 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoCov: Semi-Orthogonal Parametric Pooling of Covariance Matrix for Speaker Recognition
Apr 23, 2025In conventional deep speaker embedding frameworks, the pooling layer aggregates all frame-level features over time and computes their mean and standard deviation statistics as inputs to subsequent segment-level layers. Such statistics pooling strategy produces fixed-length representations from variable-length speech segments. However, this method treats different frame-level features equally and discards covariance information. In this paper, we propose the Semi-orthogonal parameter pooling of Covariance matrix (SoCov) method. The SoCov pooling computes the covariance matrix from the self-attentive frame-level features and compresses it into a vector using the semi-orthogonal parametric vectorization, which is then concatenated with the weighted standard deviation vector to form inputs to the segment-level layers. Deep embedding based on SoCov is called ``sc-vector''. The proposed sc-vector is compared to several different baselines on the SRE21 development and evaluation sets. The sc-vector system significantly outperforms the conventional x-vector system, with a relative reduction in EER of 15.5% on SRE21Eval. When using self-attentive deep feature, SoCov helps to reduce EER on SRE21Eval by about 30.9% relatively to the conventional ``mean + standard deviation'' statistics.
Defense Against Model Stealing Based on Account-Aware Distribution Discrepancy
Mar 16, 2025



Malicious users attempt to replicate commercial models functionally at low cost by training a clone model with query responses. It is challenging to timely prevent such model-stealing attacks to achieve strong protection and maintain utility. In this paper, we propose a novel non-parametric detector called Account-aware Distribution Discrepancy (ADD) to recognize queries from malicious users by leveraging account-wise local dependency. We formulate each class as a Multivariate Normal distribution (MVN) in the feature space and measure the malicious score as the sum of weighted class-wise distribution discrepancy. The ADD detector is combined with random-based prediction poisoning to yield a plug-and-play defense module named D-ADD for image classification models. Results of extensive experimental studies show that D-ADD achieves strong defense against different types of attacks with little interference in serving benign users for both soft and hard-label settings.
A CT Image Denoising Method Based on Projection Domain Feature
Dec 09, 2024In order to improve image quality of projection in industrial applications, generally, a standard method is to increase the current or exposure time, which might cause overexposure of detector units in areas of thin objects or backgrounds. Increasing the projection sampling is a better method to address the issue, but it also leads to significant noise in the reconstructed image. This paper proposed a projection domain denoising algorithm based on the features of the projection domain for this case. This algorithm utilized the similarity of projections of neighboring veiws to reduce image noise quickly and effectively. The availability of the algorithm proposed in this work has been conducted by numerical simulation and practical data experiments.
Multi-Scale Temporal Transformer For Speech Emotion Recognition
Oct 01, 2024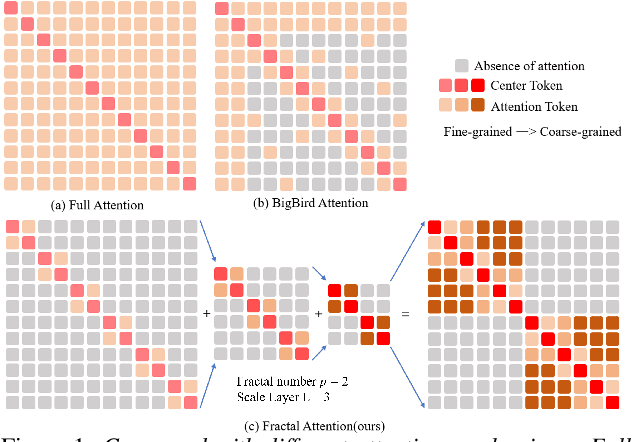
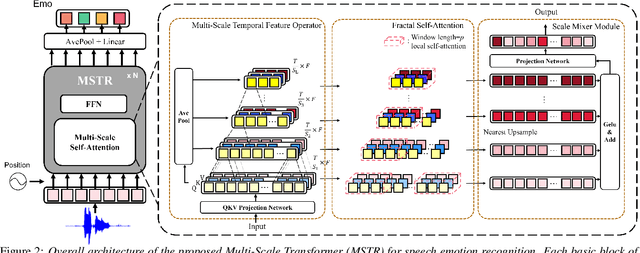
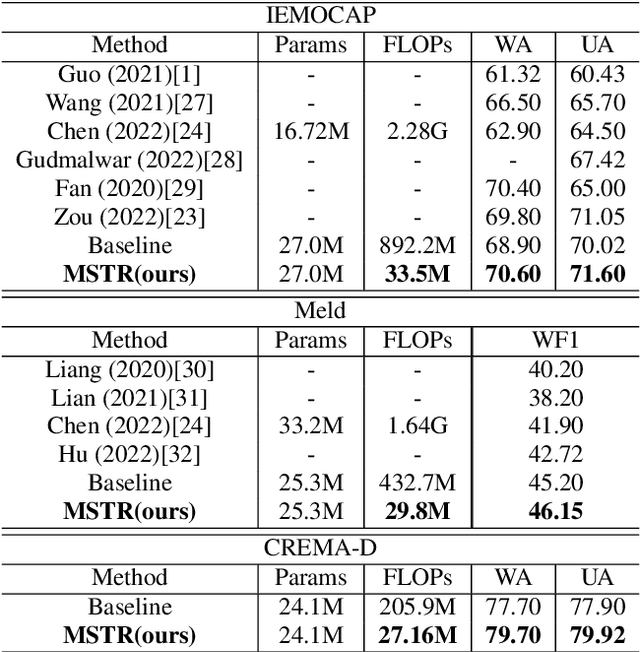
Speech emotion recognition plays a crucial role in human-machine interaction systems. Recently various optimized Transformers have been successfully applied to speech emotion recognition. However, the existing Transformer architectures focus more on global information and require large computation. On the other hand, abundant speech emotional representations exist locally on different parts of the input speech. To tackle these problems, we propose a Multi-Scale TRansfomer (MSTR) for speech emotion recognition. It comprises of three main components: (1) a multi-scale temporal feature operator, (2) a fractal self-attention module, and (3) a scale mixer module. These three components can effectively enhance the transformer's ability to learn multi-scale local emotion representations. Experimental results demonstrate that the proposed MSTR model significantly outperforms a vanilla Transformer and other state-of-the-art methods across three speech emotion datasets: IEMOCAP, MELD and, CREMAD. In addition, it can greatly reduce the computational cost.
An inspection technology of inner surface of the fine hole based on machine vision
Sep 15, 2023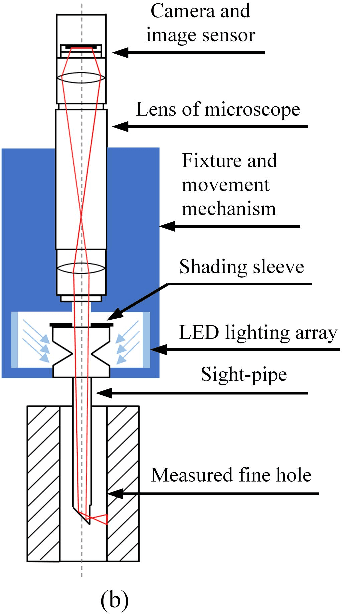
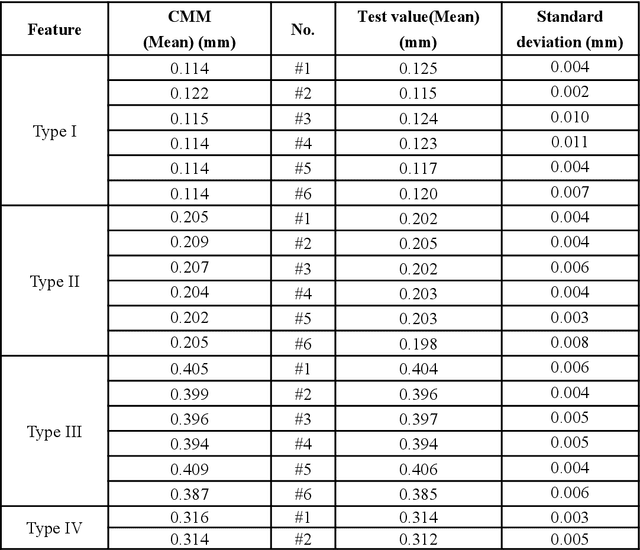
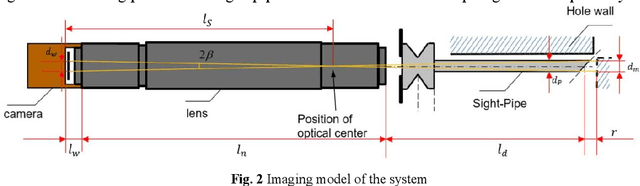
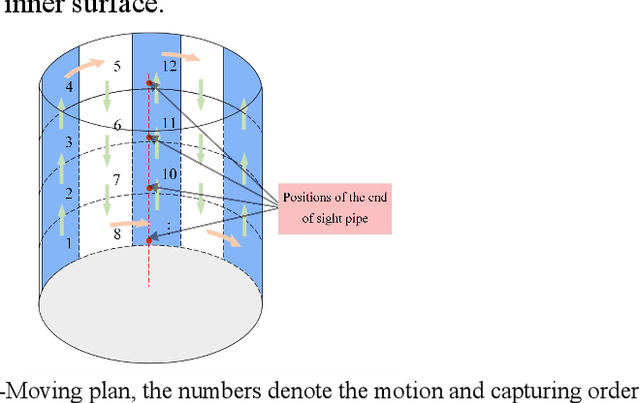
Fine holes are an important structural component of industrial components, and their inner surface quality is closely related to their function.In order to detect the quality of the inner surface of the fine hole,a special optical measurement system was investigated in this paper. A sight pipe is employed to guide the external illumination light into the fine hole and output the relevant images simultaneously. A flexible light array is introduced to suit the narrow space, and the effective field of view is analyzed. Besides, the arc surface projection error and manufacturing assembly error of the device are analyzed, then compensated or ignored if small enough. In the test of prefabricated circular defects with the diameter {\phi}0.1mm, {\phi}0.2mm, 0.4mm distance distribution and the fissure defects with the width 0.3mm, the maximum measurement error standard deviation are all about 10{\mu}m. The minimum diameter of the measured fine hole is 4mm and the depth can reach 47mm.
DWFormer: Dynamic Window transFormer for Speech Emotion Recognition
Mar 03, 2023Speech emotion recognition is crucial to human-computer interaction. The temporal regions that represent different emotions scatter in different parts of the speech locally. Moreover, the temporal scales of important information may vary over a large range within and across speech segments. Although transformer-based models have made progress in this field, the existing models could not precisely locate important regions at different temporal scales. To address the issue, we propose Dynamic Window transFormer (DWFormer), a new architecture that leverages temporal importance by dynamically splitting samples into windows. Self-attention mechanism is applied within windows for capturing temporal important information locally in a fine-grained way. Cross-window information interaction is also taken into account for global communication. DWFormer is evaluated on both the IEMOCAP and the MELD datasets. Experimental results show that the proposed model achieves better performance than the previous state-of-the-art methods.
The CORAL++ Algorithm for Unsupervised Domain Adaptation of Speaker Recogntion
Feb 02, 2022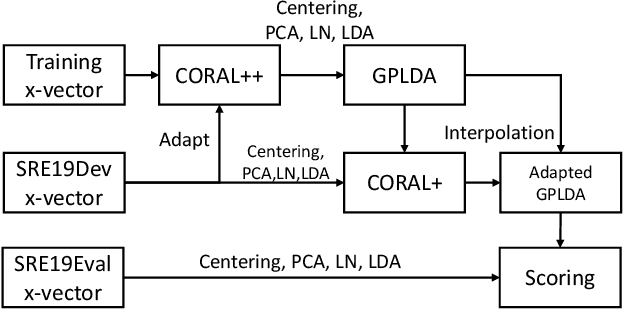


State-of-the-art speaker recognition systems are trained with a large amount of human-labeled training data set. Such a training set is usually composed of various data sources to enhance the modeling capability of models. However, in practical deployment, unseen condition is almost inevitable. Domain mismatch is a common problem in real-life applications due to the statistical difference between the training and testing data sets. To alleviate the degradation caused by domain mismatch, we propose a new feature-based unsupervised domain adaptation algorithm. The algorithm we propose is a further optimization based on the well-known CORrelation ALignment (CORAL), so we call it CORAL++. On the NIST 2019 Speaker Recognition Evaluation (SRE19), we use SRE18 CTS set as the development set to verify the effectiveness of CORAL++. With the typical x-vector/PLDA setup, the CORAL++ outperforms the CORAL by 9.40% relatively on EER.
Internal language model estimation through explicit context vector learning for attention-based encoder-decoder ASR
Jan 26, 2022
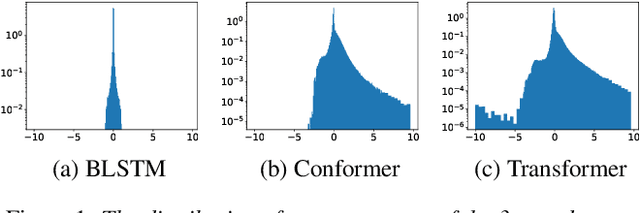
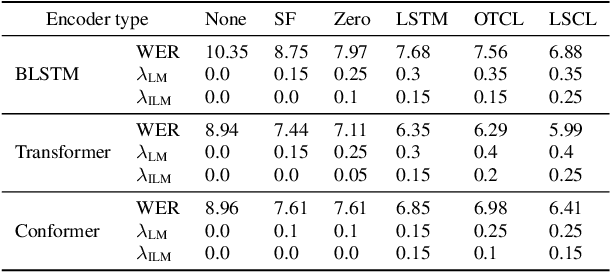

An end-to-end (E2E) speech recognition model implicitly learns a biased internal language model (ILM) during training. To fused an external LM during inference, the scores produced by the biased ILM need to be estimated and subtracted. In this paper we propose two novel approaches to estimate the biased ILM based on Listen-Attend-Spell (LAS) models. The simpler method is to replace the context vector of the LAS decoder at every time step with a learnable vector. The other more advanced method is to use a simple feed-forward network to directly map query vectors to context vectors, making the generation of the context vectors independent of the LAS encoder. Both the learnable vector and the mapping network are trained on the transcriptions of the training data to minimize the perplexity while all the other parameters of the LAS model is fixed. Experiments show that the ILMs estimated by the proposed methods achieve the lowest perplexity. In addition, they also significantly outperform the shallow fusion method and two previously proposed Internal Language Model Estimation (ILME) approaches on multiple datasets.
Estimation of Covariance Matrix of Interference for Secure Spatial Modulation against a Malicious Full-duplex Attacker
Oct 21, 2021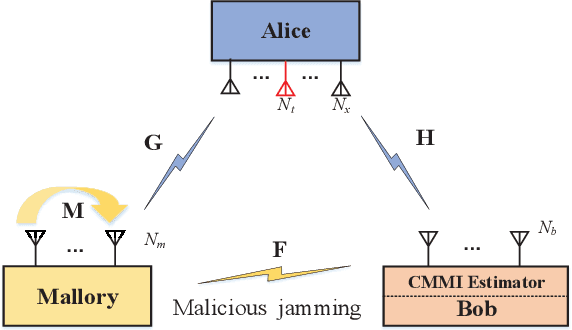
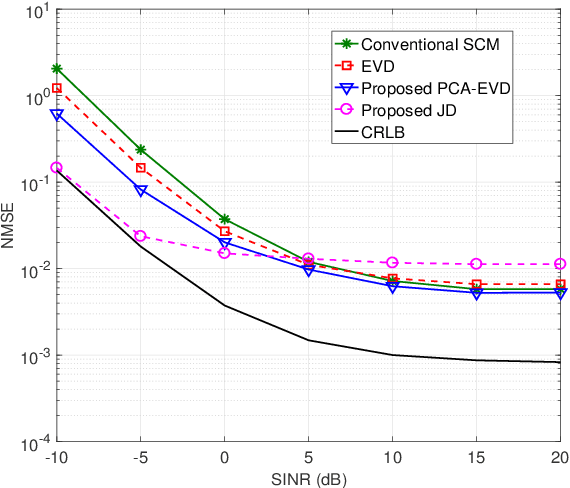
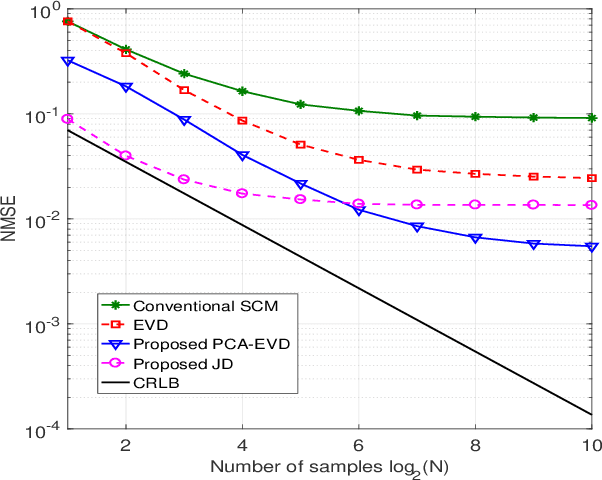
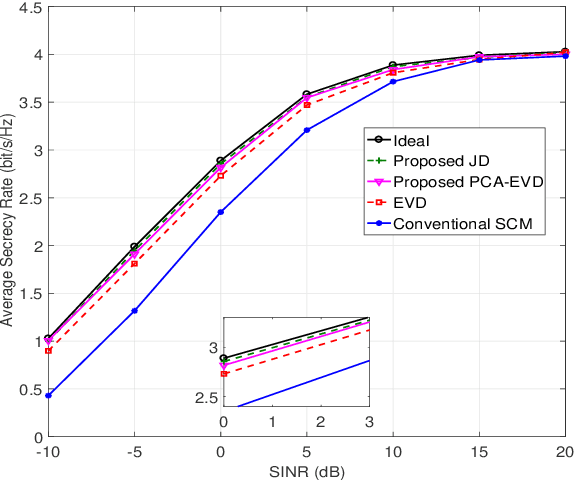
In a secure spatial modulation with a malicious full-duplex attacker, how to obtain the interference space or channel state information (CSI) is very important for Bob to cancel or reduce the interference from Mallory. In this paper, different from existing work with a perfect CSI, the covariance matrix of malicious interference (CMMI) from Mallory is estimated and is used to construct the null-space of interference (NSI). Finally, the receive beamformer at Bob is designed to remove the malicious interference using the NSI. To improve the estimation accuracy, a rank detector relying on Akaike information criterion (AIC) is derived. To achieve a high-precision CMMI estimation, two methods are proposed as follows: principal component analysis-eigenvalue decomposition (PCA-EVD), and joint diagonalization (JD). The proposed PCA-EVD is a rank deduction method whereas the JD method is a joint optimization method with improved performance in low signal to interference plus noise ratio (SINR) region at the expense of increased complexities. Simulation results show that the proposed PCA-EVD performs much better than the existing method like sample estimated covariance matrix (SCM) and EVD in terms of normalized mean square error (NMSE) and secrecy rate (SR). Additionally, the proposed JD method has an excellent NMSE performance better than PCA-EVD in the low SINR region (SINR < 0dB) while in the high SINR region PCA-EVD performs better than JD.
Multi-head Monotonic Chunkwise Attention For Online Speech Recognition
May 01, 2020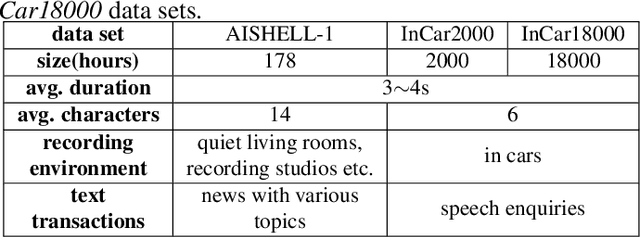
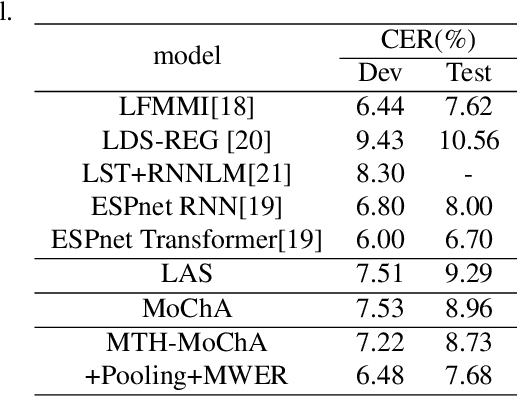
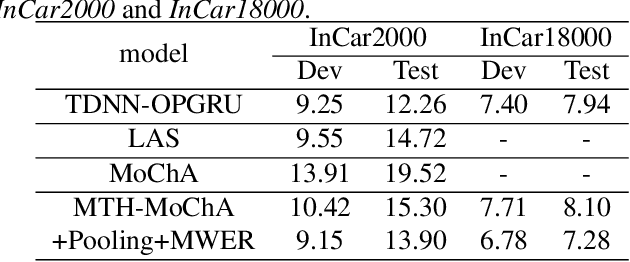
The attention mechanism of the Listen, Attend and Spell (LAS) model requires the whole input sequence to calculate the attention context and thus is not suitable for online speech recognition. To deal with this problem, we propose multi-head monotonic chunk-wise attention (MTH-MoChA), an improved version of MoChA. MTH-MoChA splits the input sequence into small chunks and computes multi-head attentions over the chunks. We also explore useful training strategies such as LSTM pooling, minimum world error rate training and SpecAugment to further improve the performance of MTH-MoChA. Experiments on AISHELL-1 data show that the proposed model, along with the training strategies, improve the character error rate (CER) of MoChA from 8.96% to 7.68% on test set. On another 18000 hours in-car speech data set, MTH-MoChA obtains 7.28% CER, which is significantly better than a state-of-the-art hybrid system.