and compatibility.