 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Text-Guided Brain Tumor Segmentation via Sub-Region-Aware Prompts
Mar 22, 2026Brain tumor segmentation remains challenging because the three standard sub-regions, i.e., whole tumor (WT), tumor core (TC), and enhancing tumor (ET), often exhibit ambiguous visual boundaries. Integrating radiological description texts with imaging has shown promise. However, most multimodal approaches typically compress a report into a single global text embedding shared across all sub-regions, overlooking their distinct clinical characteristics. We propose TextCSP (text-modulated soft cascade architecture), a hierarchical text-guided framework that builds on the TextBraTS baseline with three novel components: (1) a text-modulated soft cascade decoder that predicts WT->TC->ET in a coarse-to-fine manner consistent with their anatomical containment hierarchy. (2) sub-region-aware prompt tuning, which uses learnable soft prompts with a LoRA-adapted BioBERT encoder to generate specialized text representations tailored for each sub-region; (3) text-semantic channel modulators that convert the aforementioned representations into channel-wise refinement signals, enabling the decoder to emphasize features aligned with clinically described patterns. Experiments on the TextBraTS dataset demonstrate consistent improvements across all sub-regions against state-of-the-art methods by 1.7% and 6% on the main metrics Dice and HD95.
MTP: Exploring Multimodal Urban Traffic Profiling with Modality Augmentation and Spectrum Fusion
Nov 17, 2025With rapid urbanization in the modern era, traffic signals from various sensors have been playing a significant role in monitoring the states of cities, which provides a strong foundation in ensuring safe travel, reducing traffic congestion and optimizing urban mobility. Most existing methods for traffic signal modeling often rely on the original data modality, i.e., numerical direct readings from the sensors in cities. However, this unimodal approach overlooks the semantic information existing in multimodal heterogeneous urban data in different perspectives, which hinders a comprehensive understanding of traffic signals and limits the accurate prediction of complex traffic dynamics. To address this problem, we propose a novel Multimodal framework, MTP, for urban Traffic Profiling, which learns multimodal features through numeric, visual, and textual perspectives. The three branches drive for a multimodal perspective of urban traffic signal learning in the frequency domain, while the frequency learning strategies delicately refine the information for extraction. Specifically, we first conduct the visual augmentation for the traffic signals, which transforms the original modality into frequency images and periodicity images for visual learning. Also, we augment descriptive texts for the traffic signals based on the specific topic, background information and item description for textual learning. To complement the numeric information, we utilize frequency multilayer perceptrons for learning on the original modality. We design a hierarchical contrastive learning on the three branches to fuse the spectrum of three modalities. Finally, extensive experiments on six real-world datasets demonstrate superior performance compared with the state-of-the-art approaches.
Reward-Driven Interaction: Enhancing Proactive Dialogue Agents through User Satisfaction Prediction
May 24, 2025Reward-driven proactive dialogue agents require precise estimation of user satisfaction as an intrinsic reward signal to determine optimal interaction strategies. Specifically, this framework triggers clarification questions when detecting potential user dissatisfaction during interactions in the industrial dialogue system. Traditional works typically rely on training a neural network model based on weak labels which are generated by a simple model trained on user actions after current turn. However, existing methods suffer from two critical limitations in real-world scenarios: (1) Noisy Reward Supervision, dependence on weak labels derived from post-hoc user actions introduces bias, particularly failing to capture satisfaction signals in ASR-error-induced utterances; (2) Long-Tail Feedback Sparsity, the power-law distribution of user queries causes reward prediction accuracy to drop in low-frequency domains. The noise in the weak labels and a power-law distribution of user utterances results in that the model is hard to learn good representation of user utterances and sessions. To address these limitations, we propose two auxiliary tasks to improve the representation learning of user utterances and sessions that enhance user satisfaction prediction. The first one is a contrastive self-supervised learning task, which helps the model learn the representation of rare user utterances and identify ASR errors. The second one is a domain-intent classification task, which aids the model in learning the representation of user sessions from long-tailed domains and improving the model's performance on such domains. The proposed method is evaluated on DuerOS, demonstrating significant improvements in the accuracy of error recognition on rare user utterances and long-tailed domains.
Defense Against Model Stealing Based on Account-Aware Distribution Discrepancy
Mar 16, 2025



Malicious users attempt to replicate commercial models functionally at low cost by training a clone model with query responses. It is challenging to timely prevent such model-stealing attacks to achieve strong protection and maintain utility. In this paper, we propose a novel non-parametric detector called Account-aware Distribution Discrepancy (ADD) to recognize queries from malicious users by leveraging account-wise local dependency. We formulate each class as a Multivariate Normal distribution (MVN) in the feature space and measure the malicious score as the sum of weighted class-wise distribution discrepancy. The ADD detector is combined with random-based prediction poisoning to yield a plug-and-play defense module named D-ADD for image classification models. Results of extensive experimental studies show that D-ADD achieves strong defense against different types of attacks with little interference in serving benign users for both soft and hard-label settings.
DapperFL: Domain Adaptive Federated Learning with Model Fusion Pruning for Edge Devices
Dec 08, 2024Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data. In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a realworld FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to 2.28%, while significantly achieving model volume reductions ranging from 20% to 80%. Our code is available at: https://github.com/jyzgh/DapperFL.
Looking From the Future: Multi-order Iterations Can Enhance Adversarial Attack Transferability
Jul 02, 2024



Various methods try to enhance adversarial transferability by improving the generalization from different perspectives. In this paper, we rethink the optimization process and propose a novel sequence optimization concept, which is named Looking From the Future (LFF). LFF makes use of the original optimization process to refine the very first local optimization choice. Adapting the LFF concept to the adversarial attack task, we further propose an LFF attack as well as an MLFF attack with better generalization ability. Furthermore, guiding with the LFF concept, we propose an $LLF^{\mathcal{N}}$ attack which entends the LFF attack to a multi-order attack, further enhancing the transfer attack ability. All our proposed methods can be directly applied to the iteration-based attack methods. We evaluate our proposed method on the ImageNet1k dataset by applying several SOTA adversarial attack methods under four kinds of tasks. Experimental results show that our proposed method can greatly enhance the attack transferability. Ablation experiments are also applied to verify the effectiveness of each component. The source code will be released after this paper is accepted.
FedLPS: Heterogeneous Federated Learning for Multiple Tasks with Local Parameter Sharing
Feb 13, 2024Federated Learning (FL) has emerged as a promising solution in Edge Computing (EC) environments to process the proliferation of data generated by edge devices. By collaboratively optimizing the global machine learning models on distributed edge devices, FL circumvents the need for transmitting raw data and enhances user privacy. Despite practical successes, FL still confronts significant challenges including constrained edge device resources, multiple tasks deployment, and data heterogeneity. However, existing studies focus on mitigating the FL training costs of each single task whereas neglecting the resource consumption across multiple tasks in heterogeneous FL scenarios. In this paper, we propose Heterogeneous Federated Learning with Local Parameter Sharing (FedLPS) to fill this gap. FedLPS leverages principles from transfer learning to facilitate the deployment of multiple tasks on a single device by dividing the local model into a shareable encoder and task-specific encoders. To further reduce resource consumption, a channel-wise model pruning algorithm that shrinks the footprint of local models while accounting for both data and system heterogeneity is employed in FedLPS. Additionally, a novel heterogeneous model aggregation algorithm is proposed to aggregate the heterogeneous predictors in FedLPS. We implemented the proposed FedLPS on a real FL platform and compared it with state-of-the-art (SOTA) FL frameworks. The experimental results on five popular datasets and two modern DNN models illustrate that the proposed FedLPS significantly outperforms the SOTA FL frameworks by up to 4.88% and reduces the computational resource consumption by 21.3%. Our code is available at:https://github.com/jyzgh/FedLPS.
Adaptive Hypergraph Network for Trust Prediction
Feb 07, 2024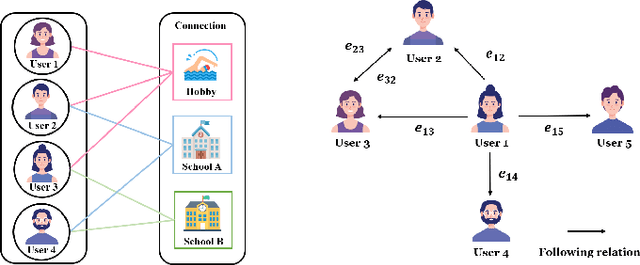
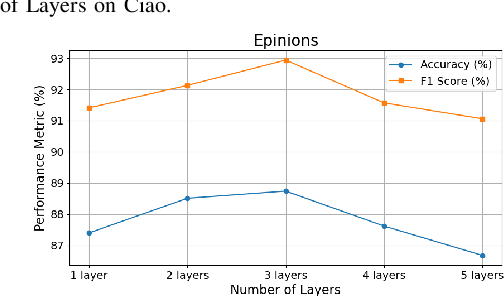
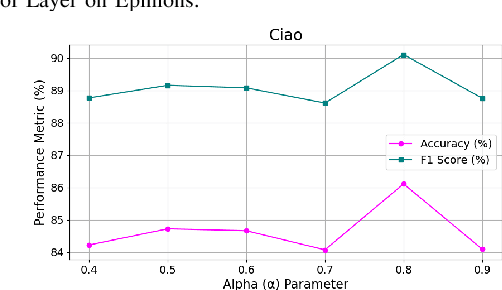
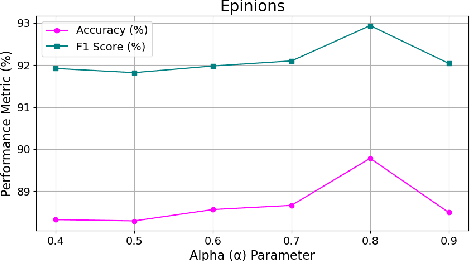
Trust plays an essential role in an individual's decision-making. Traditional trust prediction models rely on pairwise correlations to infer potential relationships between users. However, in the real world, interactions between users are usually complicated rather than pairwise only. Hypergraphs offer a flexible approach to modeling these complex high-order correlations (not just pairwise connections), since hypergraphs can leverage hyperedeges to link more than two nodes. However, most hypergraph-based methods are generic and cannot be well applied to the trust prediction task. In this paper, we propose an Adaptive Hypergraph Network for Trust Prediction (AHNTP), a novel approach that improves trust prediction accuracy by using higher-order correlations. AHNTP utilizes Motif-based PageRank to capture high-order social influence information. In addition, it constructs hypergroups from both node-level and structure-level attributes to incorporate complex correlation information. Furthermore, AHNTP leverages adaptive hypergraph Graph Convolutional Network (GCN) layers and multilayer perceptrons (MLPs) to generate comprehensive user embeddings, facilitating trust relationship prediction. To enhance model generalization and robustness, we introduce a novel supervised contrastive learning loss for optimization. Extensive experiments demonstrate the superiority of our model over the state-of-the-art approaches in terms of trust prediction accuracy. The source code of this work can be accessed via https://github.com/Sherry-XU1995/AHNTP.
CETN: Contrast-enhanced Through Network for CTR Prediction
Dec 15, 2023Click-through rate (CTR) Prediction is a crucial task in personalized information retrievals, such as industrial recommender systems, online advertising, and web search. Most existing CTR Prediction models utilize explicit feature interactions to overcome the performance bottleneck of implicit feature interactions. Hence, deep CTR models based on parallel structures (e.g., DCN, FinalMLP, xDeepFM) have been proposed to obtain joint information from different semantic spaces. However, these parallel subcomponents lack effective supervisory signals, making it challenging to efficiently capture valuable multi-views feature interaction information in different semantic spaces. To address this issue, we propose a simple yet effective novel CTR model: Contrast-enhanced Through Network for CTR (CETN), so as to ensure the diversity and homogeneity of feature interaction information. Specifically, CETN employs product-based feature interactions and the augmentation (perturbation) concept from contrastive learning to segment different semantic spaces, each with distinct activation functions. This improves diversity in the feature interaction information captured by the model. Additionally, we introduce self-supervised signals and through connection within each semantic space to ensure the homogeneity of the captured feature interaction information. The experiments and research conducted on four real datasets demonstrate that our model consistently outperforms twenty baseline models in terms of AUC and Logloss.
OptIForest: Optimal Isolation Forest for Anomaly Detection
Jun 23, 2023
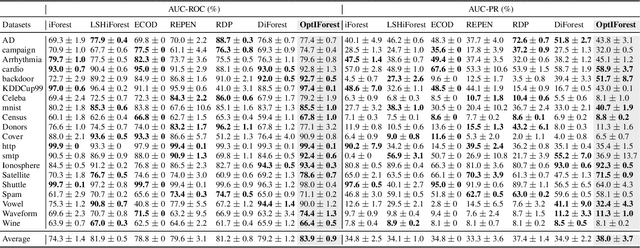
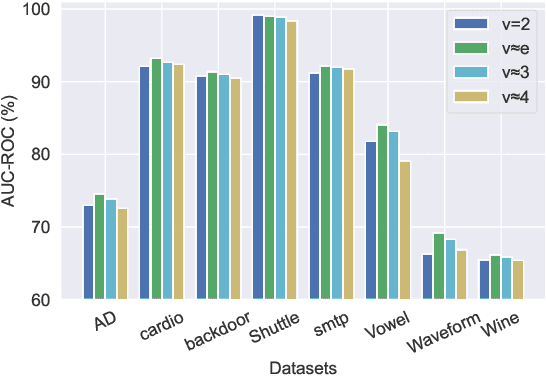
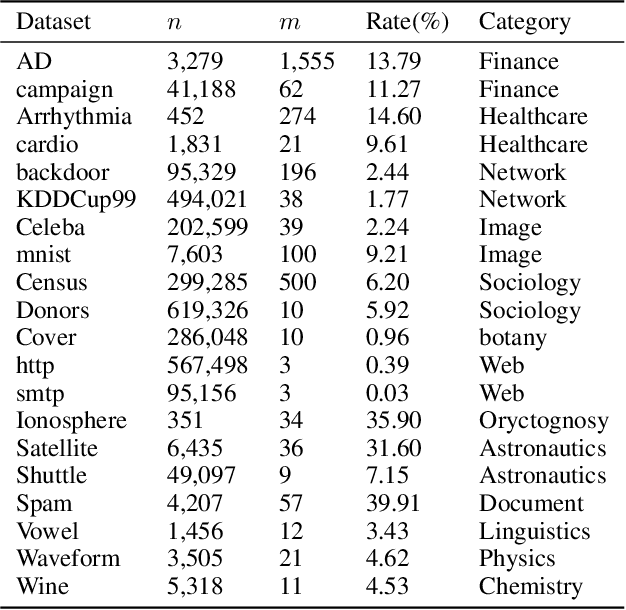
Anomaly detection plays an increasingly important role in various fields for critical tasks such as intrusion detection in cybersecurity, financial risk detection, and human health monitoring. A variety of anomaly detection methods have been proposed, and a category based on the isolation forest mechanism stands out due to its simplicity, effectiveness, and efficiency, e.g., iForest is often employed as a state-of-the-art detector for real deployment. While the majority of isolation forests use the binary structure, a framework LSHiForest has demonstrated that the multi-fork isolation tree structure can lead to better detection performance. However, there is no theoretical work answering the fundamentally and practically important question on the optimal tree structure for an isolation forest with respect to the branching factor. In this paper, we establish a theory on isolation efficiency to answer the question and determine the optimal branching factor for an isolation tree. Based on the theoretical underpinning, we design a practical optimal isolation forest OptIForest incorporating clustering based learning to hash which enables more information to be learned from data for better isolation quality. The rationale of our approach relies on a better bias-variance trade-off achieved by bias reduction in OptIForest. Extensive experiments on a series of benchmarking datasets for comparative and ablation studies demonstrate that our approach can efficiently and robustly achieve better detection performance in general than the state-of-the-arts including the deep learning based methods.